
このページでは、TensorFlow Hub を使ってテキスト分野の問題を解決する既知のガイドやツールの一覧を提供しています。典型的な ML の問題をゼロからではなく、トレーニング済みの ML コンポーネントを使って解決しようとしているユーザーの出発点としてご利用ください。
分類
特定の例のクラスを予測する場合、特にセンチメント、毒性、記事カテゴリ、またはその他の特性を予測する場合。

以下のチュートリアルでは、同一のタスクを異なるツールを使ってさまざまな観点から解決しています。
Keras
Keras によるテキスト分類 - Keras と TensorFlow の Dataset を使用して IMDB のセンチメント分類器を構築する例。
Estimator
Text classification(テキスト分類)- Estimator を使用して IMDB のセンチメント分類器を構築する例。改善に関するさまざまなヒントやモジュールの比較セクションが含まれます。
BERT
TF Hub の BERT による映画レビューのセンチメントの予測 - BERT モジュールを使用して分類を行う方法が紹介されています。トークン化と前処理を行うための bert ライブラリの使用方法が含まれます。
Kaggle
Kaggle での IMDB 分類 - データのダウンロードと結果の送信など、Colab から Kaggle コンペと簡単に連携する方法が示されています。
| Estimator | Keras | TF2 | TF Datasets | BERT | Kaggle APIs
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ----------- テキスト分類 | ![]() | | | | | Keras によるテキスト分類 | |
| | | | | Keras によるテキスト分類 | | ![]() |
| ![]() |
| ![]() | | TF Hub での BERT による映画レビューのセンチメント予測 |
| | TF Hub での BERT による映画レビューのセンチメント予測 | ![]() | | | |
| | | | ![]() | Kaggle での IMDB 分類 |
| Kaggle での IMDB 分類 | ![]() | | | | |
| | | | | ![]()
FastText 埋め込みによる Bangla タスク
現在のところ、TensorFlow Hub はモジュールをすべての言語で提供していません。次のチュートリアルでは、TensorFlow Hub を使用して高速実験とモジュール式 ML 開発を行う方法が示されています。
Bangla 記事分類器 - 再利用可能な TensorFlow Hub テキスト埋め込みを作成し、それを使用して BARD Bangla Article データセット用に Keras 分類器をトレーニングする方法を実演しています。
意味的類似性
ゼロショットセットアップ(トレーニングサンプルなしのセットアップ)で、どの文章が相関しているかを見つけ出す場合。
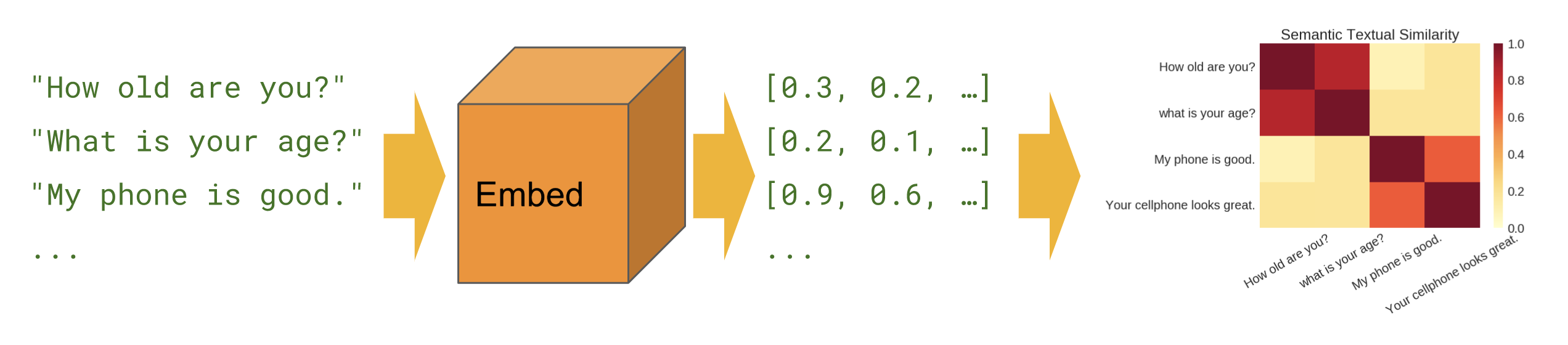
基本
意味的類似性 - 文章エンコーダモジュールを使用して文章の類似性を計算する方法を示します。
クロスリンガル
クロスリンガル意味的類似性 - クロスリンガル文章エンコーダの 1 つを使用して言語間の文章の類似性を計算する方法を示します。
セマンティック検索
セマンティック検索 - QA 文章エンコーダを使用して、意味的類似性に基づく検索を行えるように、ドキュメントコレクションのインデックスを作成する方法を示します。
SentencePiece 入力
ユニバーサルエンコーダー Lite による意味的類似性 - テキストの代わりに入力の SentencePiece id を受け付ける文章エンコーダモジュールの使用方法を示します。
モジュールの作成
tfhub.dev のモジュールのみを使用する代わりに、独自のモジュールを作成する方法があります。優れた ML コードベースモジュール性と以降での共有に有用なツールです。
既存のトレーニング済みの埋め込みをラッピングする
テキスト埋め込みモジュールエクスポータ - 既存のトレーニング済みの埋め込みをモジュールにラッピングするツールです。テキストの事前処理演算をモジュールに含める方法を示します。こうすることで、トークン埋め込みから文章埋め込みを作成することが可能となります。
テキスト埋め込みモジュールエクスポータ v2 - 上記と同じですが、TensorFlow 2 と Eager execution との互換性があります。