
| | |  عرض على جيثب عرض على جيثب | |
هذا Colab هو دليل على استخدام Tensorflow محور لتصنيف النص في اللغة الإنكليزية / اللغات المحلية. نحن هنا اختيار البنغالية كلغة المحلية واستخدام pretrained كلمة التضمينات إلى حل مهمة تصنيف multiclass حيث نصنف المقالات الإخبارية البنغالية في 5 فئات. والتضمينات pretrained لالبنغالية يأتي من fastText التي هي مكتبة من الفيسبوك مع ناقلات كلمة pretrained الافراج عن 157 لغات.
سنستخدم pretrained مصدر تضمين TF-محور لتحويل كلمة التضمينات إلى وحدة نمطية النص تضمين أولا ثم استخدام وحدة لتدريب المصنف مع tf.keras ، ومستوى عال API سهل الاستعمال Tensorflow لبناء نماذج التعلم عميقة. حتى إذا كنا نستخدم تضمين fastText هنا ، فمن الممكن تصدير أي حفلات زفاف أخرى تم إعدادها مسبقًا من مهام أخرى والحصول على نتائج بسرعة باستخدام Tensorflow Hub.
يثبت
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
مجموعة البيانات
سوف نستخدم BARD (البنغالية المادة الإدراجات) التي تسيطر على حوالي 376226 المواد التي تم جمعها من مختلف المواقع الإخبارية البنغالية والمسمى مع 5 فئات هي: الاقتصاد، والدولة، الدولي، والرياضة، والترفيه. نحن تنزيل الملف من جوجل محرك هذا ( bit.ly/BARD_DATASET وصلة) في اشارة الى من هذا المستودع جيثب.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
تصدير ناقلات الكلمات سابقة التدريب إلى وحدة TF-Hub
يوفر TF-محور بعض النصوص المفيدة لتحويل كلمة التضمينات لTF-مركز حدات تضمين النص هنا . لجعل وحدة لالبنغالية أو أي لغة أخرى، لدينا ببساطة لتحميل كلمة تضمين .txt أو .vec الملف إلى نفس الدليل export_v2.py وتشغيل البرنامج النصي.
المصدر يقرأ ناقلات تضمين وتصدير ذلك إلى Tensorflow SavedModel . يحتوي نموذج SavedModel على برنامج TensorFlow كامل بما في ذلك الأوزان والرسم البياني. TF-المحور يمكن تحميل SavedModel باعتباره وحدة ، والتي سوف نستخدم لبناء نموذج لتصنيف النص. وبما أننا تستخدم tf.keras لبناء هذا النموذج، سوف نستخدم hub.KerasLayer ، الذي يوفر المجمع لوحدة نمطية TF-محور لاستخدامها بوصفها طبقة Keras.
أولا نحن سوف تحصل لدينا التضمينات كلمة من fastText وتضمينها مصدر من TF-محور الريبو .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
بعد ذلك ، سنقوم بتشغيل البرنامج النصي المصدر في ملف التضمين الخاص بنا. نظرًا لأن تضمين FastText يحتوي على سطر رئيسي وكبير جدًا (حوالي 3.3 جيجا بايت للغة البنغالية بعد التحويل إلى وحدة نمطية) ، فإننا نتجاهل السطر الأول ونصدر أول 100000 رمز فقط إلى وحدة تضمين النص.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
تأخذ وحدة دمج النص مجموعة من الجمل في موتر 1D من السلاسل كمدخلات وتخرج متجهات التضمين للشكل (حجم الدُفعة ، embedding_dim) المقابلة للجمل. يقوم بمعالجة المدخلات عن طريق تقسيم المساحات. يتم الجمع بين التضمينات كلمة لالتضمينات الجملة مع sqrtn الموحد (انظر هنا ). للتوضيح ، نقوم بتمرير قائمة الكلمات البنغالية كمدخلات ونحصل على متجهات التضمين المقابلة.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
قم بالتحويل إلى مجموعة بيانات Tensorflow
منذ بيانات كبيرة حقا بدلا من تحميل مجموعة البيانات بأكملها في ذاكرة سوف نستخدم مولد لانتاج عينات في وقت التشغيل على دفعات باستخدام Tensorflow مجموعة بيانات الوظائف. مجموعة البيانات أيضًا غير متوازنة للغاية ، لذا قبل استخدام المولد ، سنقوم بترتيب مجموعة البيانات عشوائيًا.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
