
Esta página lista um conjunto de guias e ferramentas conhecidos que resolvem problemas no domínio de texto com o TensorFlow Hub. É um ponto de partida para quem deseja resolver problemas típicos de ML usando componentes de ML pré-treinados, em vez de começar do zero.
Classificação
Quando queremos prever uma classe para um determinado exemplo, por exemplo , sentimento , toxicidade , categoria de artigo ou qualquer outra característica.

Os tutoriais abaixo resolvem a mesma tarefa de diferentes perspectivas e usando ferramentas diferentes.
Keras
Classificação de texto com Keras - exemplo para construir um classificador de sentimento IMDB com conjuntos de dados Keras e TensorFlow.
Estimador
Classificação de texto - exemplo para construir um classificador de sentimento IMDB com Estimator. Contém várias dicas para melhorias e uma seção de comparação de módulos.
BERTO
Prevendo o sentimento da crítica do filme com BERT no TF Hub - mostra como usar um módulo BERT para classificação. Inclui o uso da biblioteca bert para tokenização e pré-processamento.
Kaggle
Classificação IMDB no Kaggle - mostra como interagir facilmente com uma competição Kaggle de um Colab, incluindo o download dos dados e o envio dos resultados.
| Estimador | Keras | TF2 | Conjuntos de dados TF | BERTO | API Kaggle | |
|---|---|---|---|---|---|---|
| Classificação de texto | ||||||
| Classificação de texto com Keras | ||||||
| Prevendo o sentimento da crítica do filme com BERT no TF Hub | ||||||
| Classificação IMDB no Kaggle |
Tarefa Bangla com incorporações FastText
Atualmente, o TensorFlow Hub não oferece um módulo em todos os idiomas. O tutorial a seguir mostra como aproveitar o TensorFlow Hub para experimentação rápida e desenvolvimento modular de ML.
Classificador de artigos Bangla - demonstra como criar uma incorporação de texto reutilizável do TensorFlow Hub e usá-la para treinar um classificador Keras para o conjunto de dados de artigos BARD Bangla .
Semelhança semântica
Quando queremos descobrir quais sentenças se correlacionam entre si na configuração zero-shot (sem exemplos de treinamento).
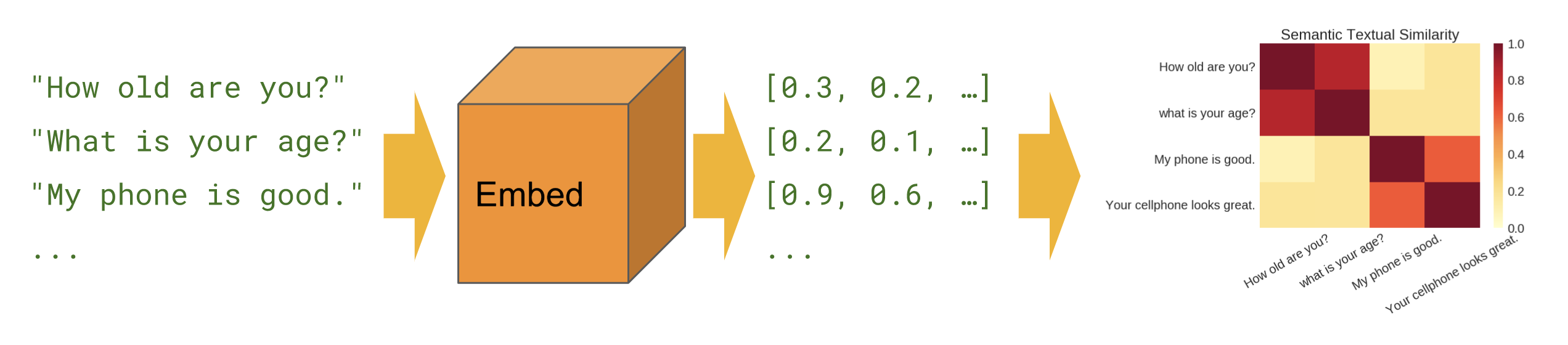
Básico
Similaridade semântica - mostra como usar o módulo codificador de frases para calcular a similaridade de frases.
Multilíngue
Similaridade semântica multilíngue - mostra como usar um dos codificadores de sentenças multilíngues para calcular a similaridade de sentenças entre idiomas.
Recuperação semântica
Recuperação semântica - mostra como usar o codificador de sentença Q/A para indexar uma coleção de documentos para recuperação com base na similaridade semântica.
Entrada de peça de frase
Similaridade semântica com o codificador universal lite - mostra como usar módulos codificadores de frases que aceitam ids de SentencePiece na entrada em vez de texto.
Criação de módulo
Em vez de usar apenas módulos em tfhub.dev , existem maneiras de criar módulos próprios. Esta pode ser uma ferramenta útil para melhor modularidade da base de código de ML e para maior compartilhamento.
Envolvendo embeddings pré-treinados existentes
Exportador de módulo de incorporação de texto - uma ferramenta para agrupar uma incorporação pré-treinada existente em um módulo. Mostra como incluir operações de pré-processamento de texto no módulo. Isso permite criar um módulo de incorporação de frases a partir de incorporações de tokens.
Exportador de módulo de incorporação de texto v2 - igual ao acima, mas compatível com TensorFlow 2 e execução rápida.