
تسرد هذه الصفحة مجموعة من الأدلة والأدوات المعروفة لحل المشكلات في مجال النص باستخدام TensorFlow Hub. إنها نقطة انطلاق لأي شخص يريد حل مشكلات تعلم الآلة النموذجية باستخدام مكونات تعلم الآلة المدربة مسبقًا بدلاً من البدء من الصفر.
تصنيف
عندما نريد التنبؤ بفئة لمثال معين، على سبيل المثال المشاعر ، أو السمية ، أو فئة المقالة ، أو أي خاصية أخرى.

تعمل البرامج التعليمية أدناه على حل نفس المهمة من وجهات نظر مختلفة وباستخدام أدوات مختلفة.
كيراس
تصنيف النص باستخدام Keras - مثال لإنشاء مصنف مشاعر IMDB باستخدام Keras وTensorFlow Datasets.
مقدر
تصنيف النص - مثال لإنشاء مصنف مشاعر IMDB باستخدام Estimator. يحتوي على نصائح متعددة للتحسين وقسم لمقارنة الوحدات.
بيرت
توقع مشاعر مراجعة الفيلم باستخدام BERT على TF Hub - يوضح كيفية استخدام وحدة BERT للتصنيف. يتضمن استخدام مكتبة bert للترميز والمعالجة المسبقة.
كاجل
تصنيف IMDB على Kaggle - يوضح كيفية التفاعل بسهولة مع مسابقة Kaggle من Colab، بما في ذلك تنزيل البيانات وإرسال النتائج.
| مقدر | كيراس | TF2 | مجموعات بيانات TF | بيرت | واجهات برمجة التطبيقات Kaggle | |
|---|---|---|---|---|---|---|
| تصنيف النص | ||||||
| تصنيف النص مع Keras | ||||||
| توقع مشاعر مراجعة الفيلم مع BERT على TF Hub | ||||||
| تصنيف IMDB على موقع Kaggle |
مهمة البنغالية مع تضمينات FastText
لا يقدم TensorFlow Hub حاليًا وحدة نمطية بكل اللغات. يوضح البرنامج التعليمي التالي كيفية الاستفادة من TensorFlow Hub لإجراء التجارب السريعة وتطوير تعلم الآلة المعياري.
Bangla Article Classifier - يوضح كيفية إنشاء نص TensorFlow Hub قابل لإعادة الاستخدام، واستخدامه لتدريب مصنف Keras لمجموعة بيانات BARD Bangla Article .
التشابه الدلالي
عندما نريد معرفة الجمل التي ترتبط ببعضها البعض في إعداد الصفر (لا توجد أمثلة تدريبية).
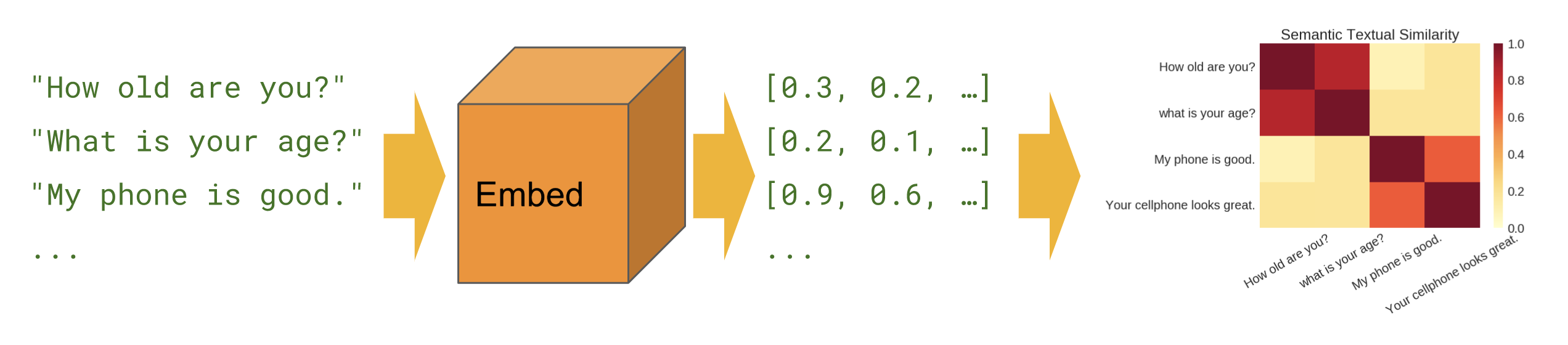
أساسي
التشابه الدلالي - يوضح كيفية استخدام وحدة تشفير الجملة لحساب تشابه الجملة.
متعدد اللغات
التشابه الدلالي عبر اللغات - يوضح كيفية استخدام أحد برامج تشفير الجملة عبر اللغات لحساب تشابه الجملة عبر اللغات.
الاسترجاع الدلالي
الاسترجاع الدلالي - يوضح كيفية استخدام برنامج ترميز جملة الأسئلة والأجوبة لفهرسة مجموعة من المستندات لاسترجاعها بناءً على التشابه الدلالي.
إدخال قطعة الجملة
التشابه الدلالي مع برنامج التشفير العالمي lite - يوضح كيفية استخدام وحدات تشفير الجملة التي تقبل معرفات SentencePiece عند الإدخال بدلاً من النص.
إنشاء الوحدة
بدلاً من استخدام الوحدات النمطية فقط على tfhub.dev ، هناك طرق لإنشاء وحدات نمطية خاصة. يمكن أن تكون هذه أداة مفيدة لتحسين نمطية قاعدة تعليمات ML ولمزيد من المشاركة.
التفاف التضمينات الموجودة مسبقاً المدربة
مصدر وحدة تضمين النص - أداة لتضمين عملية تضمين موجودة مسبقًا تم تدريبها في وحدة نمطية. يوضح كيفية تضمين عمليات المعالجة المسبقة للنص في الوحدة. يسمح هذا بإنشاء وحدة تضمين جملة من عمليات تضمين الرمز المميز.
وحدة تضمين النص المصدر v2 - كما هو مذكور أعلاه، ولكنها متوافقة مع TensorFlow 2 والتنفيذ المتحمس.