
| | |  Lihat di GitHub Lihat di GitHub | | |
Notebook ini menunjukkan cara menyempurnakan model CropNet dari TensorFlow Hub pada set data dari TFDS atau set data deteksi penyakit tanaman Anda sendiri.
Kamu akan:
- Muat dataset singkong TFDS atau data Anda sendiri
- Perkaya data dengan contoh yang tidak diketahui (negatif) untuk mendapatkan model yang lebih kuat
- Terapkan augmentasi gambar ke data
- Muat dan sempurnakan model CropNet dari TF Hub
- Ekspor model TFLite, siap untuk diterapkan di aplikasi Anda dengan Perpustakaan Tugas , MLKit , atau TFLite secara langsung
Impor dan Ketergantungan
Sebelum memulai, Anda harus menginstal beberapa dependensi yang akan dibutuhkan seperti Model Maker dan versi terbaru dari TensorFlow Datasets.
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
Muat set data TFDS untuk menyempurnakan
Mari gunakan dataset Penyakit Daun Singkong yang tersedia untuk umum dari TFDS.
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
Atau sebagai alternatif, muat data Anda sendiri untuk menyempurnakannya
Alih-alih menggunakan kumpulan data TFDS, Anda juga dapat melatih data Anda sendiri. Cuplikan kode ini menunjukkan cara memuat kumpulan data khusus Anda sendiri. Lihat tautan ini untuk struktur data yang didukung. Sebuah contoh diberikan di sini menggunakan dataset Penyakit Daun Singkong yang tersedia untuk umum.
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
Visualisasikan sampel dari kereta split
Mari kita lihat beberapa contoh dari dataset termasuk id kelas dan nama kelas untuk sampel gambar dan labelnya.
_ = tfds.show_examples(ds_train, ds_info)

Tambahkan gambar untuk digunakan sebagai contoh Tidak Diketahui dari kumpulan data TFDS
Tambahkan contoh tambahan yang tidak diketahui (negatif) ke set data pelatihan dan tetapkan nomor label kelas baru yang tidak diketahui kepada mereka. Tujuannya adalah untuk memiliki model yang, ketika digunakan dalam praktik (misalnya di lapangan), memiliki opsi untuk memprediksi "Tidak Diketahui" ketika melihat sesuatu yang tidak terduga.
Di bawah ini Anda dapat melihat daftar kumpulan data yang akan digunakan untuk mengambil sampel citra tambahan yang tidak diketahui. Ini mencakup 3 set data yang sama sekali berbeda untuk meningkatkan keragaman. Salah satunya adalah dataset penyakit daun buncis, sehingga model memiliki keterpaparan terhadap tanaman sakit selain singkong.
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
Kumpulan data UNKNOWN juga dimuat dari TFDS.
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
Terapkan augmentasi
Untuk semua gambar, agar lebih beragam, Anda akan menerapkan beberapa augmentasi, seperti perubahan pada:
- Kecerahan
- Kontras
- Kejenuhan
- Warna
- Tanaman
Jenis augmentasi ini membantu membuat model lebih kuat terhadap variasi input gambar.
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
Untuk menerapkan augmentasi, ia menggunakan metode map dari kelas Dataset.
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
Bungkus data ke dalam format ramah Model Maker
Untuk menggunakan set data ini dengan Model Maker, mereka harus berada di kelas ImageClassifierDataLoader.
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
Jalankan pelatihan
TensorFlow Hub memiliki beberapa model yang tersedia untuk Transfer Learning.
Di sini Anda dapat memilih satu dan Anda juga dapat terus bereksperimen dengan yang lain untuk mencoba mendapatkan hasil yang lebih baik.
Jika Anda ingin lebih banyak model untuk dicoba, Anda dapat menambahkannya dari koleksi ini .
Pilih model dasar
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
Untuk menyempurnakan model, Anda akan menggunakan Model Maker. Ini membuat solusi keseluruhan lebih mudah karena setelah pelatihan model, itu juga akan mengubahnya menjadi TFLite.
Model Maker membuat konversi ini menjadi yang terbaik dan dengan semua informasi yang diperlukan untuk menerapkan model di perangkat dengan mudah nanti.
Spesifikasi model adalah cara Anda memberi tahu Model Maker model dasar mana yang ingin Anda gunakan.
image_model_spec = ModelSpec(uri=model_handle)
Satu detail penting di sini adalah menyetel train_whole_model yang akan membuat model dasar disetel dengan baik selama pelatihan. Ini membuat proses lebih lambat tetapi model akhir memiliki akurasi yang lebih tinggi. Mengatur shuffle akan memastikan model melihat data dalam urutan acak acak yang merupakan praktik terbaik untuk pembelajaran model.
