
| |
|
 GitHub で表示 GitHub で表示 |
|
このチュートリアルでは、事前トレーニング済みの動画分類モデルを実行して、特定の動画のアクティビティ(ダンス、水泳、サイクリングなど)を分類します。
このチュートリアルで使用されるモデルアーキテクチャは MoViNet(Mobile Video Networks)と呼ばれるものです。MoViNets は大型のデータセット(Kinetics 600)でトレーニングされた効率的な動画分類モデルファミリーです。
TF Hub にある i3d モデル とは反対に、MoViNets はストリーミング動画のフレームごとの推論もサポートしています。
事前トレーニング済みのモデルは TF Hub から利用できます。TF Hub コレクションには、TFLite 用に最適化された量子化モデルも含まれています。
これらのモデルのソースは TensorFlow Model Garden にあり、MoviNet モデルの構築とファインチューニングもカバーしたこのチュートリアルの長編が含まれています。
セットアップ
より小さなモデル(A0-A2)の推論の場合、この Colab には CPU で十分に対応できます。
sudo apt install -y ffmpegpip install -q mediapy
pip uninstall -q -y opencv-python-headlesspip install -q "opencv-python-headless<4.3"
# Import libraries
import pathlib
import matplotlib as mpl
import matplotlib.pyplot as plt
import mediapy as media
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_hub as hub
import tqdm
mpl.rcParams.update({
'font.size': 10,
})
2022-12-14 20:03:10.564786: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:03:10.564884: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:03:10.564894: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
kinetics 600 のラベルリストを取得し、最初のいくつかのラベルを出力します。
labels_path = tf.keras.utils.get_file(
fname='labels.txt',
origin='https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt'
)
labels_path = pathlib.Path(labels_path)
lines = labels_path.read_text().splitlines()
KINETICS_600_LABELS = np.array([line.strip() for line in lines])
KINETICS_600_LABELS[:20]
Downloading data from https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt
9209/9209 [==============================] - 0s 0us/step
array(['abseiling', 'acting in play', 'adjusting glasses', 'air drumming',
'alligator wrestling', 'answering questions', 'applauding',
'applying cream', 'archaeological excavation', 'archery',
'arguing', 'arm wrestling', 'arranging flowers',
'assembling bicycle', 'assembling computer',
'attending conference', 'auctioning', 'backflip (human)',
'baking cookies', 'bandaging'], dtype='<U49')
分類用の単純なサンプル動画を提供するために、ジャンピングジャックを行っている短い動画を読み込みます。

出典: Bobby Bluford コーチが YouTube で共有した映像。CC-BY ライセンス。
gif をダウンロードします。
jumpingjack_url = 'https://github.com/tensorflow/models/raw/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/jumpingjack.gif'
jumpingjack_path = tf.keras.utils.get_file(
fname='jumpingjack.gif',
origin=jumpingjack_url,
cache_dir='.', cache_subdir='.',
)
Downloading data from https://github.com/tensorflow/models/raw/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/jumpingjack.gif 783318/783318 [==============================] - 0s 0us/step
gif ファイルを tf.Tensor に読み取る関数を定義します。
# Read and process a video
def load_gif(file_path, image_size=(224, 224)):
"""Loads a gif file into a TF tensor.
Use images resized to match what's expected by your model.
The model pages say the "A2" models expect 224 x 224 images at 5 fps
Args:
file_path: path to the location of a gif file.
image_size: a tuple of target size.
Returns:
a video of the gif file
"""
# Load a gif file, convert it to a TF tensor
raw = tf.io.read_file(file_path)
video = tf.io.decode_gif(raw)
# Resize the video
video = tf.image.resize(video, image_size)
# change dtype to a float32
# Hub models always want images normalized to [0,1]
# ref: https://www.tensorflow.org/hub/common_signatures/images#input
video = tf.cast(video, tf.float32) / 255.
