
Halaman ini mencantumkan serangkaian panduan dan alat yang dikenal untuk memecahkan masalah dalam domain teks dengan TensorFlow Hub. Ini adalah titik awal bagi siapa saja yang ingin memecahkan masalah umum ML menggunakan komponen ML yang telah dilatih sebelumnya, bukan memulai dari awal.
Klasifikasi
Saat kita ingin memprediksi suatu kelas untuk contoh tertentu, misalnya sentimen , toksisitas , kategori artikel , atau karakteristik lainnya.

Tutorial di bawah ini menyelesaikan tugas yang sama dari sudut pandang berbeda dan menggunakan alat berbeda.
keras
Klasifikasi teks dengan Keras - contoh untuk membuat pengklasifikasi sentimen IMDB dengan Kumpulan Data Keras dan TensorFlow.
Penaksir
Klasifikasi teks - contoh untuk membuat pengklasifikasi sentimen IMDB dengan Estimator. Berisi beberapa tips untuk perbaikan dan bagian perbandingan modul.
BERT
Memprediksi Sentimen Ulasan Film dengan BERT di TF Hub - menunjukkan cara menggunakan modul BERT untuk klasifikasi. Termasuk penggunaan perpustakaan bert untuk tokenisasi dan prapemrosesan.
Kaggle
Klasifikasi IMDB di Kaggle - menunjukkan cara mudah berinteraksi dengan kompetisi Kaggle dari Colab, termasuk mengunduh data dan mengirimkan hasilnya.
| Penaksir | keras | TF2 | Kumpulan Data TF | BERT | API Kaggle | |
|---|---|---|---|---|---|---|
| Klasifikasi teks | ||||||
| Klasifikasi teks dengan Keras | ||||||
| Memprediksi Sentimen Review Film dengan BERT di TF Hub | ||||||
| Klasifikasi IMDB di Kaggle |
Tugas Bangla dengan penyematan FastText
TensorFlow Hub saat ini tidak menawarkan modul dalam semua bahasa. Tutorial berikut menunjukkan cara memanfaatkan TensorFlow Hub untuk eksperimen cepat dan pengembangan ML modular.
Pengklasifikasi Artikel Bangla - mendemonstrasikan cara membuat penyematan teks TensorFlow Hub yang dapat digunakan kembali, dan menggunakannya untuk melatih pengklasifikasi Keras untuk kumpulan data Artikel BARD Bangla .
Kesamaan semantik
Saat kita ingin mengetahui kalimat mana yang berkorelasi satu sama lain dalam pengaturan zero-shot (tidak ada contoh pelatihan).
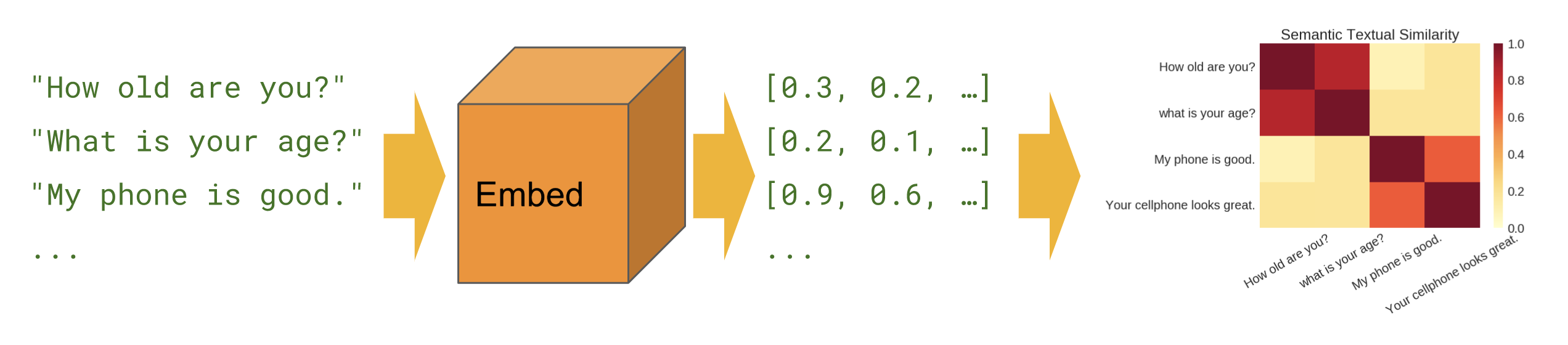
Dasar
Kesamaan semantik - menunjukkan cara menggunakan modul encoder kalimat untuk menghitung kesamaan kalimat.
Lintas bahasa
Kesamaan semantik lintas bahasa - menunjukkan cara menggunakan salah satu pembuat enkode kalimat lintas bahasa untuk menghitung kesamaan kalimat antar bahasa.
Pengambilan semantik
Pengambilan semantik - menunjukkan cara menggunakan encoder kalimat Q/A untuk mengindeks kumpulan dokumen untuk pengambilan berdasarkan kesamaan semantik.
Masukan Potongan Kalimat
Kemiripan semantik dengan universal encoder lite - menunjukkan cara menggunakan modul encoder kalimat yang menerima id SentencePiece pada input, bukan teks.
Pembuatan modul
Daripada hanya menggunakan modul di tfhub.dev , ada cara untuk membuat modul sendiri. Ini bisa menjadi alat yang berguna untuk modularitas basis kode ML yang lebih baik dan untuk berbagi lebih lanjut.
Membungkus embeddings terlatih yang sudah ada
Pengekspor modul penyematan teks - alat untuk menggabungkan penyematan terlatih yang sudah ada ke dalam sebuah modul. Menunjukkan cara memasukkan operasi pra-pemrosesan teks ke dalam modul. Hal ini memungkinkan untuk membuat modul penyematan kalimat dari penyematan token.
Pengekspor modul penyematan teks v2 - sama seperti di atas, tetapi kompatibel dengan TensorFlow 2 dan eksekusi yang bersemangat.