
| | |  GitHub এ দেখুন GitHub এ দেখুন | | |
এই নোটবুকটি ব্যাখ্যা করে যে কীভাবে ইউনিভার্সাল সেন্টেন্স এনকোডার অ্যাক্সেস করতে হয় এবং বাক্যের মিল এবং বাক্যের শ্রেণীবিভাগের কাজে এটি ব্যবহার করতে হয়।
ইউনিভার্সাল সেন্টেন্স এনকোডার বাক্যের স্তরের এম্বেডিংগুলিকে ততটাই সহজ করে তোলে যতটা ঐতিহাসিকভাবে পৃথক শব্দের জন্য এমবেডিংগুলি সন্ধান করা হয়েছে। বাক্য এমবেডিংগুলি তখন তুচ্ছভাবে বাক্য স্তরের গণনা করতে ব্যবহার করা যেতে পারে যার অর্থ সাদৃশ্য এবং সেইসাথে কম তত্ত্বাবধানে প্রশিক্ষণের ডেটা ব্যবহার করে ডাউনস্ট্রিম শ্রেণীবিভাগের কাজগুলিতে আরও ভাল পারফরম্যান্স সক্ষম করতে।
সেটআপ
এই বিভাগটি TF হাবের ইউনিভার্সাল সেন্টেন্স এনকোডারে অ্যাক্সেসের জন্য পরিবেশ সেট আপ করে এবং শব্দ, বাক্য এবং অনুচ্ছেদে এনকোডার প্রয়োগ করার উদাহরণ প্রদান করে।
%%capture
!pip3 install seaborn
ইনস্টল করার Tensorflow সম্পর্কে আরো বিস্তারিত তথ্য পাওয়া যাবে https://www.tensorflow.org/install/ ।
ইউনিভার্সাল সেন্টেন্স এনকোডারের TF হাব মডিউল লোড করুন
from absl import logging
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)
def embed(input):
return model(input)
module https://tfhub.dev/google/universal-sentence-encoder/4 loaded
প্রতিটি বার্তার জন্য একটি উপস্থাপনা গণনা করুন, বিভিন্ন দৈর্ঘ্য সমর্থিত দেখাচ্ছে।
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]
# Reduce logging output.
logging.set_verbosity(logging.ERROR)
message_embeddings = embed(messages)
for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join(
(str(x) for x in message_embedding[:3]))
print("Embedding: [{}, ...]\n".format(message_embedding_snippet))
Message: Elephant Embedding size: 512 Embedding: [0.008344474248588085, 0.00048079612315632403, 0.06595245748758316, ...] Message: I am a sentence for which I would like to get its embedding. Embedding size: 512 Embedding: [0.05080860108137131, -0.016524313017725945, 0.015737781301140785, ...] Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be. Embedding size: 512 Embedding: [-0.028332678601145744, -0.05586216226220131, -0.012941479682922363, ...]
শব্দার্থিক টেক্সচুয়াল সাদৃশ্য টাস্ক উদাহরণ
ইউনিভার্সাল সেন্টেন্স এনকোডার দ্বারা উত্পাদিত এমবেডিংগুলি প্রায় স্বাভাবিক করা হয়। দুটি বাক্যের শব্দার্থগত সাদৃশ্য তুচ্ছভাবে এনকোডিংয়ের অভ্যন্তরীণ পণ্য হিসাবে গণনা করা যেতে পারে।
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
def run_and_plot(messages_):
message_embeddings_ = embed(messages_)
plot_similarity(messages_, message_embeddings_, 90)
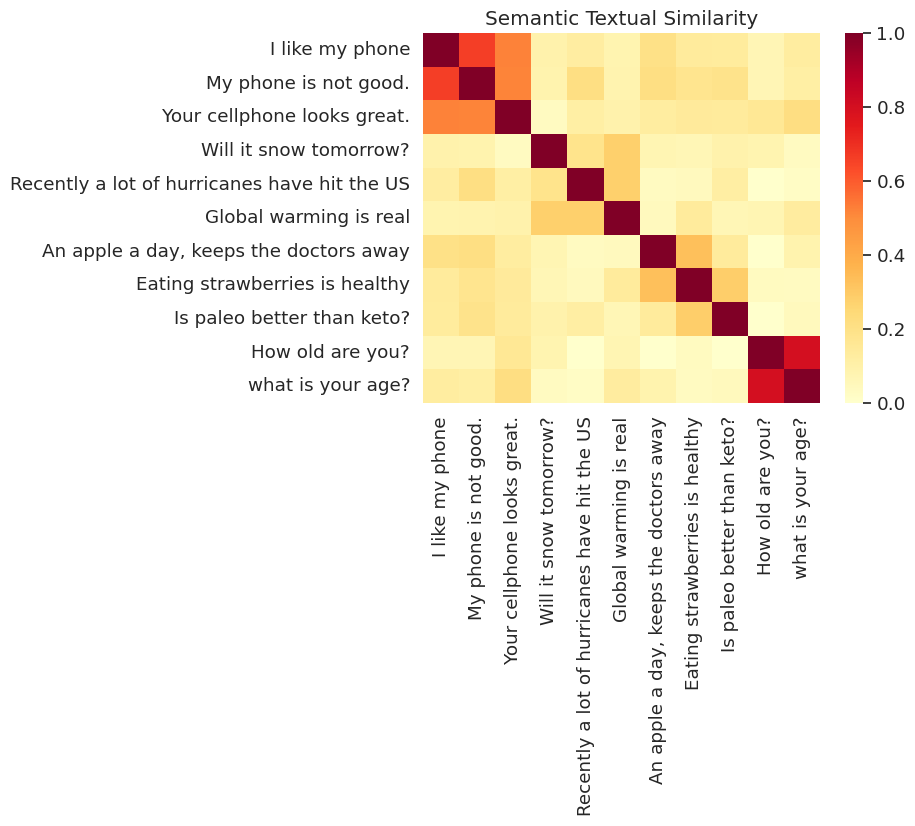
সাদৃশ্য ভিজ্যুয়ালাইজড
এখানে আমরা একটি তাপ মানচিত্রের মিল দেখাই। চূড়ান্ত গ্রাফ একটি 9x9 ম্যাট্রিক্স যেখানে প্রতিটি এন্ট্রি [i, j] বাক্যের জন্য এনকোডিং অভ্যন্তরীণ পণ্যের উপর ভিত্তি করে রঙ্গিন হয় i এবং j ।
