
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | | |
این نوت بوک به شما نشان می دهد که چگونه مدل های CropNet را از TensorFlow Hub روی مجموعه داده ای از TFDS یا مجموعه داده های تشخیص بیماری محصول خودتان تنظیم کنید.
شما:
- مجموعه داده کاساوا TFDS یا داده های خود را بارگیری کنید
- داده ها را با مثال های ناشناخته (منفی) غنی کنید تا مدل قوی تری به دست آورید
- افزایش تصویر را روی داده ها اعمال کنید
- یک مدل CropNet را از TF Hub بارگیری و تنظیم دقیق کنید
- یک مدل TFLite را صادر کنید، آماده استقرار در برنامه شما با Task Library ، MLKit یا TFLite به طور مستقیم
واردات و وابستگی ها
قبل از شروع، باید برخی از وابستگیهای مورد نیاز مانند Model Maker و آخرین نسخه TensorFlow Datasets را نصب کنید.
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
یک مجموعه داده TFDS را برای تنظیم دقیق بارگذاری کنید
اجازه میدهیم از مجموعه دادههای بیماری برگ Cassava در دسترس عموم از TFDS استفاده کنیم.
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
یا به طور متناوب داده های خود را برای تنظیم دقیق بارگیری کنید
به جای استفاده از مجموعه داده TFDS، می توانید بر روی داده های خود نیز آموزش دهید. این قطعه کد نحوه بارگیری مجموعه داده سفارشی خود را نشان می دهد. برای مشاهده ساختار پشتیبانی شده داده ها به این پیوند مراجعه کنید. یک مثال در اینجا با استفاده از مجموعه داده بیماری برگ Cassava در دسترس عموم ارائه شده است.
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
نمونه هایی از تقسیم قطار را تجسم کنید
بیایید به چند نمونه از مجموعه داده از جمله شناسه کلاس و نام کلاس برای نمونه های تصویر و برچسب های آنها نگاهی بیندازیم.
_ = tfds.show_examples(ds_train, ds_info)

تصاویر را برای استفاده به عنوان نمونه های ناشناخته از مجموعه داده های TFDS اضافه کنید
نمونه های ناشناخته (منفی) اضافی را به مجموعه داده آموزشی اضافه کنید و یک شماره برچسب کلاس ناشناخته جدید به آنها اختصاص دهید. هدف این است که مدلی داشته باشیم که وقتی در عمل از آن استفاده میشود (مثلاً در میدان)، گزینه پیشبینی «ناشناخته» را در صورت مشاهده چیز غیرمنتظره داشته باشد.
در زیر میتوانید فهرستی از مجموعه دادهها را مشاهده کنید که برای نمونهبرداری از تصاویر ناشناخته اضافی استفاده میشوند. این شامل 3 مجموعه داده کاملاً متفاوت برای افزایش تنوع است. یکی از آنها مجموعه داده بیماری برگ لوبیا است، به طوری که مدل در معرض گیاهان بیمار دیگری غیر از کاساوا قرار دارد.
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
مجموعه داده های ناشناخته نیز از TFDS بارگیری می شوند.
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
افزایش ها را اعمال کنید
برای همه تصاویر، برای اینکه آنها را متنوع تر کنید، مقداری تقویت مانند تغییرات در موارد زیر را اعمال خواهید کرد:
- روشنایی
- تضاد
- اشباع
- رنگ
- برش
این نوع تقویتها به قویتر شدن مدل در برابر تغییرات ورودیهای تصویر کمک میکنند.
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
برای اعمال افزایش، از روش map از کلاس Dataset استفاده می کند.
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
داده ها را در قالب مدل ساز دوستانه قرار دهید
برای استفاده از این مجموعه داده ها با Model Maker، باید در کلاس ImageClassifierDataLoader باشند.
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
آموزش اجرا کنید
TensorFlow Hub چندین مدل برای آموزش انتقال دارد.
در اینجا میتوانید یکی را انتخاب کنید و همچنین میتوانید با آزمایشهای دیگر ادامه دهید تا نتایج بهتری بگیرید.
اگر می خواهید مدل های بیشتری را امتحان کنید، می توانید آنها را از این مجموعه اضافه کنید.
یک مدل پایه انتخاب کنید
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
برای تنظیم دقیق مدل، از Model Maker استفاده خواهید کرد. این راه حل کلی را آسان تر می کند زیرا پس از آموزش مدل، آن را به TFLite نیز تبدیل می کند.
Model Maker باعث میشود که این تبدیل به بهترین شکل ممکن و با تمام اطلاعات لازم باشد تا بعداً به راحتی مدل را روی دستگاه مستقر کنید.
مشخصات مدل این است که چگونه به Model Maker میگویید از کدام مدل پایه میخواهید استفاده کنید.
image_model_spec = ModelSpec(uri=model_handle)
یکی از جزئیات مهم در اینجا تنظیم train_whole_model است که باعث میشود مدل پایه در طول آموزش به خوبی تنظیم شود. این روند را کندتر می کند اما مدل نهایی دقت بالاتری دارد. تنظیم در هم shuffle اطمینان حاصل می کند که مدل داده ها را به ترتیب تصادفی می بیند که بهترین روش برای یادگیری مدل است.
