
| | |  Zobacz na GitHub Zobacz na GitHub | |
Ten Colab jest wykazanie za pomocą Tensorflow Hub klasyfikacji tekstu w nieanglojęzycznych / języków lokalnych. Tutaj możemy wybrać Bangla jako lokalnego języka i używać pretrained zanurzeń słowo rozwiązać multiclass zadanie klasyfikacji gdzie klasyfikowania Bangla artykuły prasowe w 5 kategoriach. W pretrained zanurzeń do Bangla pochodzi z Fasttekst który jest biblioteką przez Facebook z uwolnionych pretrained wektorów słowo na 157 języków.
Użyjemy pretrained eksportera osadzania TF-Hub do konwersji zanurzeń haseł do modułu tekstowego osadzanie, a następnie użyć modułu trenować klasyfikator z tf.keras , Tensorflow za wysoki poziom przyjazny dla użytkownika interfejs API do budowania głębokich modele uczenia się. Nawet jeśli używamy tutaj osadzania fastText, możliwe jest wyeksportowanie wszelkich innych osadzeń wstępnie wyszkolonych z innych zadań i szybkie uzyskanie wyników dzięki koncentratorowi Tensorflow.
Ustawiać
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Zbiór danych
Użyjemy Bard (Bangla Artykuł zestawu danych), która ma około 376.226 artykuły zebrane z różnych portali informacyjnych Bangla i znakowane z 5 kategorii: Gospodarka, państwa, międzynarodowy, sportu i rozrywki. Mamy pobrać plik z Dysku Google to ( bit.ly/BARD_DATASET ) łącza się odnosi z tego repozytorium GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Eksportuj wytrenowane wektory słów do modułu TF-Hub
TF-Hub udostępnia kilka przydatnych skryptów do konwersji zanurzeń haseł do TF-piast modułów osadzania tekst tutaj . Aby modułu do Bangla lub w jakimkolwiek innym języku, po prostu trzeba pobrać słowo osadzania .txt lub .vec plik w tym samym katalogu co export_v2.py i uruchom skrypt.
Eksporter czyta wektory zatapiania i eksportuje je do Tensorflow SavedModel . SavedModel zawiera kompletny program TensorFlow, w tym wagi i wykres. TF-Hub może załadować SavedModel jako moduł , którego użyjemy do budowy modelu klasyfikacji tekstu. Ponieważ używamy tf.keras do budowy modelu, będziemy używać hub.KerasLayer , która zapewnia otoki dla modułu TF-Hub do stosowania jako warstwa Keras.
Po pierwsze będziemy mieli nasze zanurzeń słowo z Fasttekst i osadzanie eksportera z TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Następnie uruchomimy skrypt eksportera na naszym pliku osadzania. Ponieważ osadzania fastText mają wiersz nagłówka i są dość duże (około 3,3 GB dla Bangla po konwersji na moduł), ignorujemy pierwszy wiersz i eksportujemy tylko pierwsze 100 000 tokenów do modułu osadzania tekstu.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Moduł osadzania tekstu pobiera partię zdań w tensorze jednowymiarowym ciągów jako dane wejściowe i wyprowadza wektory osadzania o kształcie (batch_size, embedding_dim) odpowiadające zdaniu. Wstępnie przetwarza dane wejściowe, dzieląc je na spacje. Zanurzeń Word są połączone do zanurzeń zdanie mające sqrtn sumator (zobacz tutaj ). W celu demonstracji przekazujemy listę słów Bangla jako dane wejściowe i otrzymujemy odpowiednie wektory osadzania.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Konwertuj na zbiór danych Tensorflow
Ponieważ zestaw danych jest bardzo duża zamiast załadowanie całego zestawu danych w pamięci będziemy używać generatora w celu uzyskania próbek w czasie wykonywania w partiach z zastosowaniem Tensorflow zestawów danych funkcji. Zestaw danych jest również bardzo niezrównoważony, więc przed użyciem generatora przetasujemy zestaw danych.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Po przetasowaniu możemy sprawdzić rozkład etykiet w przykładach uczących i walidacyjnych.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
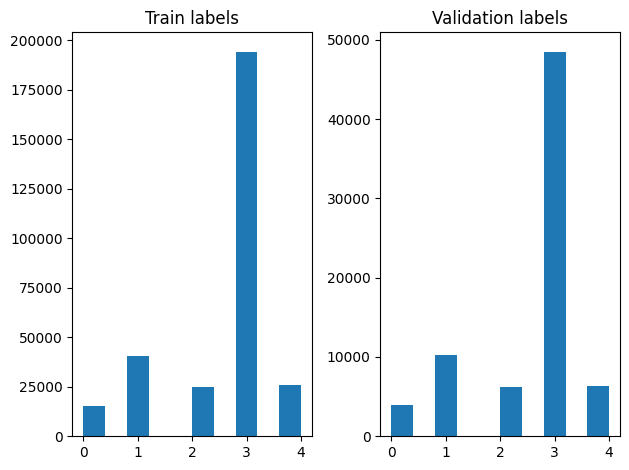
Aby utworzyć zestaw danych przy użyciu generatora, najpierw napisać funkcję generatora, który odczytuje każdy z artykułów z file_paths i etykiet z tablicy etykietę, a plony przykład jeden trening na każdym kroku. Mijamy tę funkcję generatora do tf.data.Dataset.from_generator metody i określić rodzaje wyjściowych. Każdy przykład szkolenie jest krotką zawierający artykuł tf.string typ danych i jedną gorąco zakodowany znacznik. Dzielimy zbiór danych z podziałem na pociąg-walidacji 80-20 wykorzystaniem tf.data.Dataset.skip i tf.data.Dataset.take metod.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Szkolenie i ocena modeli
Ponieważ już dodany do owijki po naszym modułu do wykorzystania go w innych warstw w Keras, można utworzyć małą sekwencyjnego modelu, który jest liniowy, stos warstw. Możemy dodać nasz tekst moduł osadzania z model.add podobnie jak każdej innej warstwie. Kompilujemy model określając stratę i optymalizator i trenujemy go przez 10 epok. tf.keras API może obsłużyć Tensorflow zestawów danych jako dane wejściowe, więc możemy przejść instancję zestawu danych do dopasowania sposobu modelu szkolenia. Skoro jesteśmy przy użyciu funkcji generatora, tf.data zajmie generowania próbek, ich dozowania i podawania ich do modelu.
