
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
|
きれいな花を見つけて、何の花かと思ったことはありませんか?そう思ったのはあなただけではありません。写真から花の種類を特定する方法を構築しましょう!
画像の分類については、畳み込みニューラルネットワークという特定の種類のディープニューラルネットワークが特に強力であることが実証されました。ただし、最新の畳み込みニューラルネットワークには数百ものパラメータがあります。ゼロからトレーニングするには大量のラベル付きのトレーニングデータと多大な計算能力(数百時間以上の GPU)が必要ですが、ここでは 3000 枚のラベル付き写真しかなく、あまり時間をかけられないため、多少頭を使う必要があります。
ここではトレーニング済みのネットワーク(約 100 万個の一般的な画像でトレーニング)を用いた転移学習というテクニックを使用して、特徴量を抽出し、花の画像を分類するというタスク向けにさらに新しいレイヤーをトレーニングします。
セットアップ
import collections
import io
import math
import os
import random
from six.moves import urllib
from IPython.display import clear_output, Image, display, HTML
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import tensorflow_hub as hub
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.metrics as sk_metrics
import time
2024-01-11 17:56:09.794501: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 17:56:09.794548: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 17:56:09.796039: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/compat/v2_compat.py:108: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term
Flowers データセット
flowers データセットは、可能性のある 5 つのクラスラベルを伴う花の画像で構成されています。
機械学習モデルをトレーニングする際、データを training と test データセットに分割します。training データを使ってモデルをトレーニングしてから、モデルが分析したことのないデータ(test セット)でのモデルのパフォーマンスを評価します。
training と test サンプルをダウンロードし(時間がかかる場合があります)、training と test のセットに分割しましょう。
次の 2 つのセルを実行します。
FLOWERS_DIR = './flower_photos'
TRAIN_FRACTION = 0.8
RANDOM_SEED = 2018
def download_images():
"""If the images aren't already downloaded, save them to FLOWERS_DIR."""
if not os.path.exists(FLOWERS_DIR):
DOWNLOAD_URL = 'http://download.tensorflow.org/example_images/flower_photos.tgz'
print('Downloading flower images from %s...' % DOWNLOAD_URL)
urllib.request.urlretrieve(DOWNLOAD_URL, 'flower_photos.tgz')
!tar xfz flower_photos.tgz
print('Flower photos are located in %s' % FLOWERS_DIR)
def make_train_and_test_sets():
"""Split the data into train and test sets and get the label classes."""
train_examples, test_examples = [], []
shuffler = random.Random(RANDOM_SEED)
is_root = True
for (dirname, subdirs, filenames) in tf.gfile.Walk(FLOWERS_DIR):
# The root directory gives us the classes
if is_root:
subdirs = sorted(subdirs)
classes = collections.OrderedDict(enumerate(subdirs))
label_to_class = dict([(x, i) for i, x in enumerate(subdirs)])
is_root = False
# The sub directories give us the image files for training.
else:
filenames.sort()
shuffler.shuffle(filenames)
full_filenames = [os.path.join(dirname, f) for f in filenames]
label = dirname.split('/')[-1]
label_class = label_to_class[label]
# An example is the image file and it's label class.
examples = list(zip(full_filenames, [label_class] * len(filenames)))
num_train = int(len(filenames) * TRAIN_FRACTION)
train_examples.extend(examples[:num_train])
test_examples.extend(examples[num_train:])
shuffler.shuffle(train_examples)
shuffler.shuffle(test_examples)
return train_examples, test_examples, classes
# Download the images and split the images into train and test sets.
download_images()
TRAIN_EXAMPLES, TEST_EXAMPLES, CLASSES = make_train_and_test_sets()
NUM_CLASSES = len(CLASSES)
print('\nThe dataset has %d label classes: %s' % (NUM_CLASSES, CLASSES.values()))
print('There are %d training images' % len(TRAIN_EXAMPLES))
print('there are %d test images' % len(TEST_EXAMPLES))
Downloading flower images from http://download.tensorflow.org/example_images/flower_photos.tgz... Flower photos are located in ./flower_photos The dataset has 5 label classes: odict_values(['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']) There are 2934 training images there are 736 test images
データを確認する
flowers データセットは、ラベル付きの花の画像のサンプルで構成されています。各サンプルには、JPEG 形式の花の画像と、花の種類を示すクラスラベルが含まれます。いくつかの画像をラベルとともに表示してみましょう。
Show some labeled images
def get_label(example):
"""Get the label (number) for given example."""
