| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Panoramica
TensorFlow implementa un sottoinsieme dell'API NumPy , disponibile come tf.experimental.numpy . Ciò consente di eseguire il codice NumPy, accelerato da TensorFlow, consentendo anche l'accesso a tutte le API di TensorFlow.
Impostare
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Abilitazione del comportamento NumPy
Per utilizzare tnp come NumPy, abilitare il comportamento NumPy per TensorFlow:
tnp.experimental_enable_numpy_behavior()
Questa chiamata abilita la promozione del tipo in TensorFlow e cambia anche l'inferenza del tipo, quando si convertono i valori letterali in tensori, per seguire più rigorosamente lo standard NumPy.
Matrice TensorFlow NumPy ND
Un'istanza di tf.experimental.numpy.ndarray , denominata ND Array , rappresenta un array denso multidimensionale di un dato dtype posizionato su un determinato dispositivo. È un alias di tf.Tensor . Dai un'occhiata alla classe array ND per metodi utili come ndarray.T , ndarray.reshape , ndarray.ravel e altri.
Creare prima un oggetto array ND, quindi richiamare metodi diversi.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Digita promozione
Le API TensorFlow NumPy hanno una semantica ben definita per convertire i valori letterali in array ND, nonché per eseguire la promozione del tipo sugli input dell'array ND. Si prega di vedere np.result_type per maggiori dettagli.
Le API TensorFlow lasciano invariati gli input tf.Tensor e non eseguono la promozione del tipo su di essi, mentre le API NumPy TensorFlow promuovono tutti gli input in base alle regole di promozione del tipo NumPy. Nel prossimo esempio, eseguirai la promozione del tipo. Per prima cosa, esegui l'addizione sugli input dell'array ND di diversi tipi e annota i tipi di output. Nessuna di queste promozioni di tipo sarebbe consentita dalle API TensorFlow.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Infine, converti i letterali in array ND usando ndarray.asarray e annota il tipo risultante.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Quando si convertono i valori letterali in array ND, NumPy preferisce tipi wide come tnp.int64 e tnp.float64 . Al contrario, tf.convert_to_tensor preferisce i tipi tf.int32 e tf.float32 per convertire le costanti in tf.Tensor . Le API TensorFlow NumPy aderiscono al comportamento NumPy per i numeri interi. Per quanto riguarda i float, l'argomento prefer_float32 di experimental_enable_numpy_behavior ti consente di controllare se preferire tf.float32 a tf.float64 (predefinito su False ). Per esempio:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Trasmissione
Simile a TensorFlow, NumPy definisce una semantica avanzata per i valori di "trasmissione". Puoi consultare la guida alla trasmissione NumPy per ulteriori informazioni e confrontarla con la semantica della trasmissione TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Indicizzazione
NumPy definisce regole di indicizzazione molto sofisticate. Consulta la guida all'indicizzazione di NumPy . Nota l'uso di array ND come indici di seguito.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Modello di esempio
Successivamente, puoi vedere come creare un modello ed eseguire l'inferenza su di esso. Questo semplice modello applica uno strato relu seguito da una proiezione lineare. Le sezioni successive mostreranno come calcolare i gradienti per questo modello usando GradientTape di TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy e NumPy
TensorFlow NumPy implementa un sottoinsieme delle specifiche NumPy complete. Mentre più simboli verranno aggiunti nel tempo, ci sono funzionalità sistematiche che non saranno supportate nel prossimo futuro. Questi includono il supporto dell'API NumPy C, l'integrazione di Swig, l'ordine di archiviazione Fortran, le visualizzazioni e stride_tricks e alcuni dtype s (come np.recarray e np.object ). Per maggiori dettagli, consultare la documentazione dell'API TensorFlow NumPy .
Interoperabilità NumPy
Gli array TensorFlow ND possono interagire con le funzioni NumPy. Questi oggetti implementano l'interfaccia __array__ . NumPy usa questa interfaccia per convertire gli argomenti delle funzioni in valori np.ndarray prima di elaborarli.
Allo stesso modo, le funzioni TensorFlow NumPy possono accettare input di diversi tipi, incluso np.ndarray . Questi input vengono convertiti in un array ND chiamando ndarray.asarray su di essi.
La conversione dell'array ND in e da np.ndarray può attivare copie di dati effettive. Si prega di consultare la sezione sulle copie buffer per maggiori dettagli.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Copie buffer
La combinazione di TensorFlow NumPy con il codice NumPy può attivare copie di dati. Questo perché TensorFlow NumPy ha requisiti più severi sull'allineamento della memoria rispetto a quelli di NumPy.
Quando un np.ndarray viene passato a TensorFlow NumPy, verificherà i requisiti di allineamento e ne attiverà una copia se necessario. Quando si passa un buffer della CPU dell'array ND a NumPy, in genere il buffer soddisferà i requisiti di allineamento e NumPy non dovrà crearne una copia.
Gli array ND possono fare riferimento a buffer posizionati su dispositivi diversi dalla memoria della CPU locale. In questi casi, il richiamo di una funzione NumPy attiverà copie sulla rete o sul dispositivo secondo necessità.
Detto questo, l'intermix con le chiamate API NumPy dovrebbe generalmente essere eseguita con cautela e l'utente dovrebbe prestare attenzione ai costi generali della copia dei dati. L'interleaving delle chiamate TensorFlow NumPy con le chiamate TensorFlow è generalmente sicuro ed evita la copia dei dati. Vedere la sezione sull'interoperabilità TensorFlow per maggiori dettagli.
