
| | |  ดูบน GitHub ดูบน GitHub | | |
สมุดบันทึกนี้แสดงวิธีการ ปรับแต่งโมเดล CropNet จาก TensorFlow Hub บนชุดข้อมูลจาก TFDS หรือชุดข้อมูลการตรวจหาโรคพืชผลของคุณเอง
คุณจะ:
- โหลดชุดข้อมูลมันสำปะหลัง TFDS หรือข้อมูลของคุณเอง
- เสริมข้อมูลด้วยตัวอย่างที่ไม่รู้จัก (เชิงลบ) เพื่อให้ได้โมเดลที่แข็งแกร่งยิ่งขึ้น
- ใช้การเสริมภาพกับข้อมูล
- โหลดและปรับแต่ง โมเดล CropNet จาก TF Hub
- ส่งออกโมเดล TFLite พร้อมที่จะปรับใช้ในแอปของคุณด้วย Task Library , MLKit หรือ TFLite โดยตรง
การนำเข้าและการพึ่งพา
ก่อนเริ่มต้น คุณจะต้องติดตั้งการพึ่งพาบางอย่างที่จำเป็น เช่น Model Maker และ TensorFlow Datasets เวอร์ชันล่าสุด
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
โหลดชุดข้อมูล TFDS เพื่อปรับแต่ง on
ให้ใช้ ชุดข้อมูลโรคใบมันสำปะหลัง ที่เปิดเผยต่อสาธารณะจาก TFDS
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
หรือโหลดข้อมูลของคุณเองเพื่อปรับแต่ง
แทนที่จะใช้ชุดข้อมูล TFDS คุณสามารถฝึกกับข้อมูลของคุณเองได้ ข้อมูลโค้ดนี้แสดงวิธีโหลดชุดข้อมูลที่คุณกำหนดเอง ดูลิงค์ นี้ สำหรับโครงสร้างที่รองรับของข้อมูล ตัวอย่างมีให้ที่นี่โดยใช้ ชุดข้อมูลโรคใบมันสำปะหลัง ที่เปิดเผยต่อสาธารณะ
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
เห็นภาพตัวอย่างจากการแยกรถไฟ
มาดูตัวอย่างจากชุดข้อมูล ซึ่งรวมถึง class id และชื่อ class สำหรับตัวอย่างรูปภาพและป้ายกำกับ
_ = tfds.show_examples(ds_train, ds_info)

เพิ่มรูปภาพเพื่อใช้เป็นตัวอย่างที่ไม่รู้จักจากชุดข้อมูล TFDS
เพิ่มตัวอย่างที่ไม่รู้จัก (เชิงลบ) เพิ่มเติมให้กับชุดข้อมูลการฝึกอบรม และกำหนดหมายเลขป้ายกำกับคลาสที่ไม่รู้จักใหม่ให้กับพวกเขา เป้าหมายคือการมีแบบจำลองที่เมื่อนำไปใช้จริง (เช่น ภาคสนาม) มีตัวเลือกในการทำนาย "ไม่ระบุ" เมื่อเห็นสิ่งที่ไม่คาดคิด
