
| | |  Xem trên GitHub Xem trên GitHub | | |
Sổ tay này hướng dẫn bạn cách tinh chỉnh các mô hình CropNet từ TensorFlow Hub trên tập dữ liệu từ TFDS hoặc tập dữ liệu phát hiện bệnh cây trồng của riêng bạn.
Bạn sẽ:
- Tải tập dữ liệu sắn TFDS hoặc dữ liệu của riêng bạn
- Làm phong phú dữ liệu với các ví dụ không xác định (phủ định) để có được một mô hình mạnh mẽ hơn
- Áp dụng tăng cường hình ảnh cho dữ liệu
- Tải và tinh chỉnh mô hình CropNet từ TF Hub
- Xuất mô hình TFLite, sẵn sàng được triển khai trên ứng dụng của bạn với Thư viện tác vụ , MLKit hoặc TFLite trực tiếp
Nhập khẩu và Phụ thuộc
Trước khi bắt đầu, bạn sẽ cần cài đặt một số phụ thuộc cần thiết như Model Maker và phiên bản TensorFlow Datasets mới nhất.
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
Tải tập dữ liệu TFDS để tinh chỉnh
Cho phép sử dụng bộ dữ liệu về Bệnh lá sắn công khai từ TFDS.
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
Hoặc cách khác, tải dữ liệu của riêng bạn để tinh chỉnh
Thay vì sử dụng tập dữ liệu TFDS, bạn cũng có thể đào tạo trên dữ liệu của riêng mình. Đoạn mã này cho biết cách tải tập dữ liệu tùy chỉnh của riêng bạn. Xem liên kết này để biết cấu trúc được hỗ trợ của dữ liệu. Một ví dụ được cung cấp ở đây bằng cách sử dụng bộ dữ liệu Bệnh lá sắn có sẵn công khai.
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
Hình dung các mẫu từ tách đoàn tàu
Hãy xem một số ví dụ từ tập dữ liệu bao gồm id lớp và tên lớp cho các mẫu hình ảnh và nhãn của chúng.
_ = tfds.show_examples(ds_train, ds_info)

Thêm hình ảnh được sử dụng làm ví dụ không xác định từ tập dữ liệu TFDS
Thêm các ví dụ không xác định (phủ định) bổ sung vào tập dữ liệu đào tạo và gán một số nhãn lớp không xác định mới cho chúng. Mục tiêu là có một mô hình mà khi được sử dụng trong thực tế (ví dụ như tại hiện trường), có tùy chọn dự đoán "Không xác định" khi nó nhìn thấy điều gì đó bất ngờ.
Dưới đây, bạn có thể thấy danh sách các tập dữ liệu sẽ được sử dụng để lấy mẫu hình ảnh không xác định bổ sung. Nó bao gồm 3 bộ dữ liệu hoàn toàn khác nhau để tăng tính đa dạng. Một trong số đó là tập dữ liệu bệnh lá đậu, để mô hình tiếp xúc với các cây bị bệnh không phải cây sắn.
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
Tập dữ liệu UNKNOWN cũng được tải từ TFDS.
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
Áp dụng các phần bổ sung
Đối với tất cả các hình ảnh, để làm cho chúng đa dạng hơn, bạn sẽ áp dụng một số biện pháp tăng cường, chẳng hạn như các thay đổi trong:
- độ sáng
- Sự tương phản
- Bão hòa
- Huế
- Trồng trọt
Các loại tăng cường này giúp làm cho mô hình mạnh mẽ hơn đối với các biến thể trong đầu vào hình ảnh.
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
Để áp dụng phần mở rộng, nó sử dụng phương thức map từ lớp Dataset.
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
Bọc dữ liệu thành định dạng thân thiện với Model Maker
Để sử dụng các tập dữ liệu này với Model Maker, chúng cần phải thuộc lớp ImageClassifierDataLoader.
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
Chạy đào tạo
TensorFlow Hub có sẵn nhiều mô hình cho Học chuyển giao.
Ở đây bạn có thể chọn một và bạn cũng có thể tiếp tục thử nghiệm với những cái khác để cố gắng đạt được kết quả tốt hơn.
Nếu bạn muốn thử nhiều mô hình hơn nữa, bạn có thể thêm chúng từ bộ sưu tập này.
Chọn một mô hình cơ sở
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
Để tinh chỉnh mô hình, bạn sẽ sử dụng Trình tạo mô hình. Điều này làm cho giải pháp tổng thể dễ dàng hơn vì sau khi đào tạo mô hình, nó cũng sẽ chuyển đổi nó thành TFLite.
Model Maker làm cho chuyển đổi này trở thành chuyển đổi tốt nhất có thể và với tất cả thông tin cần thiết để dễ dàng triển khai mô hình trên thiết bị sau này.
Thông số kỹ thuật của mô hình là cách bạn cho Model Maker biết mô hình cơ sở nào bạn muốn sử dụng.
image_model_spec = ModelSpec(uri=model_handle)
Một chi tiết quan trọng ở đây là thiết lập train_whole_model sẽ làm cho mô hình cơ sở được tinh chỉnh trong quá trình đào tạo. Điều này làm cho quá trình chậm hơn nhưng mô hình cuối cùng có độ chính xác cao hơn. Đặt shuffle sẽ đảm bảo mô hình nhìn thấy dữ liệu theo thứ tự xáo trộn ngẫu nhiên, đây là phương pháp hay nhất để học mô hình.
