| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
TensorFlow, tf.experimental.numpy olarak kullanılabilen tf.experimental.numpy API'sinin bir alt kümesini uygular. Bu, TensorFlow tarafından hızlandırılan NumPy kodunun çalıştırılmasına ve ayrıca TensorFlow'un tüm API'lerine erişime izin verir.
Kurmak
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
NumPy davranışını etkinleştirme
tnp'yi tnp olarak kullanmak için TensorFlow için NumPy davranışını etkinleştirin:
tnp.experimental_enable_numpy_behavior()
Bu çağrı, TensorFlow'da tür tanıtımına olanak tanır ve aynı zamanda, değişmez değerleri tensörlere dönüştürürken, NumPy standardını daha sıkı bir şekilde takip etmek için tür çıkarımını değiştirir.
TensorFlow NumPy ND dizisi
ND Array adlı bir tf.experimental.numpy.ndarray örneği, belirli bir aygıta yerleştirilmiş belirli bir dtype çok boyutlu yoğun dizisini temsil eder. tf.Tensor için bir takma addır. ndarray.T , ndarray.reshape , ndarray.ravel ve diğerleri gibi faydalı yöntemler için ND dizi sınıfına bakın.
Önce bir ND dizi nesnesi oluşturun ve ardından farklı yöntemleri çağırın.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Tip promosyonu
TensorFlow NumPy API'leri, değişmez değerleri ND dizisine dönüştürmek için ve ayrıca ND dizisi girişlerinde tür yükseltmesi gerçekleştirmek için iyi tanımlanmış semantiklere sahiptir. Daha fazla ayrıntı için lütfen np.result_type bakın.
TensorFlow API'leri, tf.Tensor girdilerini değiştirmeden bırakır ve bunlar üzerinde tür yükseltmesi gerçekleştirmez, TensorFlow NumPy API'leri ise tüm girdileri NumPy türü yükseltme kurallarına göre destekler. Bir sonraki örnekte, tür promosyonu gerçekleştireceksiniz. İlk olarak, farklı türlerdeki ND dizi girişlerinde toplama işlemini çalıştırın ve çıktı türlerini not edin. Bu tür promosyonların hiçbirine TensorFlow API'leri tarafından izin verilmez.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Son olarak, ndarray.asarray kullanarak değişmez değerleri ND dizisine dönüştürün ve elde edilen türü not edin.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
NumPy, değişmez değerleri ND dizisine dönüştürürken tnp.int64 ve tnp.float64 gibi geniş türleri tercih eder. Buna karşılık, tf.convert_to_tensor , sabitleri tf.Tensor dönüştürmek için tf.int32 ve tf.float32 türlerini tercih eder. TensorFlow NumPy API'leri, tamsayılar için NumPy davranışına uyar. Kayan noktalara gelince, experimental_enable_numpy_behavior prefer_float32 argümanı, tf.float32 yerine tf.float64 tercih edilip edilmeyeceğini kontrol etmenize izin verir (varsayılan olarak False ). Örneğin:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
yayın
TensorFlow'a benzer şekilde NumPy, "yayın" değerleri için zengin anlambilim tanımlar. Daha fazla bilgi için NumPy yayın kılavuzuna göz atabilir ve bunu TensorFlow yayın semantiği ile karşılaştırabilirsiniz.
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
indeksleme
NumPy çok karmaşık indeksleme kuralları tanımlar. NumPy İndeksleme kılavuzuna bakın. Aşağıdaki indeksler olarak ND dizilerinin kullanımına dikkat edin.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)yer tutucu15 l10n-yer
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Örnek Model
Ardından, bir modelin nasıl oluşturulacağını ve üzerinde nasıl çıkarım yapılacağını görebilirsiniz. Bu basit model, bir relu katmanı ve ardından doğrusal bir izdüşüm uygular. Sonraki bölümlerde, TensorFlow'un GradientTape kullanılarak bu model için gradyanların nasıl hesaplanacağı gösterilecektir.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy ve NumPy
TensorFlow NumPy, tam NumPy belirtiminin bir alt kümesini uygular. Zamanla daha fazla sembol eklenecek olsa da, yakın gelecekte desteklenmeyecek sistematik özellikler var. Bunlara NumPy C API desteği, Swig entegrasyonu, Fortran depolama düzeni, görünümler ve stride_tricks ve bazı dtype s ( np.recarray ve np.object gibi) dahildir. Daha fazla ayrıntı için lütfen TensorFlow NumPy API Belgelerine bakın.
