| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
TensorFlow implementa un subconjunto de la API NumPy , disponible como tf.experimental.numpy . Esto permite ejecutar el código NumPy, acelerado por TensorFlow, al mismo tiempo que permite el acceso a todas las API de TensorFlow.
Configuración
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Habilitación del comportamiento de NumPy
Para usar tnp como NumPy, habilite el comportamiento de NumPy para TensorFlow:
tnp.experimental_enable_numpy_behavior()
Esta llamada habilita la promoción de tipos en TensorFlow y también cambia la inferencia de tipos, al convertir literales en tensores, para seguir más estrictamente el estándar NumPy.
Matriz TensorFlow NumPy ND
Una instancia de tf.experimental.numpy.ndarray , llamada ND Array , representa una matriz densa multidimensional de un tipo dado dtype en un determinado dispositivo. Es un alias de tf.Tensor . Consulte la clase de matriz ND para conocer métodos útiles como ndarray.T , ndarray.reshape , ndarray.ravel y otros.
Primero cree un objeto de matriz ND y luego invoque diferentes métodos.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Tipo promoción
Las API NumPy de TensorFlow tienen una semántica bien definida para convertir literales en arreglos ND, así como para realizar la promoción de tipos en entradas de arreglos ND. Consulte np.result_type para obtener más detalles.
Las API de TensorFlow dejan las entradas tf.Tensor sin cambios y no realizan una promoción de tipos en ellas, mientras que las API de TensorFlow NumPy promocionan todas las entradas de acuerdo con las reglas de promoción de tipos de NumPy. En el siguiente ejemplo, realizará la promoción de tipo. Primero, ejecute la suma en entradas de matriz ND de diferentes tipos y anote los tipos de salida. Las API de TensorFlow no permitirían ninguno de estos tipos de promociones.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Finalmente, convierta los literales a la matriz ND usando ndarray.asarray y observe el tipo resultante.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Al convertir literales a matriz ND, NumPy prefiere tipos anchos como tnp.int64 y tnp.float64 . Por el contrario, tf.convert_to_tensor prefiere los tipos tf.int32 y tf.float32 para convertir constantes a tf.Tensor . Las API de TensorFlow NumPy se adhieren al comportamiento de NumPy para números enteros. En cuanto a los flotantes, el argumento prefer_float32 de experimental_enable_numpy_behavior le permite controlar si prefiere tf.float32 sobre tf.float64 (predeterminado en False ). Por ejemplo:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Radiodifusión
Similar a TensorFlow, NumPy define una semántica rica para valores de "transmisión". Puede consultar la guía de transmisión de NumPy para obtener más información y comparar esto con la semántica de transmisión de TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Indexación
NumPy define reglas de indexación muy sofisticadas. Consulte la guía de indexación de NumPy . Tenga en cuenta el uso de matrices ND como índices a continuación.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Modelo de ejemplo
A continuación, puede ver cómo crear un modelo y ejecutar inferencias en él. Este modelo simple aplica una capa relu seguida de una proyección lineal. Las secciones posteriores mostrarán cómo calcular gradientes para este modelo usando GradientTape de TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy y NumPy
TensorFlow NumPy implementa un subconjunto de la especificación completa de NumPy. Si bien se agregarán más símbolos con el tiempo, hay funciones sistemáticas que no serán compatibles en un futuro cercano. Estos incluyen compatibilidad con NumPy C API, integración Swig, orden de almacenamiento Fortran, vistas y stride_tricks , y algunos dtype s (como np.recarray y np.object ). Para obtener más detalles, consulte la documentación de la API NumPy de TensorFlow .
interoperabilidad numpy
Los arreglos TensorFlow ND pueden interoperar con funciones NumPy. Estos objetos implementan la interfaz __array__ . NumPy usa esta interfaz para convertir argumentos de función a valores np.ndarray antes de procesarlos.
De manera similar, las funciones TensorFlow NumPy pueden aceptar entradas de diferentes tipos, incluido np.ndarray . Estas entradas se convierten en una matriz ND llamando a ndarray.asarray en ellas.
La conversión de la matriz ND hacia y desde np.ndarray puede desencadenar copias de datos reales. Consulte la sección sobre copias de búfer para obtener más detalles.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Copias de búfer
Mezclar TensorFlow NumPy con el código NumPy puede desencadenar copias de datos. Esto se debe a que TensorFlow NumPy tiene requisitos de alineación de memoria más estrictos que los de NumPy.
Cuando se pasa un np.ndarray a TensorFlow NumPy, verificará los requisitos de alineación y activará una copia si es necesario. Al pasar un búfer de CPU de matriz ND a NumPy, generalmente el búfer cumplirá con los requisitos de alineación y NumPy no necesitará crear una copia.
Las matrices ND pueden hacer referencia a búferes ubicados en dispositivos que no sean la memoria de la CPU local. En tales casos, invocar una función NumPy activará copias en la red o el dispositivo según sea necesario.
Dado esto, la combinación con las llamadas API de NumPy generalmente debe realizarse con precaución y el usuario debe tener cuidado con los gastos generales de copia de datos. Por lo general, intercalar llamadas de TensorFlow NumPy con llamadas de TensorFlow es seguro y evita la copia de datos. Consulte la sección sobre interoperabilidad de TensorFlow para obtener más detalles.