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
ارزیابی مدل در تقسیم آزمون
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
برای درک بهتر از مدل تنظیم شده، خوب است که ماتریس سردرگمی را تجزیه و تحلیل کنید. این نشان می دهد که چند بار یک کلاس به عنوان کلاس دیگر پیش بینی می شود.
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
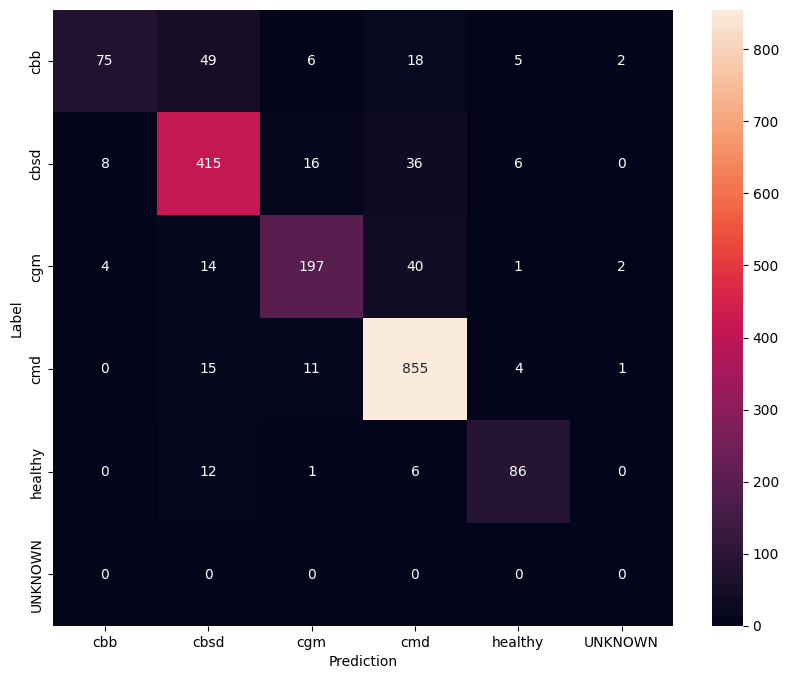
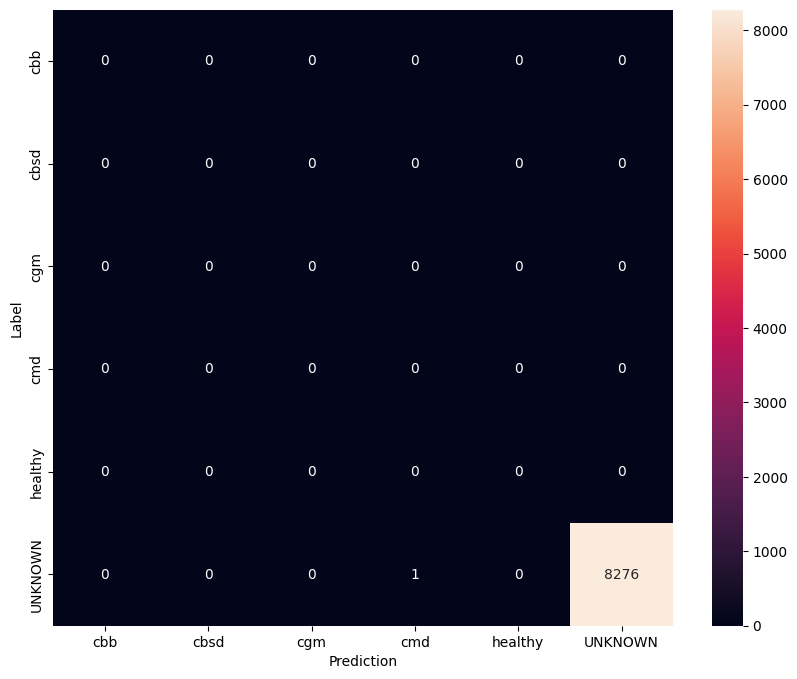
ارزیابی مدل بر روی داده های تست ناشناخته
در این ارزیابی ما انتظار داریم که دقت مدل تقریباً 1 باشد. تمام تصاویری که مدل روی آنها آزمایش میشود به مجموعه دادههای معمولی مرتبط نیستند و از این رو انتظار داریم که مدل برچسب کلاس "ناشناخته" را پیشبینی کند.
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
ماتریس سردرگمی را چاپ کنید.
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
مدل را به عنوان TFLite و SavedModel صادر کنید
اکنون میتوانیم مدلهای آموزشدیده را در قالبهای TFLite و SavedModel برای استقرار روی دستگاه و استفاده برای استنتاج در TensorFlow صادر کنیم.
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
مراحل بعدی
مدلی که شما به تازگی آموزش داده اید را می توان در دستگاه های تلفن همراه استفاده کرد و حتی در این زمینه مستقر کرد!
برای دانلود مدل، روی نماد پوشه منوی Files در سمت چپ کولب کلیک کنید و گزینه دانلود را انتخاب کنید.
تکنیک مشابهی که در اینجا استفاده میشود میتواند برای سایر وظایف بیماریهای گیاهی که ممکن است برای موارد استفاده شما یا هر نوع کار طبقهبندی تصویر دیگری مناسبتر باشد، اعمال شود. اگر میخواهید یک برنامه Android را پیگیری و اجرا کنید، میتوانید این راهنمای شروع سریع Android را ادامه دهید.