NumPy birlikte çalışabilirliği
TensorFlow ND dizileri, NumPy işlevleriyle birlikte çalışabilir. Bu nesneler __array__ arabirimini uygular. NumPy, işlev bağımsız değişkenlerini işlemeden önce np.ndarray değerlerine dönüştürmek için bu arabirimi kullanır.
Benzer şekilde, TensorFlow NumPy işlevleri, np.ndarray dahil olmak üzere farklı türdeki girdileri kabul edebilir. Bu girdiler, üzerinde ndarray.asarray bir ND dizisine dönüştürülür.
ND dizisinin np.ndarray'e ve np.ndarray , gerçek veri kopyalarını tetikleyebilir. Daha fazla ayrıntı için lütfen arabellek kopyaları bölümüne bakın.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>-yer tutucu21 l10n-yer
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
arabellek kopyaları
TensorFlow NumPy'yi NumPy koduyla karıştırmak veri kopyalarını tetikleyebilir. Bunun nedeni, TensorFlow NumPy'nin bellek hizalaması konusunda NumPy'ninkinden daha katı gereksinimleri olmasıdır.
TensorFlow NumPy'ye bir np.ndarray iletildiğinde, hizalama gereksinimlerini kontrol edecek ve gerekirse bir kopyayı tetikleyecektir. Bir ND dizisi CPU arabelleğini NumPy'ye geçirirken, arabellek genellikle hizalama gereksinimlerini karşılar ve NumPy'nin bir kopya oluşturması gerekmez.
ND dizileri, yerel CPU belleği dışındaki aygıtlara yerleştirilen arabelleklere başvurabilir. Bu gibi durumlarda, bir NumPy işlevinin çağrılması, gerektiğinde ağ veya cihaz genelinde kopyaları tetikleyecektir.
Bu göz önüne alındığında, NumPy API çağrılarıyla karıştırma işlemi genellikle dikkatli yapılmalı ve kullanıcı veri kopyalamanın genel giderlerine dikkat etmelidir. TensorFlow NumPy çağrılarını TensorFlow çağrılarıyla araya eklemek genellikle güvenlidir ve verilerin kopyalanmasını önler. Daha fazla ayrıntı için TensorFlow birlikte çalışabilirliği bölümüne bakın.
Operatör Önceliği
TensorFlow NumPy, NumPy'lerden daha yüksek bir __array_priority__ tanımlar. Bu, hem ND dizisini hem de np.ndarray içeren operatörler için birincisinin öncelikli olacağı, yani np.ndarray girişinin bir ND dizisine dönüştürüleceği ve operatörün TensorFlow NumPy uygulamasının çağrılacağı anlamına gelir.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy ve TensorFlow
TensorFlow NumPy, TensorFlow'un üzerine kurulmuştur ve bu nedenle TensorFlow ile sorunsuz bir şekilde birlikte çalışır.
tf.Tensor ve ND dizisi
ND dizisi, tf.Tensor için bir takma addır, bu nedenle, gerçek veri kopyalarını tetiklemeden açıkça karıştırılabilirler.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
TensorFlow birlikte çalışabilirliği
ND dizisi yalnızca tf.Tensor için bir takma ad olduğundan, bir ND dizisi tf.Tensor API'lerine geçirilebilir. Daha önce belirtildiği gibi, bu tür bir birlikte çalışma, hızlandırıcılara veya uzak aygıtlara yerleştirilen veriler için bile veri kopyaları yapmaz.
Tersine, tf.Tensor nesneleri, veri kopyaları gerçekleştirilmeden tf.experimental.numpy API'lerine geçirilebilir.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradyanlar ve Jacobianlar: tf.GradientTape
TensorFlow'un GradientTape'i, TensorFlow ve TensorFlow NumPy kodu aracılığıyla geri yayılım için kullanılabilir.