messages = [
# Smartphones
"I like my phone",
"My phone is not good.",
"Your cellphone looks great.",
# Weather
"Will it snow tomorrow?",
"Recently a lot of hurricanes have hit the US",
"Global warming is real",
# Food and health
"An apple a day, keeps the doctors away",
"Eating strawberries is healthy",
"Is paleo better than keto?",
# Asking about age
"How old are you?",
"what is your age?",
]
run_and_plot(messages)
মূল্যায়ন: STS (Semantic Textual Similarity) বেঞ্চমার্ক
এসটিএস বেঞ্চমার্ক ডিগ্রী যা আদল স্কোর মানুষের আদালতের রায় এর মাধ্যমে ব্যবহার নির্ণিত বাক্য embeddings সারিবদ্ধ একজন স্বকীয় মূল্যায়ন প্রদান করে। বেঞ্চমার্কের জন্য সিস্টেমগুলিকে বাক্য জোড়ার বিভিন্ন নির্বাচনের জন্য সাদৃশ্য স্কোর ফেরত দিতে হবে। পিয়ারসন পারস্পরিক সম্পর্ক তারপর মানুষের রায় বিরুদ্ধে মেশিন আদল স্কোর মান নির্ণয় করতে ব্যবহৃত হয়।
ডেটা ডাউনলোড করুন
import pandas
import scipy
import math
import csv
sts_dataset = tf.keras.utils.get_file(
fname="Stsbenchmark.tar.gz",
origin="http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz",
extract=True)
sts_dev = pandas.read_table(
os.path.join(os.path.dirname(sts_dataset), "stsbenchmark", "sts-dev.csv"),
error_bad_lines=False,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
sts_test = pandas.read_table(
os.path.join(
os.path.dirname(sts_dataset), "stsbenchmark", "sts-test.csv"),
error_bad_lines=False,
quoting=csv.QUOTE_NONE,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
# cleanup some NaN values in sts_dev
sts_dev = sts_dev[[isinstance(s, str) for s in sts_dev['sent_2']]]
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3444: FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. exec(code_obj, self.user_global_ns, self.user_ns)
বাক্য এমবেডিং মূল্যায়ন
sts_data = sts_dev
def run_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_1'].tolist())), axis=1)
sts_encode2 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_2'].tolist())), axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2), axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities, -1.0, 1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
"""Returns the similarity scores"""
return scores
dev_scores = sts_data['sim'].tolist()
scores = []
for batch in np.array_split(sts_data, 10):
scores.extend(run_sts_benchmark(batch))
pearson_correlation = scipy.stats.pearsonr(scores, dev_scores)
print('Pearson correlation coefficient = {0}\np-value = {1}'.format(
pearson_correlation[0], pearson_correlation[1]))
Pearson correlation coefficient = 0.8036394630692778 p-value = 0.0