return example[1]
def get_class(example):
"""Get the class (string) of given example."""
return CLASSES[get_label(example)]
def get_encoded_image(example):
"""Get the image data (encoded jpg) of given example."""
image_path = example[0]
return tf.gfile.GFile(image_path, 'rb').read()
def get_image(example):
"""Get image as np.array of pixels for given example."""
return plt.imread(io.BytesIO(get_encoded_image(example)), format='jpg')
def display_images(images_and_classes, cols=5):
"""Display given images and their labels in a grid."""
rows = int(math.ceil(len(images_and_classes) / cols))
fig = plt.figure()
fig.set_size_inches(cols * 3, rows * 3)
for i, (image, flower_class) in enumerate(images_and_classes):
plt.subplot(rows, cols, i + 1)
plt.axis('off')
plt.imshow(image)
plt.title(flower_class)
NUM_IMAGES = 15
display_images([(get_image(example), get_class(example))
for example in TRAIN_EXAMPLES[:NUM_IMAGES]])

モデルを構築する
TF-Hub の画像特徴量ベクトルモジュールを読み込み、それに線形分類器をスタックし、トレーニングと検証の演算を追加することにします。次のセルは、モデルとそのトレーニングを説明する TF グラフを構築しますが、トレーニングを実行しません(この後のステップで行います)。
LEARNING_RATE = 0.01
tf.reset_default_graph()
# Load a pre-trained TF-Hub module for extracting features from images. We've
# chosen this particular module for speed, but many other choices are available.
image_module = hub.Module('https://tfhub.dev/google/imagenet/mobilenet_v2_035_128/feature_vector/2')
# Preprocessing images into tensors with size expected by the image module.
encoded_images = tf.placeholder(tf.string, shape=[None])
image_size = hub.get_expected_image_size(image_module)
def decode_and_resize_image(encoded):
decoded = tf.image.decode_jpeg(encoded, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
return tf.image.resize_images(decoded, image_size)
batch_images = tf.map_fn(decode_and_resize_image, encoded_images, dtype=tf.float32)
# The image module can be applied as a function to extract feature vectors for a
# batch of images.
features = image_module(batch_images)
def create_model(features):
"""Build a model for classification from extracted features."""
# Currently, the model is just a single linear layer. You can try to add
# another layer, but be careful... two linear layers (when activation=None)
# are equivalent to a single linear layer. You can create a nonlinear layer
# like this:
# layer = tf.layers.dense(inputs=..., units=..., activation=tf.nn.relu)
layer = tf.layers.dense(inputs=features, units=NUM_CLASSES, activation=None)
return layer
# For each class (kind of flower), the model outputs some real number as a score
# how much the input resembles this class. This vector of numbers is often
# called the "logits".
logits = create_model(features)
labels = tf.placeholder(tf.float32, [None, NUM_CLASSES])
# Mathematically, a good way to measure how much the predicted probabilities
# diverge from the truth is the "cross-entropy" between the two probability
# distributions. For numerical stability, this is best done directly from the
# logits, not the probabilities extracted from them.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# Let's add an optimizer so we can train the network.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=LEARNING_RATE)
train_op = optimizer.minimize(loss=cross_entropy_mean)
# The "softmax" function transforms the logits vector into a vector of
# probabilities: non-negative numbers that sum up to one, and the i-th number
# says how likely the input comes from class i.
probabilities = tf.nn.softmax(logits)
# We choose the highest one as the predicted class.
prediction = tf.argmax(probabilities, 1)
correct_prediction = tf.equal(prediction, tf.argmax(labels, 1))
# The accuracy will allow us to eval on our test set.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_19573/2879154528.py:20: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version. Instructions for updating: Use fn_output_signature instead WARNING:tensorflow:From /tmpfs/tmp/ipykernel_19573/2879154528.py:20: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version. Instructions for updating: Use fn_output_signature instead INFO:tensorflow:Saver not created because there are no variables in the graph to restore INFO:tensorflow:Saver not created because there are no variables in the graph to restore /tmpfs/tmp/ipykernel_19573/2879154528.py:34: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead. layer = tf.layers.dense(inputs=features, units=NUM_CLASSES, activation=None)