ด้านล่างนี้ คุณสามารถดูรายการชุดข้อมูลที่จะใช้เพื่อสุ่มตัวอย่างภาพที่ไม่รู้จักเพิ่มเติม ประกอบด้วยชุดข้อมูลที่แตกต่างกัน 3 ชุดเพื่อเพิ่มความหลากหลาย หนึ่งในนั้นคือชุดข้อมูลโรคใบถั่ว เพื่อให้แบบจำลองได้สัมผัสกับพืชที่เป็นโรคอื่นที่ไม่ใช่มันสำปะหลัง
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
ชุดข้อมูล UNKNOWN ยังโหลดจาก TFDS
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
สมัครเสริม
สำหรับรูปภาพทั้งหมด เพื่อให้มีความหลากหลายมากขึ้น คุณจะต้องใช้การเสริมบางอย่าง เช่น การเปลี่ยนแปลงใน:
- ความสว่าง
- ตัดกัน
- ความอิ่มตัว
- เว้
- ครอบตัด
การเสริมประเภทนี้ช่วยทำให้โมเดลแข็งแกร่งยิ่งขึ้นต่อการเปลี่ยนแปลงของอินพุตรูปภาพ
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
หากต้องการใช้การเสริม จะใช้วิธี map จากคลาสชุดข้อมูล
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
ห่อข้อมูลให้อยู่ในรูปแบบที่เป็นมิตรของ Model Maker
หากต้องการใช้ชุดข้อมูลเหล่านี้กับ Model Maker จะต้องอยู่ในคลาส ImageClassifierDataLoader
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
ซ้อมวิ่ง
TensorFlow Hub มีหลายรุ่นสำหรับ Transfer Learning
ที่นี่คุณสามารถเลือกหนึ่งรายการและคุณยังสามารถทำการทดลองกับรายการอื่นเพื่อพยายามให้ได้ผลลัพธ์ที่ดีขึ้น
หากคุณต้องการทดลองใช้โมเดลมากขึ้น คุณสามารถเพิ่มได้จาก คอลเล็กชัน นี้
เลือกรุ่นพื้นฐาน
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
ในการปรับแต่งโมเดลอย่างละเอียด คุณจะต้องใช้ Model Maker วิธีนี้ทำให้โซลูชันโดยรวมง่ายขึ้น เนื่องจากหลังจากการฝึกโมเดลแล้ว จะแปลงเป็น TFLite ด้วย
Model Maker ทำให้การแปลงนี้ดีที่สุดเท่าที่จะเป็นไปได้และมีข้อมูลที่จำเป็นทั้งหมดเพื่อให้ปรับใช้โมเดลบนอุปกรณ์ได้อย่างง่ายดายในภายหลัง
ข้อมูลจำเพาะของรุ่นคือวิธีที่คุณบอก Model Maker ว่าคุณต้องการใช้รุ่นพื้นฐานใด
image_model_spec = ModelSpec(uri=model_handle)