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
Đánh giá mô hình trên phân tách thử nghiệm
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
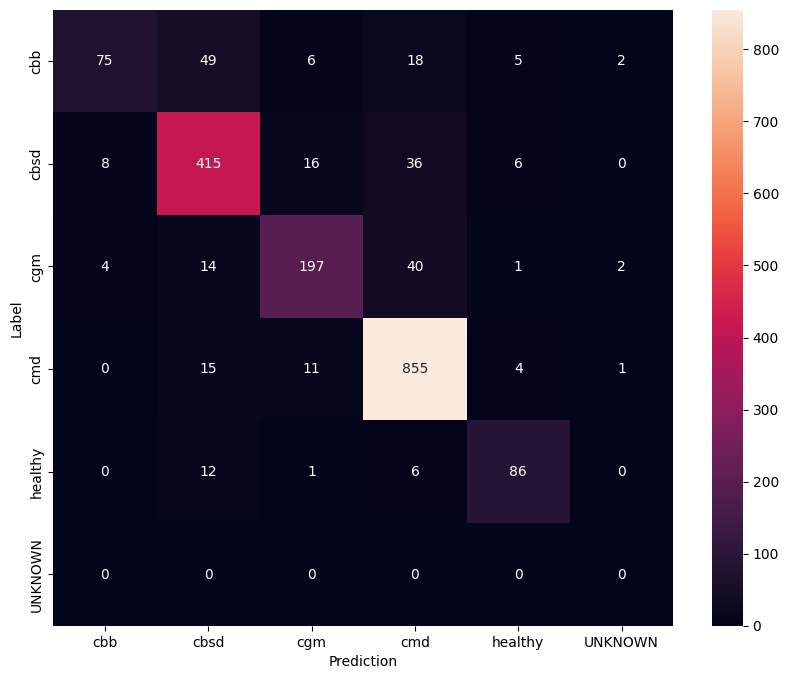
Để hiểu rõ hơn về mô hình tinh chỉnh, tốt hơn là bạn nên phân tích ma trận nhầm lẫn. Điều này sẽ cho biết tần suất một lớp được dự đoán là lớp khác.
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
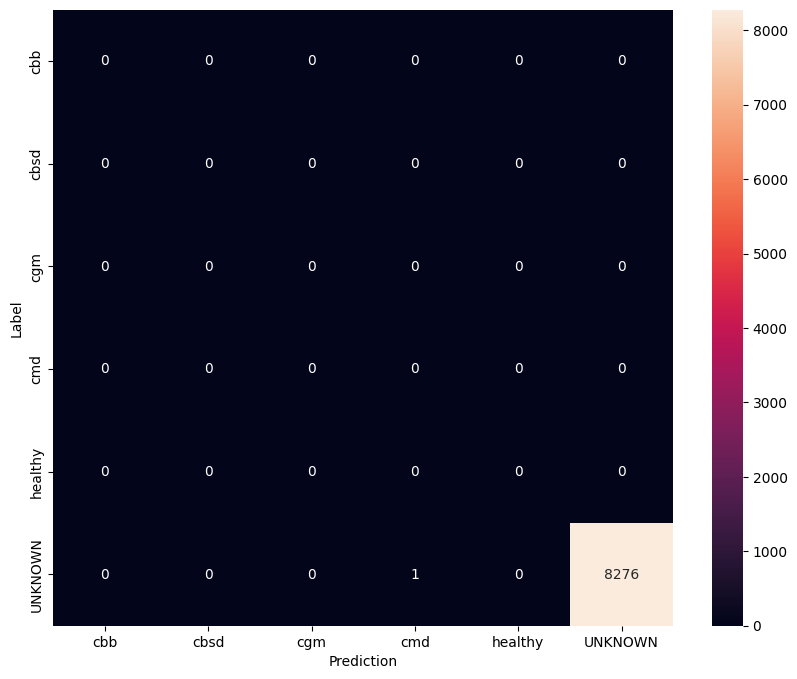
Đánh giá mô hình trên dữ liệu thử nghiệm không xác định
Trong đánh giá này, chúng tôi mong đợi mô hình có độ chính xác gần như bằng 1. Tất cả các hình ảnh mà mô hình được kiểm tra không liên quan đến tập dữ liệu thông thường và do đó chúng tôi mong đợi mô hình dự đoán nhãn lớp "Không xác định".
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
In ma trận nhầm lẫn.
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
Xuất mô hình dưới dạng TFLite và SavedModel
Giờ đây, chúng ta có thể xuất các mô hình được đào tạo ở định dạng TFLite và SavedModel để triển khai trên thiết bị và sử dụng để suy luận trong TensorFlow.
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
Bước tiếp theo
Mô hình mà bạn vừa được đào tạo có thể được sử dụng trên thiết bị di động và thậm chí được triển khai tại hiện trường!
Để tải xuống mô hình, hãy nhấp vào biểu tượng thư mục cho menu Tệp ở phía bên trái của cột và chọn tùy chọn tải xuống.
Kỹ thuật tương tự được sử dụng ở đây có thể được áp dụng cho các nhiệm vụ bệnh thực vật khác có thể phù hợp hơn với trường hợp sử dụng của bạn hoặc bất kỳ loại nhiệm vụ phân loại hình ảnh nào khác. Nếu bạn muốn theo dõi và triển khai trên ứng dụng Android, bạn có thể tiếp tục hướng dẫn bắt đầu nhanh Android này.