Model
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Trening
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Ocena
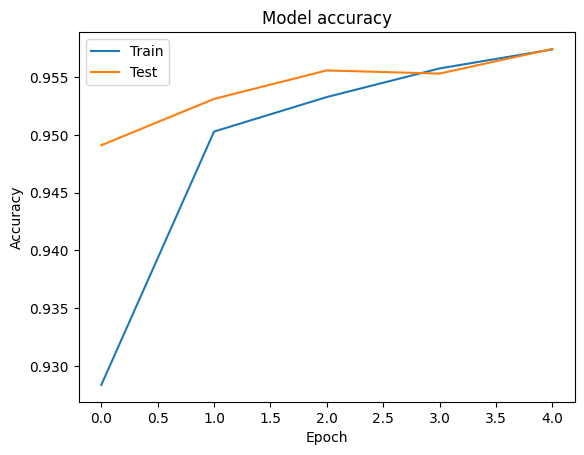
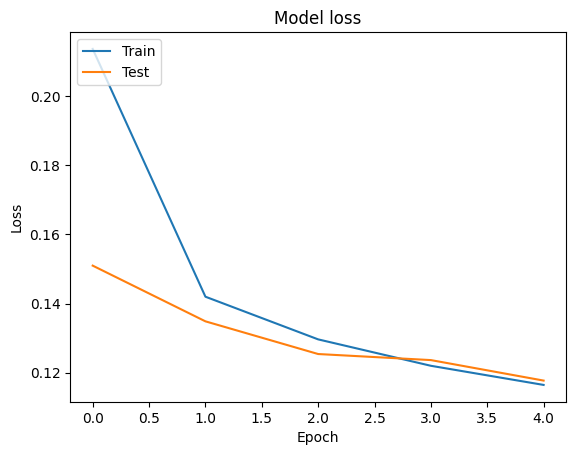
Możemy wyobrazić dokładność i strat krzywe na szkolenia i sprawdzania poprawności danych z wykorzystaniem tf.keras.callbacks.History obiekt zwrócony przez tf.keras.Model.fit metody, która zawiera strat i dokładność wartości dla każdej epoki.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Przepowiednia
Możemy uzyskać prognozy dla danych walidacyjnych i sprawdzić macierz pomyłek, aby zobaczyć wydajność modelu dla każdej z 5 klas. Ze względu tf.keras.Model.predict sposób powraca ND macierz prawdopodobieństw dla każdej klasy, mogą być przekształcone do etykiet klasy przy np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Porównaj wydajność
Teraz możemy podjąć odpowiednie etykiety dla walidacji danych z labels i porównać je z naszymi przewidywaniami, aby uzyskać classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Możemy także porównać skuteczność naszego modelu z opublikowanymi wynikami uzyskanymi w oryginalnym papierze , który miał 0,96 precyzja .Powierzchnia oryginalne Autorzy opisali wiele kroków przerób przeprowadzono na zbiorze danych, takie jak upuszczenie znaki interpunkcyjne i cyfry, usuwając top 25 najbardziej frequest zatrzymania słowa. Jak widzimy w classification_report , również udało się uzyskać 0,96 precyzję i dokładność po treningu tylko 5 epok bez wyprzedzającym!
W tym przykładzie, kiedy stworzyliśmy warstwę Keras z naszego modułu wstawiania, możemy ustawić parametr trainable=False , co oznacza osadzanie ciężary nie będą aktualizowane w czasie treningu. Spróbuj ustawić go na True aby osiągnąć około 97% dokładność przy użyciu tego zestawu danych po zaledwie 2 epok.