return video
動画の形状は (frames, height, width, colors) です。
jumpingjack=load_gif(jumpingjack_path)
jumpingjack.shape
TensorShape([13, 224, 224, 3])
モデルの使用方法
このセクションには、TensorFlow Hub のモデルの使用方法を示す手順が含まれます。モデルの実演のみをご覧になる場合は、次のセクションに進んでください。
各モデルには、base と streaming の 2 つのバージョンがあります。
baseバージョンは動画を入力として取り、フレームで平均化された確率を返します。streamingバージョンは、動画フレームと RNN の状態を入力として取り、そのフレームの予測と新しい RNN の状態を返します。
base モデル
TensorFlow Hub の事前トレーニング済みモデルをダウンロードします。
%%time
id = 'a2'
mode = 'base'
version = '3'
hub_url = f'https://tfhub.dev/tensorflow/movinet/{id}/{mode}/kinetics-600/classification/{version}'
model = hub.load(hub_url)
CPU times: user 14.4 s, sys: 812 ms, total: 15.2 s Wall time: 15.2 s
このバージョンのモデルには、signature が 1 つあります。形状 (batch, frames, height, width, colors) の tf.float32 である image 引数を取ります。戻り値は、形状 (batch, classes) のロジットの tf.float32 テンソルです。
sig = model.signatures['serving_default']
print(sig.pretty_printed_signature())
signature_wrapper(*, image)
Args:
image: float32 Tensor, shape=(None, None, None, None, 3)
Returns:
{'classifier_head': <1>}
<1>: float32 Tensor, shape=(None, 600)
動画でこのシグネチャを実行するには、最初に外側の batch 次元を動画に追加する必要があります。
#warmup
sig(image = jumpingjack[tf.newaxis, :1]);
%%time
logits = sig(image = jumpingjack[tf.newaxis, ...])
logits = logits['classifier_head'][0]
print(logits.shape)
print()
(600,) CPU times: user 3.93 s, sys: 30.5 ms, total: 3.96 s Wall time: 6.18 s
後で使用できるように上記の出力プロセッシングをパッケージ化する get_top_k を定義します。
# Get top_k labels and probabilities
def get_top_k(probs, k=5, label_map=KINETICS_600_LABELS):
"""Outputs the top k model labels and probabilities on the given video.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k labels and probabilities.
"""
# Sort predictions to find top_k
top_predictions = tf.argsort(probs, axis=-1, direction='DESCENDING')[:k]
# collect the labels of top_k predictions
top_labels = tf.gather(label_map, top_predictions, axis=-1)
# decode lablels
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
# top_k probabilities of the predictions
top_probs = tf.gather(probs, top_predictions, axis=-1).numpy()
return tuple(zip(top_labels, top_probs))
logits を確率に変換し、動画の上位 5 つのクラスをルックアップします。モデルは、動画がおそらく jumping jacks であることを確定します。
probs = tf.nn.softmax(logits, axis=-1)
for label, p in get_top_k(probs):
print(f'{label:20s}: {p:.3f}')
jumping jacks : 0.834 zumba : 0.008 lunge : 0.003 doing aerobics : 0.003 polishing metal : 0.002
streaming モデル
前のセクションでは、動画全体で実行するモデルを使用しました。最後に 1 つの予測を必要としない動画を処理する場合は通常、フレームごとに予測を更新する必要があります。これには、stream バージョンのモデルを使用できます。
stream バージョンのモデルを読み込みます。
%%time
id = 'a2'
mode = 'stream'
version = '3'
hub_url = f'https://tfhub.dev/tensorflow/movinet/{id}/{mode}/kinetics-600/classification/{version}'
model = hub.load(hub_url)
CPU times: user 41.9 s, sys: 2.16 s, total: 44 s Wall time: 44 s
このモデルの使用は、base モデルよりもわずかに複雑で、モデルの RNN の内部状態を追跡する必要があります。
list(model.signatures.keys())
['call', 'init_states']
init_states シグネチャは、動画の shape (batch, frames, height, width, colors) を入力として取り、初期の RNN 状態を含むテンソルの大型のディクショナリを返します。
lines = model.signatures['init_states'].pretty_printed_signature().splitlines()
lines = lines[:10]
lines.append(' ...')
print('.\n'.join(lines))
signature_wrapper(*, input_shape).
Args:.
input_shape: int32 Tensor, shape=(5,).
Returns:.