Precedencia del operador
TensorFlow NumPy define una __array_priority__ más alta que la de NumPy. Esto significa que para los operadores que involucran tanto la matriz ND como np.ndarray , el primero tendrá prioridad, es decir, la entrada de np.ndarray se convertirá en una matriz ND y se invocará la implementación TensorFlow NumPy del operador.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy y TensorFlow
TensorFlow NumPy se basa en TensorFlow y, por lo tanto, interactúa a la perfección con TensorFlow.
tf.Tensor y matriz ND
La matriz ND es un alias de tf.Tensor , por lo que obviamente se pueden entremezclar sin activar copias de datos reales.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interoperabilidad de TensorFlow
Una matriz ND se puede pasar a las API de TensorFlow, ya que la matriz ND es solo un alias para tf.Tensor . Como se mencionó anteriormente, dicha interoperación no realiza copias de datos, ni siquiera para los datos colocados en aceleradores o dispositivos remotos.
Por el contrario, los objetos tf.Tensor se pueden pasar a las API tf.experimental.numpy , sin realizar copias de datos.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradientes y jacobianos: tf.GradientTape
GradientTape de TensorFlow se puede usar para retropropagación a través del código TensorFlow y TensorFlow NumPy.
Utilice el modelo creado en la sección Modelo de ejemplo y calcule gradientes y jacobianos.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Seguimiento de compilación: tf.function
La función tf. de tf.function funciona mediante la "compilación de seguimiento" del código y luego la optimización de estos seguimientos para un rendimiento mucho más rápido. Vea la Introducción a Gráficos y Funciones .
tf.function se puede usar para optimizar el código TensorFlow NumPy. Aquí hay un ejemplo simple para demostrar las aceleraciones. Tenga en cuenta que el cuerpo del código tf.function incluye llamadas a las API NumPy de TensorFlow.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vectorización: tf.vectorized_map
TensorFlow tiene soporte incorporado para vectorizar bucles paralelos, lo que permite aceleraciones de uno o dos órdenes de magnitud. Se puede acceder a estas aceleraciones a través de la API tf.vectorized_map y también se aplican al código TensorFlow NumPy.
A veces es útil calcular el gradiente de cada salida en un lote con respecto al elemento del lote de entrada correspondiente. Tal cálculo se puede realizar de manera eficiente utilizando tf.vectorized_map como se muestra a continuación.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Ubicación del dispositivo
TensorFlow NumPy puede realizar operaciones en CPU, GPU, TPU y dispositivos remotos. Utiliza mecanismos TensorFlow estándar para la colocación de dispositivos. A continuación, un ejemplo simple muestra cómo enumerar todos los dispositivos y luego realizar algunos cálculos en un dispositivo en particular.
TensorFlow también tiene API para replicar el cálculo entre dispositivos y realizar reducciones colectivas que no se tratarán aquí.
Listar dispositivos
tf.config.list_logical_devices y tf.config.list_physical_devices se pueden usar para encontrar qué dispositivos usar.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Colocación de operaciones: tf.device
Las operaciones se pueden colocar en un dispositivo llamándolo en un ámbito tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Copia de matrices ND entre dispositivos: tnp.copy
Una llamada a tnp.copy , ubicada en un cierto dispositivo, copiará los datos a ese dispositivo, a menos que los datos ya estén en ese dispositivo.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
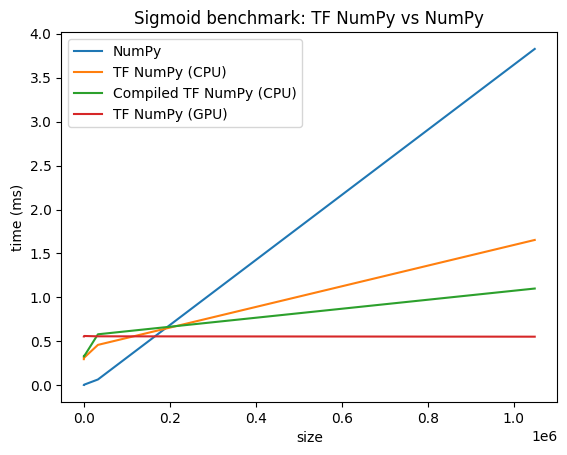
Comparaciones de rendimiento
TensorFlow NumPy utiliza kernels de TensorFlow altamente optimizados que se pueden distribuir en CPU, GPU y TPU. TensorFlow también realiza muchas optimizaciones del compilador, como la fusión de operaciones, que se traducen en mejoras de rendimiento y memoria. Consulta la optimización de gráficos de TensorFlow con Grappler para obtener más información.
Sin embargo, TensorFlow tiene gastos generales más altos para las operaciones de despacho en comparación con NumPy. Para cargas de trabajo compuestas de operaciones pequeñas (menos de 10 microsegundos), estos gastos generales pueden dominar el tiempo de ejecución y NumPy podría proporcionar un mejor rendimiento. Para otros casos, TensorFlow generalmente debería proporcionar un mejor rendimiento.
Ejecute el punto de referencia a continuación para comparar el rendimiento de NumPy y TensorFlow NumPy para diferentes tamaños de entrada.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)