Örnek Model bölümünde oluşturulan modeli kullanın ve gradyanları ve jacobianları hesaplayın.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]yer tutucu30 l10n-yer
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
İzleme derlemesi: tf.function
TensorFlow'un tf.function , kodu "izleyerek" ve ardından bu izleri çok daha hızlı performans için optimize ederek çalışır. Grafiklere ve İşlevlere Giriş bölümüne bakın.
tf.function , TensorFlow NumPy kodunu optimize etmek için de kullanılabilir. Hızlanmaları göstermek için basit bir örnek. tf.function kodunun gövdesinin TensorFlow NumPy API'lerine yapılan çağrıları içerdiğine dikkat edin.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vektörleştirme: tf.vectorized_map
TensorFlow, paralel döngülerin vektörleştirilmesi için yerleşik bir desteğe sahiptir ve bu, bir ila iki büyüklük derecesinde hızlanmalara izin verir. Bu hızlandırmalara tf.vectorized_map API aracılığıyla erişilebilir ve TensorFlow NumPy kodu için de geçerlidir.
Bazen bir yığındaki her bir çıktının gradyanını karşılık gelen girdi yığın öğesiyle hesaplamak yararlıdır. Bu tür hesaplama, aşağıda gösterildiği gibi tf.vectorized_map kullanılarak verimli bir şekilde yapılabilir.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)yer tutucu36 l10n-yer
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Cihaz yerleşimi
TensorFlow NumPy, CPU'lara, GPU'lara, TPU'lara ve uzak cihazlara işlemler yerleştirebilir. Cihaz yerleştirme için standart TensorFlow mekanizmalarını kullanır. Aşağıda basit bir örnek, tüm cihazların nasıl listeleneceğini ve ardından belirli bir cihaza bazı hesaplamaların nasıl yerleştirileceğini gösterir.
TensorFlow ayrıca, hesaplamayı cihazlar arasında çoğaltmak ve burada ele alınmayacak olan toplu azaltmalar gerçekleştirmek için API'lere sahiptir.
Cihazları listele
Hangi cihazların kullanılacağını bulmak için tf.config.list_logical_devices ve tf.config.list_physical_devices kullanılabilir.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Yerleştirme işlemleri: tf.device
İşlemler, bir cihaza tf.device kapsamında çağrılarak yerleştirilebilir.
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
ND dizilerini cihazlar arasında kopyalama: tnp.copy
Belirli bir cihaz kapsamına yerleştirilen bir tnp.copy çağrısı, veriler zaten o cihazda değilse, verileri o cihaza kopyalayacaktır.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
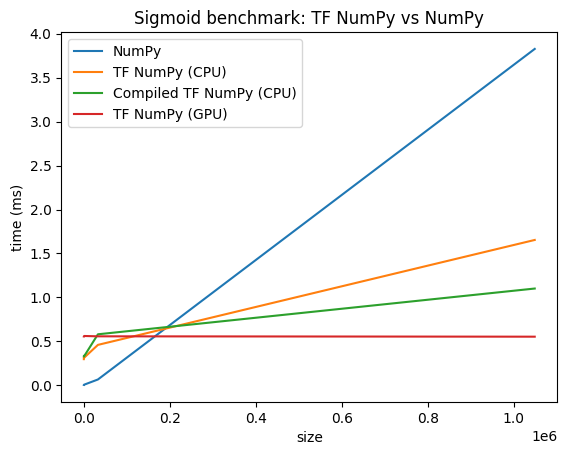
Performans karşılaştırmaları
TensorFlow NumPy, CPU'lara, GPU'lara ve TPU'lara gönderilebilen yüksek düzeyde optimize edilmiş TensorFlow çekirdeklerini kullanır. TensorFlow ayrıca, performans ve bellek iyileştirmelerine dönüşen işlem birleştirme gibi birçok derleyici optimizasyonu gerçekleştirir. Daha fazla bilgi edinmek için Grappler ile TensorFlow grafik optimizasyonuna bakın.
Ancak TensorFlow, NumPy'ye kıyasla gönderme işlemleri için daha yüksek genel giderlere sahiptir. Küçük işlemlerden (yaklaşık 10 mikrosaniyeden daha az) oluşan iş yükleri için, bu genel giderler çalışma zamanına hükmedebilir ve NumPy daha iyi performans sağlayabilir. Diğer durumlarda, TensorFlow genellikle daha iyi performans sağlamalıdır.
Farklı giriş boyutları için NumPy ve TensorFlow NumPy performansını karşılaştırmak için aşağıdaki karşılaştırmayı çalıştırın.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)