{'state/b0/l0/pool_buffer': <1>, 'state/b0/l0/pool_frame_count': <2>, 'state/b0/l1/pool_buffer': <3>, 'state/b0/l1/pool_frame_count': <4>, 'state/b0/l1/stream_buffer': <5>, 'state/b0/l2/pool_buffer': <6>, 'state/b0/l2/pool_frame_count': <7>, 'state/b0/l2/stream_buffer': <8>, 'state/b1/l0/pool_buffer': <9>, 'state/b1/l0/pool_frame_count': <10>, 'state/b1/l0/stream_buffer': <11>, 'state/b1/l1/pool_buffer': <12>, 'state/b1/l1/pool_frame_count': <13>, 'state/b1/l1/stream_buffer': <14>, 'state/b1/l2/pool_buffer': <15>, 'state/b1/l2/pool_frame_count': <16>, 'state/b1/l2/stream_buffer': <17>, 'state/b1/l3/pool_buffer': <18>, 'state/b1/l3/pool_frame_count': <19>, 'state/b1/l3/stream_buffer': <20>, 'state/b1/l4/pool_buffer': <21>, 'state/b1/l4/pool_frame_count': <22>, 'state/b1/l4/stream_buffer': <23>, 'state/b2/l0/pool_buffer': <24>, 'state/b2/l0/pool_frame_count': <25>, 'state/b2/l0/stream_buffer': <26>, 'state/b2/l1/pool_buffer': <27>, 'state/b2/l1/pool_frame_count': <28>, 'state/b2/l1/stream_buffer': <29>, 'state/b2/l2/pool_buffer': <30>, 'state/b2/l2/pool_frame_count': <31>, 'state/b2/l2/stream_buffer': <32>, 'state/b2/l3/pool_buffer': <33>, 'state/b2/l3/pool_frame_count': <34>, 'state/b2/l3/stream_buffer': <35>, 'state/b2/l4/pool_buffer': <36>, 'state/b2/l4/pool_frame_count': <37>, 'state/b2/l4/stream_buffer': <38>, 'state/b3/l0/pool_buffer': <39>, 'state/b3/l0/pool_frame_count': <40>, 'state/b3/l0/stream_buffer': <41>, 'state/b3/l1/pool_buffer': <42>, 'state/b3/l1/pool_frame_count': <43>, 'state/b3/l1/stream_buffer': <44>, 'state/b3/l2/pool_buffer': <45>, 'state/b3/l2/pool_frame_count': <46>, 'state/b3/l2/stream_buffer': <47>, 'state/b3/l3/pool_buffer': <48>, 'state/b3/l3/pool_frame_count': <49>, 'state/b3/l3/stream_buffer': <50>, 'state/b3/l4/pool_buffer': <51>, 'state/b3/l4/pool_frame_count': <52>, 'state/b3/l5/pool_buffer': <53>, 'state/b3/l5/pool_frame_count': <54>, 'state/b3/l5/stream_buffer': <55>, 'state/b4/l0/pool_buffer': <56>, 'state/b4/l0/pool_frame_count': <57>, 'state/b4/l0/stream_buffer': <58>, 'state/b4/l1/pool_buffer': <59>, 'state/b4/l1/pool_frame_count': <60>, 'state/b4/l2/pool_buffer': <61>, 'state/b4/l2/pool_frame_count': <62>, 'state/b4/l3/pool_buffer': <63>, 'state/b4/l3/pool_frame_count': <64>, 'state/b4/l4/pool_buffer': <65>, 'state/b4/l4/pool_frame_count': <66>, 'state/b4/l5/pool_buffer': <67>, 'state/b4/l5/pool_frame_count': <68>, 'state/b4/l5/stream_buffer': <69>, 'state/b4/l6/pool_buffer': <70>, 'state/b4/l6/pool_frame_count': <71>, 'state/head/pool_buffer': <72>, 'state/head/pool_frame_count': <73>}.
<1>: float32 Tensor, shape=(None, 1, 1, 1, 40).
<2>: int32 Tensor, shape=(1,).
<3>: float32 Tensor, shape=(None, 1, 1, 1, 40).
<4>: int32 Tensor, shape=(1,).
<5>: float32 Tensor, shape=(None, 2, None, None, 40).
...
initial_state = model.init_states(jumpingjack[tf.newaxis, ...].shape)
type(initial_state)
dict
list(sorted(initial_state.keys()))[:5]
['state/b0/l0/pool_buffer', 'state/b0/l0/pool_frame_count', 'state/b0/l1/pool_buffer', 'state/b0/l1/pool_frame_count', 'state/b0/l1/stream_buffer']
RNN の初期状態を取得したら、その状態と動画のフレームを入力として渡すことができます(動画フレームの形状 (batch, frames, height, width, colors) を維持する必要があります)。モデルは (logits, state) ペアを返します。
最初のフレームを確認しただけでは、モデルは動画が「jumping jacks」であることに納得しません。
inputs = initial_state.copy()
# Add the batch axis, take the first frme, but keep the frame-axis.
inputs['image'] = jumpingjack[tf.newaxis, 0:1, ...]