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
Evaluasi model pada uji split
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
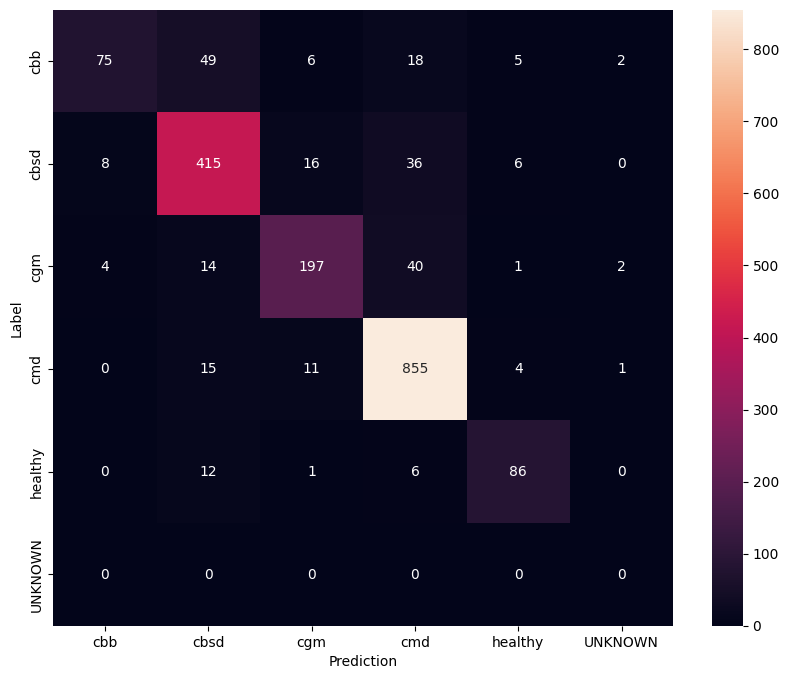
Untuk memiliki pemahaman yang lebih baik tentang model yang disetel dengan baik, ada baiknya untuk menganalisis matriks kebingungan. Ini akan menunjukkan seberapa sering satu kelas diprediksi sebagai yang lain.
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
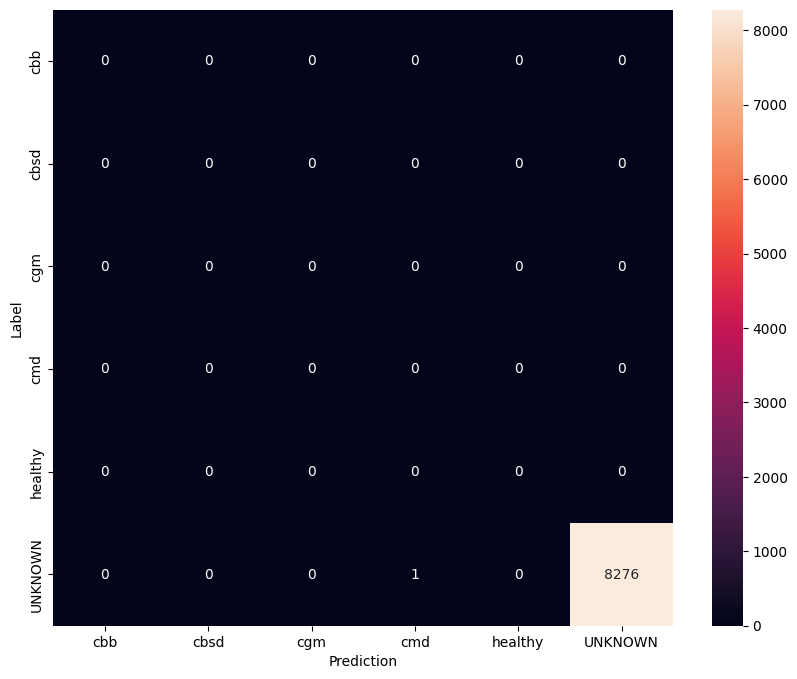
Evaluasi model pada data uji yang tidak diketahui
Dalam evaluasi ini kami mengharapkan model memiliki akurasi hampir 1. Semua gambar model yang diuji tidak terkait dengan dataset normal dan oleh karena itu kami mengharapkan model untuk memprediksi label kelas "Tidak Diketahui".
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
Cetak matriks kebingungan.
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
Ekspor model sebagai TFLite dan SavedModel
Sekarang kita dapat mengekspor model terlatih dalam format TFLite dan SavedModel untuk diterapkan di perangkat dan digunakan untuk inferensi di TensorFlow.
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
Langkah selanjutnya
Model yang baru saja Anda latih dapat digunakan di perangkat seluler dan bahkan digunakan di lapangan!
Untuk mengunduh model, klik ikon folder untuk menu File di sisi kiri kolab, dan pilih opsi unduh.
Teknik yang sama yang digunakan di sini dapat diterapkan pada tugas penyakit tanaman lain yang mungkin lebih cocok untuk kasus penggunaan Anda atau jenis tugas klasifikasi gambar lainnya. Jika Anda ingin menindaklanjuti dan menerapkan pada aplikasi Android, Anda dapat melanjutkan panduan memulai cepat Android ini .