
Na tej stronie znajduje się lista znanych przewodników i narzędzi rozwiązujących problemy w domenie tekstowej za pomocą TensorFlow Hub. Jest to miejsce startowe dla każdego, kto chce rozwiązać typowe problemy ML przy użyciu wstępnie przeszkolonych komponentów ML, zamiast zaczynać od zera.
Klasyfikacja
Gdy chcemy przewidzieć klasę dla danego przykładu, na przykład sentyment , toksyczność , kategoria artykułu lub inna cecha.

Poniższe samouczki rozwiązują to samo zadanie z różnych perspektyw i przy użyciu różnych narzędzi.
Kerasa
Klasyfikacja tekstu za pomocą Keras — przykład budowania klasyfikatora tonacji IMDB za pomocą zestawów danych Keras i TensorFlow.
Taksator
Klasyfikacja tekstu - przykład budowania klasyfikatora tonacji IMDB za pomocą Estimatora. Zawiera wiele wskazówek dotyczących ulepszeń i sekcję porównującą moduły.
BERT
Przewidywanie nastrojów w recenzjach filmów za pomocą BERT w TF Hub - pokazuje, jak używać modułu BERT do klasyfikacji. Obejmuje wykorzystanie biblioteki bert do tokenizacji i wstępnego przetwarzania.
Kaggle
Klasyfikacja IMDB w Kaggle - pokazuje, jak łatwo wchodzić w interakcję z konkursami Kaggle z Colab, w tym pobierać dane i przesyłać wyniki.
| Taksator | Kerasa | TF2 | Zbiory danych TF | BERT | Interfejsy API Kaggle | |
|---|---|---|---|---|---|---|
| Klasyfikacja tekstu | ||||||
| Klasyfikacja tekstu za pomocą Keras | ||||||
| Przewidywanie nastrojów w recenzjach filmów za pomocą BERT w TF Hub | ||||||
| Klasyfikacja IMDB na Kaggle |
Zadanie Bangla z osadzeniem FastText
TensorFlow Hub nie oferuje obecnie modułu w każdym języku. Poniższy samouczek pokazuje, jak wykorzystać centrum TensorFlow do szybkiego eksperymentowania i modułowego programowania uczenia maszynowego.
Klasyfikator artykułów Bangla — pokazuje, jak utworzyć osadzanie tekstu TensorFlow Hub wielokrotnego użytku i używać go do uczenia klasyfikatora Keras dla zestawu danych artykułów BARD Bangla .
Podobieństwo semantyczne
Kiedy chcemy dowiedzieć się, które zdania korelują ze sobą w konfiguracji zerowej (bez przykładów szkoleniowych).
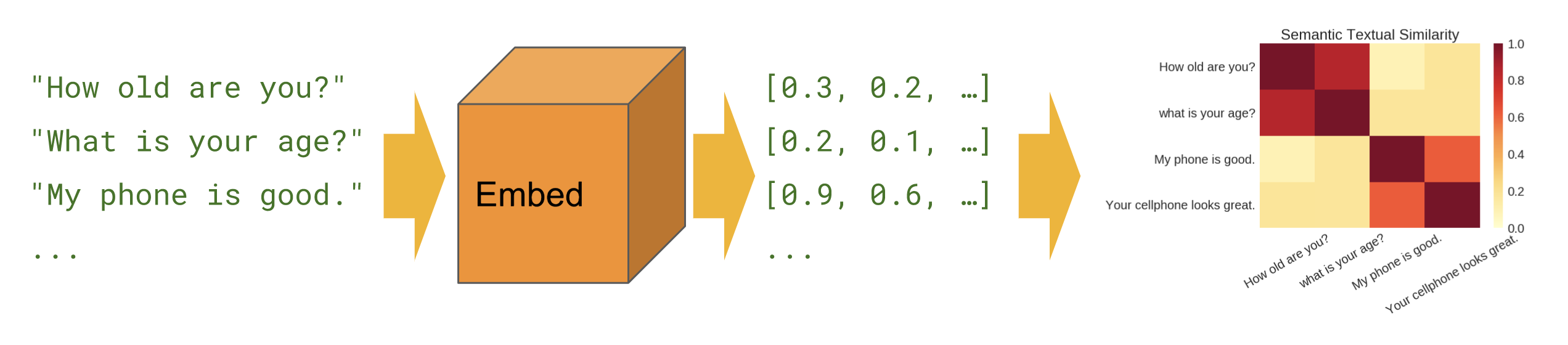
Podstawowy
Podobieństwo semantyczne - pokazuje, jak używać modułu kodera zdań do obliczania podobieństwa zdań.
Międzyjęzykowy
Międzyjęzykowe podobieństwo semantyczne — pokazuje, jak używać jednego z międzyjęzycznych koderów zdań do obliczania podobieństwa zdań w różnych językach.
Odzyskiwanie semantyczne
Pobieranie semantyczne — pokazuje, jak używać kodera zdań pytań i odpowiedzi do indeksowania zbioru dokumentów do pobrania w oparciu o podobieństwo semantyczne.
Wejście fragmentu zdania
Podobieństwo semantyczne z uniwersalnym koderem Lite - pokazuje, jak używać modułów kodera zdań, które akceptują identyfikatory SentencePiece na wejściu zamiast tekstu.
Tworzenie modułu
Zamiast używać tylko modułów na tfhub.dev , istnieją sposoby na tworzenie własnych modułów. Może to być przydatne narzędzie do lepszej modułowości bazy kodu ML i dalszego udostępniania.
Zawijanie istniejących, wstępnie wyszkolonych elementów osadzonych
Eksport modułu osadzania tekstu - narzędzie do owijania istniejącego, wstępnie wytrenowanego osadzania w moduł. Pokazuje, jak dołączyć do modułu operacje wstępnego przetwarzania tekstu. Pozwala to na utworzenie modułu osadzania zdań z osadzania tokenów.
Eksport modułu osadzania tekstu v2 - taki sam jak powyżej, ale kompatybilny z TensorFlow 2 i chętną realizacją.