
| | |  Visualizza su GitHub Visualizza su GitHub | |
Questo Colab è una dimostrazione di utilizzo di tensorflow Hub per la classificazione testo in non in lingua inglese / lingue locali. Qui scegliamo Bangla come la lingua locale e l'uso preaddestrato incastri di parole per risolvere un compito di classificazione multiclasse dove classifichiamo Bangla articoli di notizie in 5 categorie. Gli incastri preaddestrato per Bangla proviene da fasttext che è una libreria da Facebook con diffusi vettori di parole preaddestrato per 157 lingue.
Useremo esportatore embedding preaddestrato del TF-Hub per convertire la parola incastri ad un modulo di testo embedding prima e poi utilizzare il modulo di formare un classificatore con tf.keras , di alto livello user friendly API tensorflow di costruire modelli di apprendimento profonde. Anche se stiamo usando gli incorporamenti fastText qui, è possibile esportare qualsiasi altro incorporamento preaddestrato da altre attività e ottenere rapidamente risultati con l'hub Tensorflow.
Impostare
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
set di dati
Useremo BARD (Bangla articolo Dataset), che ha circa 376.226 articoli raccolti da diversi portali di notizie Bangla ed etichettati con 5 categorie: economia, Stato, internazionale, sport e intrattenimento. Scarichiamo il file da Google Drive questo ( bit.ly/BARD_DATASET link) si riferisce a da questo repository GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Esporta vettori di parole preaddestrati nel modulo TF-Hub
TF-Hub fornisce alcuni script utili per la conversione di incastri parola ai moduli di testo all'incorporamento TF-hub qui . Per rendere il modulo per il Bangla o di altre lingue, dobbiamo semplicemente scaricare la parola embedding .txt o .vec file nella stessa directory export_v2.py ed eseguire lo script.
L'esportatore legge i vettori embedding ed esporta in un tensorflow SavedModel . Un SavedModel contiene un programma TensorFlow completo che include pesi e grafico. TF-Hub può caricare il SavedModel come un modulo , che useremo per costruire il modello per la classificazione del testo. Dal momento che stiamo usando tf.keras per costruire il modello, useremo hub.KerasLayer , che fornisce un wrapper per un modulo TF-Hub per l'uso come strato Keras.
In primo luogo avremo i nostri incastri di parole da fasttext ed esportatori embedding da TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Quindi, eseguiremo lo script di esportazione sul nostro file di incorporamento. Poiché gli incorporamenti fastText hanno una riga di intestazione e sono piuttosto grandi (circa 3,3 GB per Bangla dopo la conversione in un modulo), ignoriamo la prima riga ed esportiamo solo i primi 100.000 token nel modulo di incorporamento del testo.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Il modulo di incorporamento del testo prende un batch di frasi in un tensore 1D di stringhe come input ed emette i vettori di forma di incorporamento (batch_size, embedding_dim) corrispondenti alle frasi. Pre-elabora l'input suddividendolo in spazi. Embeddings Word sono combinati per incastri frase con la sqrtn combinatore (vedi qui ). Per dimostrazione passiamo un elenco di parole Bangla come input e otteniamo i corrispondenti vettori di incorporamento.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Converti in set di dati Tensorflow
Poiché il set di dati è molto grande invece di caricare l'intero set di dati nella memoria useremo un generatore per produrre campioni in fase di esecuzione in batch utilizzando tensorflow Dataset funzioni. Anche il set di dati è molto sbilanciato, quindi, prima di utilizzare il generatore, mescoleremo il set di dati.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Possiamo controllare la distribuzione delle etichette negli esempi di addestramento e convalida dopo aver mescolato.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
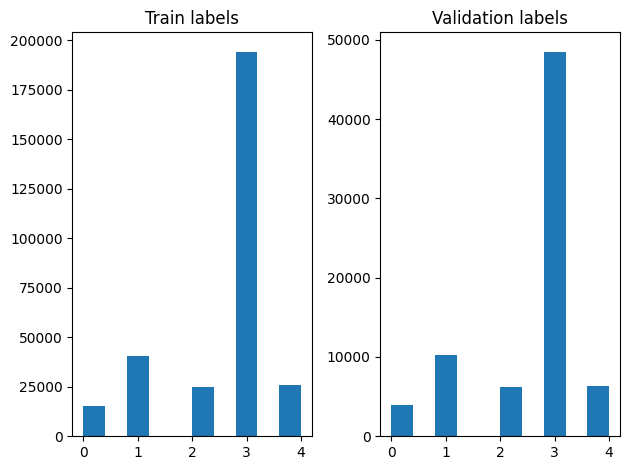
Per creare un set di dati utilizzando un generatore, per prima scrivere una funzione generatore che legge ciascuno degli articoli da file_paths e le etichette dalla matrice etichetta, e le rese esempio una formazione ad ogni passo. Passiamo questa funzione generatore al tf.data.Dataset.from_generator metodo e specificare i tipi di output. Ogni esempio formazione è una tupla contenente un articolo di tf.string tipo di dati ed etichetta codificata uno incandescente. Abbiamo diviso il set di dati con una spaccatura treno-validazione di 80-20 usando tf.data.Dataset.skip e tf.data.Dataset.take metodi.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Formazione e valutazione del modello
Poiché abbiamo già aggiunto un involucro intorno al nostro modulo di usarlo come qualsiasi altro strato in Keras, possiamo creare un piccolo sequenziale modello che è una pila di strati lineare. Siamo in grado di aggiungere il nostro modulo di inclusione di testo con model.add proprio come qualsiasi altro livello. Compiliamo il modello specificando la perdita e l'ottimizzatore e lo addestriamo per 10 epoche. Il tf.keras API supporta tensorflow set di dati in ingresso, in modo da poter passare un'istanza Dataset al metodo idoneo per l'addestramento del modello. Poiché stiamo usando la funzione di generatore, tf.data gestirà generare gli esempi, il dosaggio ed alimentarli al modello.