รายละเอียดสำคัญประการหนึ่งที่นี่คือการตั้งค่า train_whole_model ซึ่งจะทำให้โมเดลพื้นฐานได้รับการปรับแต่งในระหว่างการฝึก ทำให้กระบวนการช้าลง แต่รุ่นสุดท้ายมีความแม่นยำสูงกว่า การตั้งค่าการ shuffle จะทำให้แน่ใจว่าโมเดลเห็นข้อมูลในลำดับการสุ่มซึ่งเป็นแนวทางปฏิบัติที่ดีที่สุดสำหรับการเรียนรู้แบบจำลอง
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
ประเมินแบบจำลองในการทดสอบแยก
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
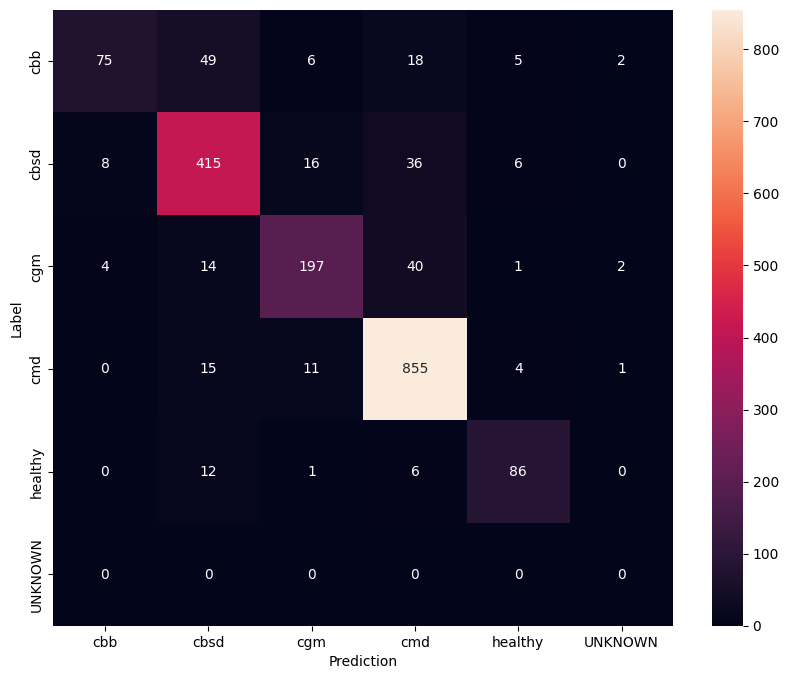
เพื่อให้เข้าใจโมเดลที่ปรับแต่งได้ดียิ่งขึ้น การวิเคราะห์เมทริกซ์ความสับสนจึงเป็นการดี สิ่งนี้จะแสดงให้เห็นว่าคลาสหนึ่งถูกคาดการณ์ว่าเป็นอีกคลาสหนึ่งบ่อยเพียงใด
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
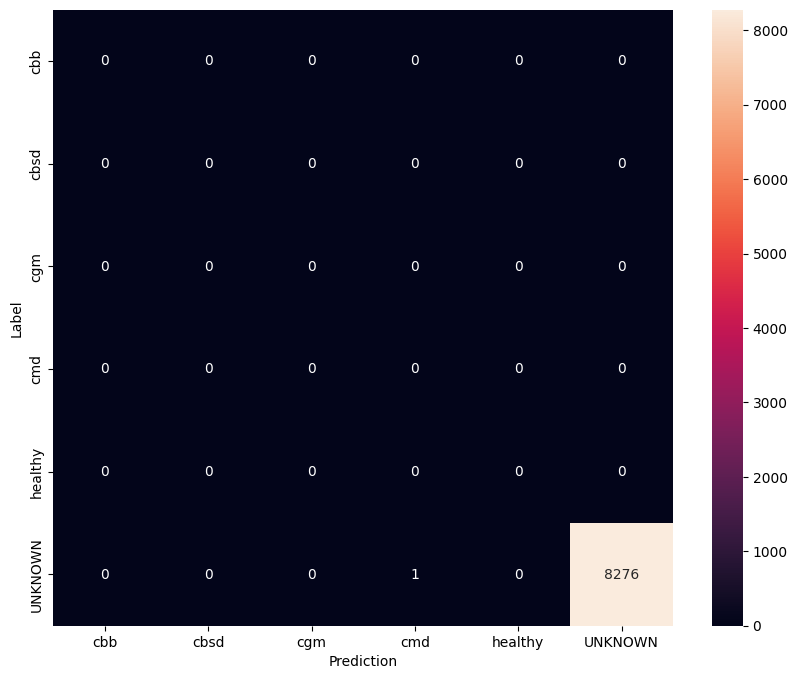
ประเมินแบบจำลองบนข้อมูลการทดสอบที่ไม่รู้จัก
ในการประเมินนี้ เราคาดว่าแบบจำลองจะมีความแม่นยำเกือบ 1 ภาพทั้งหมดที่มีการทดสอบแบบจำลองนั้นไม่เกี่ยวข้องกับชุดข้อมูลปกติ ดังนั้นเราจึงคาดว่าแบบจำลองจะคาดการณ์ป้ายกำกับคลาส "ไม่ทราบ"
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]ตัวยึดตำแหน่ง23
พิมพ์เมทริกซ์ความสับสน
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
ส่งออกโมเดลเป็น TFLite และ SavedModel
ตอนนี้ เราสามารถส่งออกโมเดลที่ผ่านการฝึกอบรมในรูปแบบ TFLite และ SavedModel สำหรับการปรับใช้บนอุปกรณ์และใช้สำหรับอนุมานใน TensorFlow
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
ขั้นตอนถัดไป
โมเดลที่คุณเพิ่งฝึกมานั้นสามารถใช้ได้บนอุปกรณ์พกพาและแม้กระทั่งใช้งานภาคสนาม!
ในการดาวน์โหลดโมเดล ให้คลิกไอคอนโฟลเดอร์สำหรับเมนูไฟล์ทางด้านซ้ายของ colab แล้วเลือกตัวเลือกการดาวน์โหลด
เทคนิคเดียวกับที่ใช้ในที่นี้สามารถนำไปใช้กับงานโรคพืชอื่นๆ ที่อาจเหมาะสมกับกรณีการใช้งานของคุณหรืองานจำแนกประเภทภาพอื่นๆ หากคุณต้องการติดตามและทำให้ใช้งานได้บนแอป Android คุณสามารถดำเนินการต่อใน คู่มือเริ่มต้นอย่างรวดเร็วของ Android