
| | |  Xem trên GitHub Xem trên GitHub | |
Colab này là một minh chứng của việc sử dụng Tensorflow Hub phân loại văn bản trong không phải tiếng Anh / ngôn ngữ địa phương. Ở đây chúng ta chọn Bangla là ngôn ngữ địa phương và sử dụng pretrained embeddings từ để giải quyết một nhiệm vụ phân loại nhiều lớp mà chúng tôi phân loại các bài báo Bangla trong 5 loại. Các embeddings pretrained cho Bangla đến từ fastText mà là một thư viện bằng Facebook với phát hành vectơ từ pretrained cho 157 ngôn ngữ.
Chúng tôi sẽ sử dụng pretrained xuất khẩu nhúng TF-Hub cho chuyển đổi embeddings từ để một module văn bản nhúng đầu tiên và sau đó sử dụng các mô-đun để đào tạo một phân loại với tf.keras , trình độ cao người dùng thân thiện API Tensorflow để xây dựng mô hình học sâu. Ngay cả khi chúng tôi đang sử dụng nhúng fastText ở đây, bạn vẫn có thể xuất bất kỳ nhúng nào khác được đào tạo trước từ các tác vụ khác và nhanh chóng nhận được kết quả với trung tâm Tensorflow.
Thành lập
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Dataset
Chúng tôi sẽ sử dụng NHNN & PTNT (Bangla Điều Dataset) trong đó có khoảng 376.226 bài báo thu thập được từ các cổng tin tức khác nhau Bangla và dán nhãn với 5 loại: nền kinh tế, nhà nước, quốc tế, thể thao, vui chơi giải trí. Chúng tôi tải về các tập tin từ Google Drive này ( bit.ly/BARD_DATASET ) liên kết được đề cập đến từ này kho GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Xuất vectơ từ được đào tạo trước sang mô-đun TF-Hub
TF-Hub cung cấp một số kịch bản hữu ích để chuyển đổi embeddings từ để TF-hub module văn bản nhúng ở đây . Để thực hiện các mô-đun cho Bangla hoặc bất kỳ ngôn ngữ khác, chúng ta chỉ cần phải tải về từ nhúng .txt hoặc .vec tập tin vào thư mục tương tự như export_v2.py và chạy kịch bản.
Các nhà xuất khẩu lần đọc các vectơ nhúng và xuất khẩu nó vào một Tensorflow SavedModel . SavedModel chứa một chương trình TensorFlow hoàn chỉnh bao gồm trọng số và đồ thị. TF-Hub có thể tải các SavedModel như một mô-đun , mà chúng tôi sẽ sử dụng để xây dựng các mô hình để phân loại văn bản. Vì chúng ta đang sử dụng tf.keras để xây dựng mô hình, chúng tôi sẽ sử dụng hub.KerasLayer , cung cấp một wrapper cho một module TF-Hub để sử dụng như một lớp Keras.
Đầu tiên chúng ta sẽ nhận được embeddings từ của chúng tôi từ fastText và nhúng nước xuất khẩu từ TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Sau đó, chúng tôi sẽ chạy tập lệnh xuất khẩu trên tệp nhúng của chúng tôi. Vì nhúng fastText có dòng tiêu đề và khá lớn (khoảng 3,3 GB cho Bangla sau khi chuyển đổi thành mô-đun) nên chúng tôi bỏ qua dòng đầu tiên và chỉ xuất 100.000 mã thông báo đầu tiên sang mô-đun nhúng văn bản.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Mô-đun nhúng văn bản lấy một loạt các câu trong chuỗi chuỗi 1D làm đầu vào và đầu ra các vectơ nhúng có hình dạng (batch_size, embedding_dim) tương ứng với các câu. Nó xử lý trước đầu vào bằng cách chia nhỏ trên các khoảng trắng. Embeddings từ được kết hợp để embeddings câu với sqrtn bộ kết hợp (Xem ở đây ). Để trình diễn, chúng tôi chuyển một danh sách các từ Bangla làm đầu vào và nhận các vectơ nhúng tương ứng.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Chuyển đổi sang Tập dữ liệu Tensorflow
Kể từ khi tập dữ liệu thực sự lớn thay vì tải toàn bộ dữ liệu trong bộ nhớ chúng ta sẽ sử dụng một máy phát điện để mang mẫu trong thời gian chạy theo lô sử dụng Tensorflow Dataset chức năng. Tập dữ liệu cũng rất mất cân bằng, vì vậy, trước khi sử dụng trình tạo, chúng ta sẽ xáo trộn tập dữ liệu.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Chúng tôi có thể kiểm tra việc phân phối các nhãn trong các ví dụ đào tạo và xác thực sau khi xáo trộn.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
