
Cette page répertorie un ensemble de guides et d'outils connus résolvant les problèmes dans le domaine du texte avec TensorFlow Hub. Il s'agit d'un point de départ pour quiconque souhaite résoudre des problèmes de ML typiques à l'aide de composants de ML pré-entraînés plutôt que de repartir de zéro.
Classification
Lorsque l'on souhaite prédire une classe pour un exemple donné, par exemple sentiment , toxicité , catégorie d'article ou toute autre caractéristique.

Les didacticiels ci-dessous résolvent la même tâche sous différents angles et en utilisant différents outils.
Kéras
Classification de texte avec Keras - exemple de création d'un classificateur de sentiments IMDB avec des ensembles de données Keras et TensorFlow.
Estimateur
Classification de texte - exemple de création d'un classificateur de sentiments IMDB avec Estimator. Contient plusieurs conseils d’amélioration et une section de comparaison de modules.
BERTE
Prédire le sentiment des critiques de films avec BERT sur TF Hub - montre comment utiliser un module BERT pour la classification. Comprend l'utilisation de la bibliothèque bert pour la tokenisation et le prétraitement.
Kaggle
Classification IMDB sur Kaggle - montre comment interagir facilement avec une compétition Kaggle à partir d'un Colab, y compris le téléchargement des données et la soumission des résultats.
| Estimateur | Kéras | TF2 | Ensembles de données TF | BERTE | API Kaggle | |
|---|---|---|---|---|---|---|
| Classement du texte | ||||||
| Classification de texte avec Keras | ||||||
| Prédire le sentiment des critiques de films avec BERT sur TF Hub | ||||||
| Classement IMDB sur Kaggle |
Tâche Bangla avec intégrations FastText
TensorFlow Hub ne propose actuellement pas de module dans chaque langue. Le didacticiel suivant montre comment exploiter TensorFlow Hub pour une expérimentation rapide et un développement de ML modulaire.
Bangla Article Classifier - montre comment créer une intégration de texte TensorFlow Hub réutilisable et l'utiliser pour former un classificateur Keras pour l'ensemble de données BARD Bangla Article .
Similitude sémantique
Lorsque nous voulons savoir quelles phrases sont en corrélation les unes avec les autres dans une configuration zéro-shot (pas d'exemples de formation).
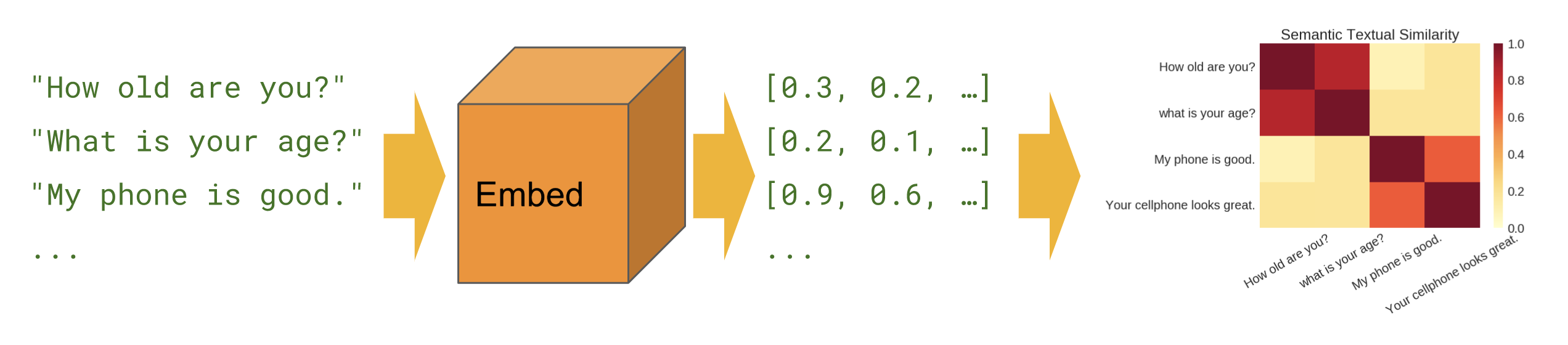
Basique
Similitude sémantique - montre comment utiliser le module d'encodeur de phrases pour calculer la similarité des phrases.
Multilingue
Similitude sémantique multilingue - montre comment utiliser l'un des encodeurs de phrases multilingues pour calculer la similarité des phrases entre les langues.
Récupération sémantique
Récupération sémantique - montre comment utiliser l'encodeur de phrases Q/A pour indexer une collection de documents en vue d'une récupération basée sur la similarité sémantique.
Entrée de morceau de phrase
Similitude sémantique avec Universal Encoder Lite - montre comment utiliser des modules d'encodeur de phrases qui acceptent les identifiants SentencePièce en entrée au lieu du texte.
Création de modules
Au lieu d'utiliser uniquement des modules sur tfhub.dev , il existe des moyens de créer vos propres modules. Cela peut être un outil utile pour une meilleure modularité de la base de code ML et pour un partage ultérieur.
Encapsulation des intégrations pré-entraînées existantes
Exportateur de module d'intégration de texte - un outil pour intégrer une intégration pré-entraînée existante dans un module. Montre comment inclure des opérations de prétraitement de texte dans le module. Cela permet de créer un module d'intégration de phrases à partir d'intégrations de jetons.
Exportateur de module d'intégration de texte v2 - identique à ci-dessus, mais compatible avec TensorFlow 2 et exécution rapide.