# warmup
model(inputs);
logits, new_state = model(inputs)
logits = logits[0]
probs = tf.nn.softmax(logits, axis=-1)
for label, p in get_top_k(probs):
print(f'{label:20s}: {p:.3f}')
print()
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
このモデルをループで実行し、フレームごとに更新された状態を渡すと、すぐに正しい結果に収束します。
%%time
state = initial_state.copy()
all_logits = []
for n in range(len(jumpingjack)):
inputs = state
inputs['image'] = jumpingjack[tf.newaxis, n:n+1, ...]
result, state = model(inputs)
all_logits.append(logits)
probabilities = tf.nn.softmax(all_logits, axis=-1)
CPU times: user 473 ms, sys: 29.6 ms, total: 503 ms Wall time: 442 ms
for label, p in get_top_k(probabilities[-1]):
print(f'{label:20s}: {p:.3f}')
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
id = tf.argmax(probabilities[-1])
plt.plot(probabilities[:, id])
plt.xlabel('Frame #')
plt.ylabel(f"p('{KINETICS_600_LABELS[id]}')");
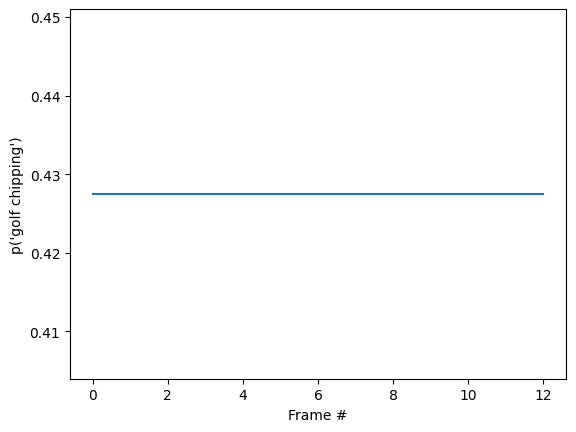
最終的な確率が、base モデルを実行した前のセクションよりもはるかに確実であることに気づくことでしょう。base モデルは複数のフレームに対する予測の平均を返します。
for label, p in get_top_k(tf.reduce_mean(probabilities, axis=0)):
print(f'{label:20s}: {p:.3f}')
golf chipping : 0.427 tackling : 0.134 lunge : 0.056 stretching arm : 0.053 passing american football (not in game): 0.039
経時的な予測をアニメーション化する
前のセクションでは、これらのモデルの使用方法について詳しく説明しました。このセクションではそれを基に、推論アニメーションを生成していきます。
以下の非表示セルは、このセクションで使用されるヘルパー関数を定義します。
# Get top_k labels and probabilities predicted using MoViNets streaming model
def get_top_k_streaming_labels(probs, k=5, label_map=KINETICS_600_LABELS):
"""Returns the top-k labels over an entire video sequence.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k probabilities, labels, and logit indices
"""
top_categories_last = tf.argsort(probs, -1, 'DESCENDING')[-1, :1]
# Sort predictions to find top_k
categories = tf.argsort(probs, -1, 'DESCENDING')[:, :k]
categories = tf.reshape(categories, [-1])
counts = sorted([
(i.numpy(), tf.reduce_sum(tf.cast(categories == i, tf.int32)).numpy())
for i in tf.unique(categories)[0]
], key=lambda x: x[1], reverse=True)
top_probs_idx = tf.constant([i for i, _ in counts[:k]])
top_probs_idx = tf.concat([top_categories_last, top_probs_idx], 0)
# find unique indices of categories
top_probs_idx = tf.unique(top_probs_idx)[0][:k+1]
# top_k probabilities of the predictions
top_probs = tf.gather(probs, top_probs_idx, axis=-1)
top_probs = tf.transpose(top_probs, perm=(1, 0))
# collect the labels of top_k predictions
top_labels = tf.gather(label_map, top_probs_idx, axis=0)
# decode the top_k labels
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
return top_probs, top_labels, top_probs_idx
# Plot top_k predictions at a given time step
def plot_streaming_top_preds_at_step(
top_probs,
top_labels,
step=None,
image=None,
legend_loc='lower left',
duration_seconds=10,
figure_height=500,
playhead_scale=0.8,
grid_alpha=0.3):
"""Generates a plot of the top video model predictions at a given time step.