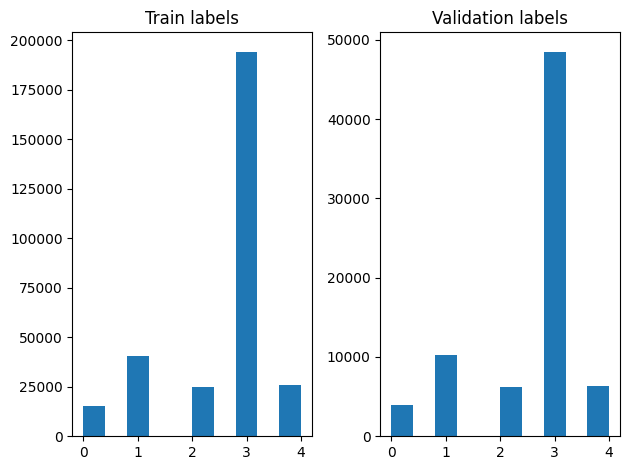
Để tạo một Dataset sử dụng một máy phát điện, đầu tiên chúng ta viết một hàm máy phát điện mà đọc mỗi bài viết từ file_paths và các nhãn từ mảng nhãn, và sản lượng ví dụ một đào tạo tại mỗi bước. Chúng tôi vượt qua chức năng máy phát điện này đến tf.data.Dataset.from_generator phương pháp và chỉ định các loại đầu ra. Mỗi ví dụ đào tạo là một tuple chứa một bài báo của tf.string kiểu dữ liệu và một phần nóng nhãn mã hóa. Chúng tôi chia các tập dữ liệu với một sự chia rẽ tàu cao xác nhận của 80-20 sử dụng tf.data.Dataset.skip và tf.data.Dataset.take phương pháp.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Đào tạo và Đánh giá Mô hình
Kể từ khi chúng tôi đã thêm một wrapper xung quanh mô-đun của chúng tôi để sử dụng nó như bất kỳ lớp khác trong Keras, chúng ta có thể tạo ra một nhỏ tuần tự mô hình mà là một đống tuyến tính của lớp. Chúng ta có thể thêm văn bản mô-đun nhúng của chúng tôi với model.add giống như bất kỳ lớp khác. Chúng tôi biên dịch mô hình bằng cách chỉ định mất mát và trình tối ưu hóa và đào tạo nó trong 10 kỷ nguyên. Các tf.keras API có thể xử lý Tensorflow Datasets như đầu vào, vì vậy chúng tôi có thể vượt qua một trường hợp Dataset với phương pháp phù hợp cho đào tạo người mẫu. Vì chúng ta đang sử dụng các chức năng máy phát điện, tf.data sẽ xử lý tạo ra các mẫu, Trạm trộn chúng và cho chúng ăn với mô hình.
Mô hình
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Tập huấn
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Đánh giá
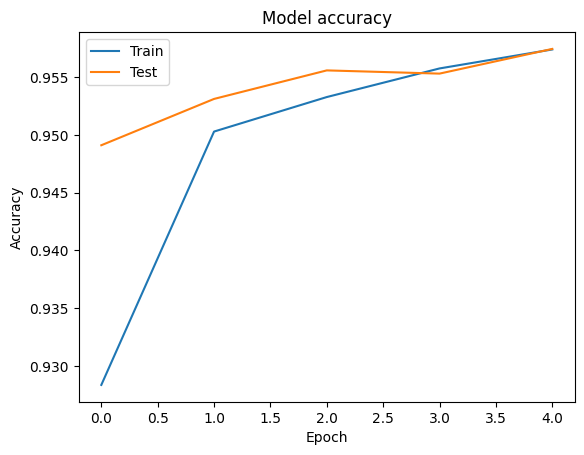
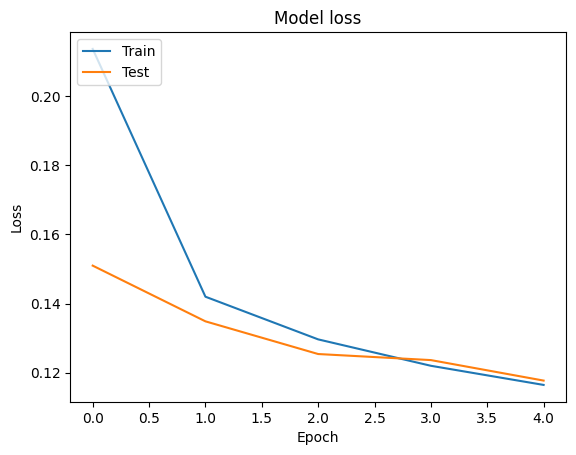
Chúng ta có thể hình dung các đường cong chính xác và mất mát cho đào tạo và xác nhận dữ liệu bằng cách sử dụng tf.keras.callbacks.History đối tượng được trả về bởi các tf.keras.Model.fit phương pháp, trong đó có sự mất mát và độ chính xác giá trị cho mỗi thời đại.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Sự dự đoán
Chúng ta có thể lấy các dự đoán cho dữ liệu xác thực và kiểm tra ma trận nhầm lẫn để xem hiệu suất của mô hình cho từng lớp trong số 5 lớp. Bởi vì tf.keras.Model.predict phương thức trả về một mảng thứ cho xác suất cho mỗi lớp, họ có thể được chuyển đổi sang nhãn lớp bằng np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
So sánh hiệu suất
Bây giờ chúng ta có thể lấy nhãn chính xác cho các dữ liệu xác nhận từ labels và so sánh chúng với những dự đoán của chúng tôi để có được một classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Chúng tôi cũng có thể so sánh hiệu suất mô hình của chúng tôi với kết quả công bố thu được trong bản gốc giấy , trong đó có một 0,96 chính xác .Công tác giả ban đầu được mô tả nhiều bước tiền xử lý được thực hiện trên các tập dữ liệu, chẳng hạn như giảm punctuations và chữ số, loại bỏ top 25 hầu hết các từ dừng frequest. Như chúng ta có thể thấy trong classification_report , chúng tôi cũng quản lý để có được một độ chính xác 0,96 và độ chính xác sau khi đào tạo chỉ 5 kỷ nguyên mà không cần bất kỳ tiền xử lý!
Trong ví dụ này, khi chúng tôi tạo ra lớp Keras từ mô-đun nhúng của chúng tôi, chúng tôi thiết lập các thông số trainable=False , có nghĩa là các trọng nhúng sẽ không được cập nhật trong thời gian đào tạo. Hãy thử thiết lập nó để True đạt khoảng 97% độ chính xác sử dụng số liệu này chỉ sau 2 kỷ nguyên.