يمكننا التحقق من توزيع الملصقات في التدريب وأمثلة التحقق من الصحة بعد الخلط.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
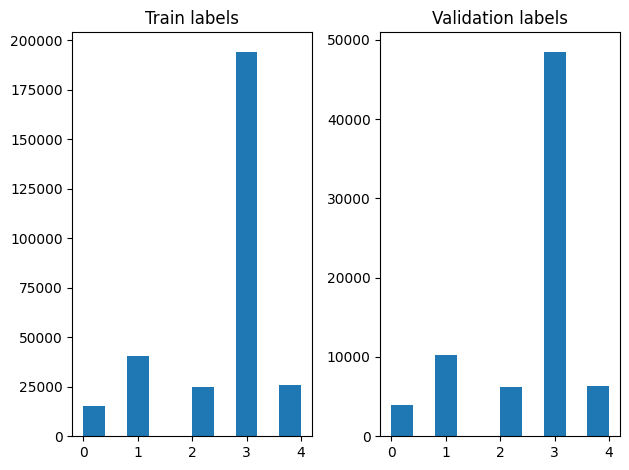
لإنشاء مجموعة بيانات باستخدام مولد، علينا أولا كتابة دالة مولد الذي يقرأ كل مادة من المواد من file_paths والتسميات من مجموعة التسمية، وعوائد سبيل المثال تدريبية واحدة في كل خطوة. نحن نمر هذه الوظيفة مولد لل tf.data.Dataset.from_generator الطريقة وتحديد أنواع الانتاج. كل مثال التدريب على الصفوف (tuple) التي تحتوي على مادة tf.string نوع البيانات وتسمية واحدة ساخنة المشفرة. يمكننا تقسيم مجموعة البيانات مع انقسام تدريب التحقق من 80-20 باستخدام tf.data.Dataset.skip و tf.data.Dataset.take الأساليب.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
التدريب النموذجي والتقييم
وبما أننا قد أضفت التفاف حول وحدة جهدنا لاستخدامها مثل أي طبقة أخرى في Keras، يمكننا خلق صغير متسلسل النموذج الذي هو كومة خطية من طبقات. ويمكننا أن نضيف لدينا نص تضمين وحدة مع model.add تماما مثل أي طبقة أخرى. نقوم بتجميع النموذج من خلال تحديد الخسارة والمحسن وتدربه لمدة 10 فترات. و tf.keras API يمكن التعامل مع Tensorflow مجموعات البيانات كمدخل، حتى نتمكن من تمرير مثيل الإدراجات إلى أسلوب يصلح لتدريب نموذج. وبما أننا باستخدام وظيفة مولد، tf.data سوف تتعامل مع توليد العينات، الجرعات لهم وإطعامهم لهذا النموذج.
نموذج
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
تمرين
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
تقييم
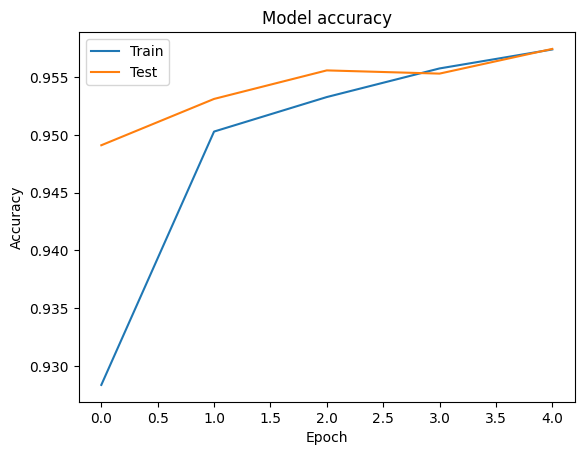
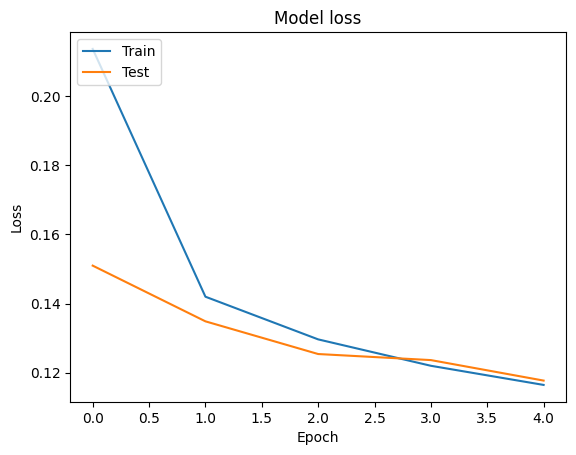
يمكننا تصور دقة وفقدان المنحنيات لبيانات التدريب والمصادقة باستخدام tf.keras.callbacks.History كائن تم إرجاعه من قبل tf.keras.Model.fit الأسلوب، الذي يحتوي على الخسارة ودقة قيمة لكل عصر.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
تنبؤ
يمكننا الحصول على تنبؤات بيانات التحقق والتحقق من مصفوفة الارتباك لمعرفة أداء النموذج لكل فئة من الفئات الخمس. لأن tf.keras.Model.predict الأسلوب بإرجاع صفيف الثانية لاحتمالات لكل فئة، فإنها يمكن تحويلها إلى تسميات فئة باستخدام np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
قارن الأداء
الآن يمكن أن نتخذها التسميات الصحيحة للالتحقق من صحة البيانات من labels ومع توقعاتنا مقارنتها للحصول على classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
يمكننا أيضا مقارنة أداء نموذجنا مع النتائج المنشورة التي تم الحصول عليها في الأصلي ورقة ، والتي كان صفت 0.96 الدقة. والكتاب الأصلي العديد من الخطوات تجهيزها أجريت على مجموعة البيانات، مثل إسقاط علامات ترقيم والأرقام، وإزالة أعلى 25 معظم frequest كلمات التوقف. كما نرى في classification_report ، استطعنا ايضا ان يحصل على 0.96 دقة ودقة بعد التدريب لالعهود 5 فقط من دون أي تجهيزها!
في هذا المثال، عندما أنشأنا طبقة Keras من وحدة التضمين لدينا، وتعيين المعلمة trainable=False ، وهو ما يعني لن يتم تحديثها خلال التدريب ودمج الأوزان. حاول إعداد ل True لتصل إلى حوالي 97٪ دقة باستخدام هذه البينات بعد حقب فقط 2.