Args:
top_probs: a tensor of shape (k, num_frames) representing the top-k
probabilities over all frames.
top_labels: a list of length k that represents the top-k label strings.
step: the current time step in the range [0, num_frames].
image: the image frame to display at the current time step.
legend_loc: the placement location of the legend.
duration_seconds: the total duration of the video.
figure_height: the output figure height.
playhead_scale: scale value for the playhead.
grid_alpha: alpha value for the gridlines.
Returns:
A tuple of the output numpy image, figure, and axes.
"""
# find number of top_k labels and frames in the video
num_labels, num_frames = top_probs.shape
if step is None:
step = num_frames
# Visualize frames and top_k probabilities of streaming video
fig = plt.figure(figsize=(6.5, 7), dpi=300)
gs = mpl.gridspec.GridSpec(8, 1)
ax2 = plt.subplot(gs[:-3, :])
ax = plt.subplot(gs[-3:, :])
# display the frame
if image is not None:
ax2.imshow(image, interpolation='nearest')
ax2.axis('off')
# x-axis (frame number)
preview_line_x = tf.linspace(0., duration_seconds, num_frames)
# y-axis (top_k probabilities)
preview_line_y = top_probs
line_x = preview_line_x[:step+1]
line_y = preview_line_y[:, :step+1]
for i in range(num_labels):
ax.plot(preview_line_x, preview_line_y[i], label=None, linewidth='1.5',
linestyle=':', color='gray')
ax.plot(line_x, line_y[i], label=top_labels[i], linewidth='2.0')
ax.grid(which='major', linestyle=':', linewidth='1.0', alpha=grid_alpha)
ax.grid(which='minor', linestyle=':', linewidth='0.5', alpha=grid_alpha)
min_height = tf.reduce_min(top_probs) * playhead_scale
max_height = tf.reduce_max(top_probs)
ax.vlines(preview_line_x[step], min_height, max_height, colors='red')
ax.scatter(preview_line_x[step], max_height, color='red')
ax.legend(loc=legend_loc)
plt.xlim(0, duration_seconds)
plt.ylabel('Probability')
plt.xlabel('Time (s)')
plt.yscale('log')
fig.tight_layout()
fig.canvas.draw()
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
plt.close()
figure_width = int(figure_height * data.shape[1] / data.shape[0])
image = PIL.Image.fromarray(data).resize([figure_width, figure_height])
image = np.array(image)
return image
# Plotting top_k predictions from MoViNets streaming model
def plot_streaming_top_preds(
probs,
video,
top_k=5,
video_fps=25.,
figure_height=500,
use_progbar=True):
"""Generates a video plot of the top video model predictions.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
video: the video to display in the plot.
top_k: the number of top predictions to select.
video_fps: the input video fps.
figure_fps: the output video fps.
figure_height: the height of the output video.
use_progbar: display a progress bar.
Returns:
A numpy array representing the output video.
"""
# select number of frames per second
video_fps = 8.