Precedenza dell'operatore
TensorFlow NumPy definisce un __array_priority__ maggiore di NumPy. Ciò significa che per gli operatori che coinvolgono sia ND array che np.ndarray , il primo avrà la precedenza, ovvero l'input np.ndarray verrà convertito in un array ND e l'implementazione TensorFlow NumPy dell'operatore verrà richiamata.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy e TensorFlow
TensorFlow NumPy è basato su TensorFlow e quindi interagisce perfettamente con TensorFlow.
tf.Tensor e array ND
L'array ND è un alias di tf.Tensor , quindi ovviamente possono essere mescolati senza attivare copie di dati effettive.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interoperabilità TensorFlow
Un array ND può essere passato alle API TensorFlow, poiché l'array ND è solo un alias di tf.Tensor . Come accennato in precedenza, tale interoperabilità non esegue copie dei dati, nemmeno per i dati inseriti su acceleratori o dispositivi remoti.
Al contrario, gli oggetti tf.Tensor possono essere passati alle API tf.experimental.numpy , senza eseguire copie dei dati.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradienti e Jacobiani: tf.GradientTape
GradientTape di TensorFlow può essere utilizzato per la backpropagation tramite il codice TensorFlow e TensorFlow NumPy.
Usa il modello creato nella sezione Modello di esempio e calcola gradienti e jacobian.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Compilazione traccia: tf.function
La funzione tf. di tf.function funziona "tracciando la compilazione" del codice e quindi ottimizzando queste tracce per prestazioni molto più veloci. Vedere l' Introduzione a Grafici e Funzioni .
tf.function può essere utilizzato anche per ottimizzare il codice TensorFlow NumPy. Ecco un semplice esempio per dimostrare gli speedup. Si noti che il corpo del codice tf.function include chiamate alle API TensorFlow NumPy.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vettorizzazione: tf.vectorized_map
TensorFlow ha un supporto integrato per la vettorizzazione di loop paralleli, che consente accelerazioni da uno a due ordini di grandezza. Questi acceleratori sono accessibili tramite l'API tf.vectorized_map e si applicano anche al codice TensorFlow NumPy.
A volte è utile calcolare il gradiente di ciascun output in un batch rispetto all'elemento batch di input corrispondente. Tale calcolo può essere eseguito in modo efficiente utilizzando tf.vectorized_map come mostrato di seguito.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Posizionamento del dispositivo
TensorFlow NumPy può eseguire operazioni su CPU, GPU, TPU e dispositivi remoti. Utilizza i meccanismi TensorFlow standard per il posizionamento del dispositivo. Di seguito un semplice esempio mostra come elencare tutti i dispositivi e quindi inserire alcuni calcoli su un particolare dispositivo.
TensorFlow dispone anche di API per replicare il calcolo su dispositivi ed eseguire riduzioni collettive che non saranno trattate qui.
Elenca i dispositivi
tf.config.list_logical_devices e tf.config.list_physical_devices possono essere utilizzati per trovare quali dispositivi utilizzare.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Operazioni di piazzamento: tf.device
È possibile eseguire operazioni su un dispositivo chiamandolo in un ambito tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Copia di array ND tra dispositivi: tnp.copy
Una chiamata a tnp.copy , inserita in un determinato ambito del dispositivo, copierà i dati su quel dispositivo, a meno che i dati non siano già su quel dispositivo.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
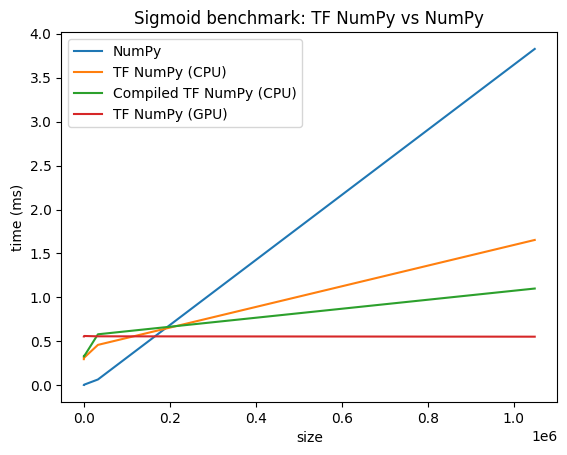
Confronti delle prestazioni
TensorFlow NumPy utilizza kernel TensorFlow altamente ottimizzati che possono essere inviati su CPU, GPU e TPU. TensorFlow esegue anche molte ottimizzazioni del compilatore, come la fusione delle operazioni, che si traducono in miglioramenti delle prestazioni e della memoria. Vedi Ottimizzazione del grafico TensorFlow con Grappler per saperne di più.
Tuttavia TensorFlow ha costi generali più elevati per le operazioni di invio rispetto a NumPy. Per carichi di lavoro composti da piccole operazioni (meno di circa 10 microsecondi), questi costi generali possono dominare il runtime e NumPy potrebbe fornire prestazioni migliori. Per altri casi, TensorFlow dovrebbe generalmente fornire prestazioni migliori.
Esegui il benchmark di seguito per confrontare le prestazioni di NumPy e TensorFlow NumPy per diverse dimensioni di input.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)