ネットワークをトレーニングする
ラベルの構築が完了したので、test セットを使ってトレーニングし、そのパフォーマンスを確認することにしましょう。
# How long will we train the network (number of batches).
NUM_TRAIN_STEPS = 100
# How many training examples we use in each step.
TRAIN_BATCH_SIZE = 10
# How often to evaluate the model performance.
EVAL_EVERY = 10
def get_batch(batch_size=None, test=False):
"""Get a random batch of examples."""
examples = TEST_EXAMPLES if test else TRAIN_EXAMPLES
batch_examples = random.sample(examples, batch_size) if batch_size else examples
return batch_examples
def get_images_and_labels(batch_examples):
images = [get_encoded_image(e) for e in batch_examples]
one_hot_labels = [get_label_one_hot(e) for e in batch_examples]
return images, one_hot_labels
def get_label_one_hot(example):
"""Get the one hot encoding vector for the example."""
one_hot_vector = np.zeros(NUM_CLASSES)
np.put(one_hot_vector, get_label(example), 1)
return one_hot_vector
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(NUM_TRAIN_STEPS):
# Get a random batch of training examples.
train_batch = get_batch(batch_size=TRAIN_BATCH_SIZE)
batch_images, batch_labels = get_images_and_labels(train_batch)
# Run the train_op to train the model.
train_loss, _, train_accuracy = sess.run(
[cross_entropy_mean, train_op, accuracy],
feed_dict={encoded_images: batch_images, labels: batch_labels})
is_final_step = (i == (NUM_TRAIN_STEPS - 1))
if i % EVAL_EVERY == 0 or is_final_step:
# Get a batch of test examples.
test_batch = get_batch(batch_size=None, test=True)
batch_images, batch_labels = get_images_and_labels(test_batch)
# Evaluate how well our model performs on the test set.
test_loss, test_accuracy, test_prediction, correct_predicate = sess.run(
[cross_entropy_mean, accuracy, prediction, correct_prediction],
feed_dict={encoded_images: batch_images, labels: batch_labels})
print('Test accuracy at step %s: %.2f%%' % (i, (test_accuracy * 100)))
Test accuracy at step 0: 24.46% Test accuracy at step 10: 50.41% Test accuracy at step 20: 61.96% Test accuracy at step 30: 69.02% Test accuracy at step 40: 69.84% Test accuracy at step 50: 72.83% Test accuracy at step 60: 75.54% Test accuracy at step 70: 76.63% Test accuracy at step 80: 76.63% Test accuracy at step 90: 78.53% Test accuracy at step 99: 78.80%
def show_confusion_matrix(test_labels, predictions):
"""Compute confusion matrix and normalize."""
confusion = sk_metrics.confusion_matrix(
np.argmax(test_labels, axis=1), predictions)
confusion_normalized = confusion.astype("float") / confusion.sum(axis=1)
axis_labels = list(CLASSES.values())
ax = sns.heatmap(
confusion_normalized, xticklabels=axis_labels, yticklabels=axis_labels,
cmap='Blues', annot=True, fmt='.2f', square=True)
plt.title("Confusion matrix")
plt.ylabel("True label")
plt.xlabel("Predicted label")
show_confusion_matrix(batch_labels, test_prediction)
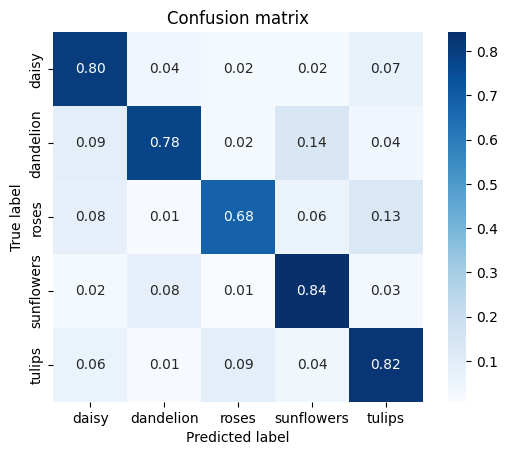
不正確な予測
モデルが間違えた test サンプルをもう少し詳しく見てみましょう。
- test セットに誤ってラベル付けされたサンプルがありますか?