# select height of the image
figure_height = 500
# number of time steps of the given video
steps = video.shape[0]
# estimate duration of the video (in seconds)
duration = steps / video_fps
# estiamte top_k probabilities and corresponding labels
top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)
images = []
step_generator = tqdm.trange(steps) if use_progbar else range(steps)
for i in step_generator:
image = plot_streaming_top_preds_at_step(
top_probs=top_probs,
top_labels=top_labels,
step=i,
image=video[i],
duration_seconds=duration,
figure_height=figure_height,
)
images.append(image)
return np.array(images)
動画のフレーム全体に streaming モデルを実行し、ロジットを収集することから始めます。
init_states = model.init_states(jumpingjack[tf.newaxis].shape)
# Insert your video clip here
video = jumpingjack
images = tf.split(video[tf.newaxis], video.shape[0], axis=1)
all_logits = []
# To run on a video, pass in one frame at a time
states = init_states
for image in tqdm.tqdm(images):
# predictions for each frame
logits, states = model({**states, 'image': image})
all_logits.append(logits)
# concatinating all the logits
logits = tf.concat(all_logits, 0)
# estimating probabilities
probs = tf.nn.softmax(logits, axis=-1)
100%|██████████| 13/13 [00:00<00:00, 29.66it/s]
final_probs = probs[-1]
print('Top_k predictions and their probablities\n')
for label, p in get_top_k(final_probs):
print(f'{label:20s}: {p:.3f}')
Top_k predictions and their probablities jumping jacks : 0.999 zumba : 0.000 doing aerobics : 0.000 dancing charleston : 0.000 slacklining : 0.000
確率のシーケンスを動画に変換します。
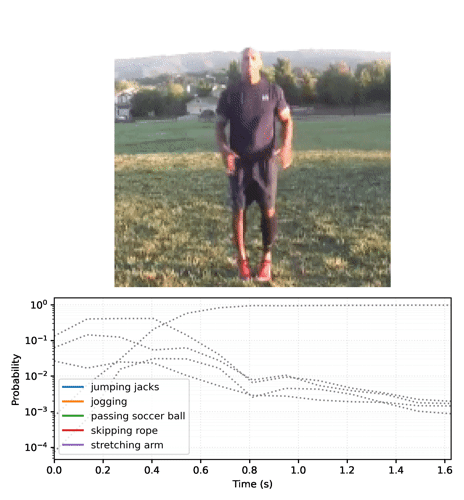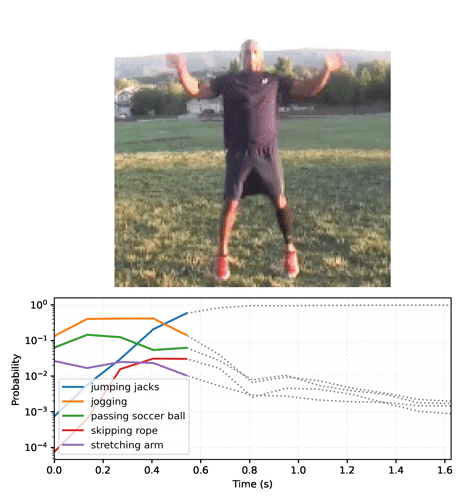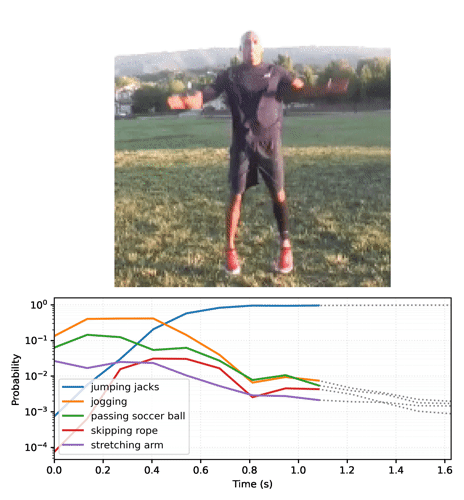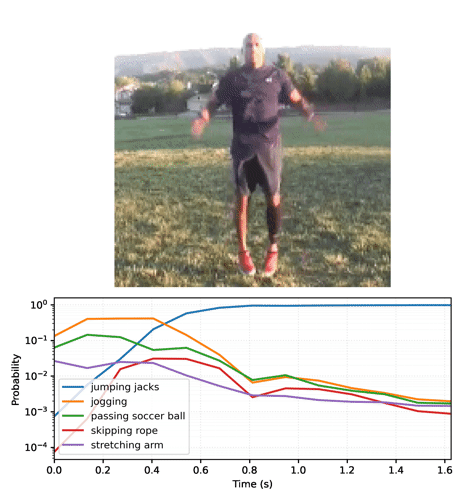
# Generate a plot and output to a video tensor
plot_video = plot_streaming_top_preds(probs, video, video_fps=8.)
100%|██████████| 13/13 [00:07<00:00, 1.73it/s]
# For gif format, set codec='gif'
media.show_video(plot_video, fps=3)
参考資料
事前トレーニング済みのモデルは TF Hub から利用できます。TF Hub コレクションには、TFLite 用に最適化された量子化モデルも含まれています。
これらのモデルのソースは TensorFlow Model Garden にあり、MoviNet モデルの構築とファインチューニングもカバーしたこのチュートリアルの長編が含まれています。