Modello
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Formazione
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Valutazione
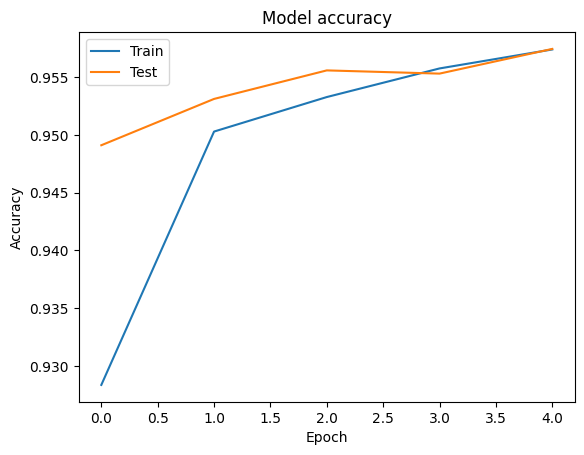
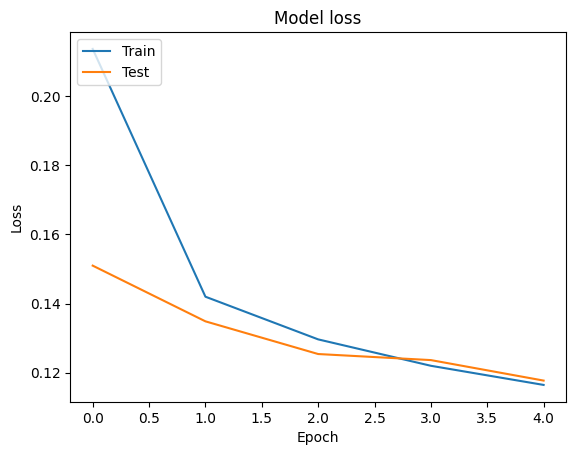
Possiamo visualizzare le curve di precisione e perdite dati di addestramento e di validazione utilizzando la tf.keras.callbacks.History oggetto restituito dal tf.keras.Model.fit metodo, che contiene il valore di perdita e precisione per ogni epoca.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Predizione
Possiamo ottenere le previsioni per i dati di convalida e controllare la matrice di confusione per vedere le prestazioni del modello per ciascuna delle 5 classi. Poiché tf.keras.Model.predict metodo restituisce un array nd per le probabilità per ciascuna classe, possono essere convertiti in etichette di classe utilizzando np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Confronta le prestazioni
Ora siamo in grado di prendere le etichette corrette per la validazione dei dati da labels e confrontarli con le nostre previsioni per ottenere un classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Possiamo anche confrontare le prestazioni del nostro modello con i risultati pubblicati ottenuti in originale della carta , che ha avuto un 0,96 precisione .Gli autori originali descritti molti passaggi di pre-elaborazione eseguita sul set di dati, ad esempio l'eliminazione punteggiatura e cifre, eliminando I 25 più parole stop fRequest. Come possiamo vedere nella classification_report , anche noi riusciamo ad ottenere una precisione e accuratezza 0,96 dopo l'allenamento per soli 5 epoche senza alcun pre-elaborazione!
In questo esempio, quando abbiamo creato lo strato Keras dal nostro modulo di incorporamento, abbiamo impostato il parametro trainable=False , il che significa che non verrà aggiornato durante l'allenamento dei pesi incorporamento. Prova a impostare a True per raggiungere circa il 97% di precisione con questo set di dati dopo soli 2 epoche.