- test セットに、実際には花の画像でないものなど、不適切なデータがありますか?
- モデルがミスした原因がわかる画像はありますか?
incorrect = [
(example, CLASSES[prediction])
for example, prediction, is_correct in zip(test_batch, test_prediction, correct_predicate)
if not is_correct
]
display_images(
[(get_image(example), "prediction: {0}\nlabel:{1}".format(incorrect_prediction, get_class(example)))
for (example, incorrect_prediction) in incorrect[:20]])

演習: モデルを改善しましょう!
ベースラインモデルはトレーニングしたので、正確性を高められるようにそれを改善してみましょう。(変更を適用するたびに、セルを実行し直す必要があります。)
演習 1: 異なる画像モデルを試す
TF-Hub では、異なる画像モデルを簡単に試すことができます。hub.Module() 内の "https://tfhub.dev/google/imagenet/mobilenet_v2_050_128/feature_vector/2" ハンドルを別のモジュールのハンドルに置き換えて、すべてのコードを実行し直すだけで可能です。利用可能なすべての画像モジュールは、tfhub.dev にあります。
ほかの MobileNet V2 モジュールを使用すると良いでしょう。MobileNet モジュールを含む多数のモジュールは、100 万個を超える画像と 1000 個のクラスを含む ImageNet データセットを使ってトレーニングされたものです。ネットワークアーキテクチャの選択によって、速度と分類精度にトレードオフが生じます。MobileNet または NASNet Mobile は高速で小型ですが、Inception や ResNet などのより従来的なアーキテクチャは、精度を重視して設計されています。
より大規模な Inception V3 アーキテクチャの場合は、目的のタスクにより近い領域で事前にトレーニングされているというメリットを得ることができます。植物や動物の iNaturalist データセットでトレーニングされたモジュールとして提供されています。
演習 2: 非表示レイヤーを追加する
抽出した画像特徴量と線形分類器の間に非表示レイヤーをスタックします(上記の create_model() 内)。100 個などのノードで非線形の非表示レイヤーを作成するには、tf.layers.dense を使用し、ユニットを 100、アクティベーションを tf.nn.relu に設定します。非表示レイヤーのサイズを変更すると、テストの精度に影響しますか?2 つ目の非表示レイヤーを追加すると、精度が改善されますか?
演習 3: ハイパーパラメータを変更する
トレーニングステップ数を変更すると、最終精度が改善されますか?学習速度を変更すると、モデルの収束を加速化できますか?トレーニングのバッチサイズによって、モデルのパフォーマンスが変化しますか?
演習 4: 異なるオプティマイザを試す
基本の GradientDescentOptimizer を、AdagradOptimizer などのより高度なオプティマイザに置き換えてみましょう。モデルのトレーニングに変化はありますか?さまざまな最適化アルゴリズムのメリットの詳細については、こちらの記事をご覧ください。
今後の学習
このチュートリアルのさらに高度なバージョンに興味がある方は、TensorBoard を使用したトレーニングの視覚化、画像に歪みを与えてデータセットを拡張する高度なテクニック、および flowers データセットを置き換えて独自のデータセットで画像分類器を学習する方法を説明した TensorFlow 画像の再トレーニングチュートリアルをご覧ください。
tensorflow.org/hub では、TensorFlow についてさらに学習し、TF-Hub API ドキュメントを確認することができます。また、tfhub.dev では、その他の画像特徴量ベクトルモジュールやテキスト埋め込みモジュールなど、利用可能な TensorFlow Hub モジュールを検索することができます。
さらに、Google の Machine Learning Crash Course もご覧ください。機械学習の実用的な導入をテンポよく学習できます。