| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
TensorFlow implémente un sous-ensemble de l' API NumPy , disponible en tant que tf.experimental.numpy . Cela permet d'exécuter du code NumPy, accéléré par TensorFlow, tout en permettant également l'accès à toutes les API de TensorFlow.
Installer
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Activation du comportement NumPy
Pour utiliser tnp comme NumPy, activez le comportement NumPy pour TensorFlow :
tnp.experimental_enable_numpy_behavior()
Cet appel active la promotion de type dans TensorFlow et modifie également l'inférence de type, lors de la conversion de littéraux en tenseurs, pour suivre plus strictement la norme NumPy.
Tableau TensorFlow NumPy ND
Une instance de tf.experimental.numpy.ndarray , appelée ND Array , représente un tableau dense multidimensionnel d'un dtype donné placé sur un certain appareil. C'est un alias de tf.Tensor . Découvrez la classe de tableau ND pour des méthodes utiles comme ndarray.T , ndarray.reshape , ndarray.ravel et autres.
Créez d'abord un objet tableau ND, puis appelez différentes méthodes.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Tapez la promotion
Les API TensorFlow NumPy ont une sémantique bien définie pour convertir les littéraux en tableau ND, ainsi que pour effectuer la promotion de type sur les entrées du tableau ND. Veuillez consulter np.result_type pour plus de détails.
Les API TensorFlow laissent les entrées tf.Tensor inchangées et n'effectuent pas de promotion de type sur celles-ci, tandis que les API TensorFlow NumPy promeuvent toutes les entrées conformément aux règles de promotion de type NumPy. Dans l'exemple suivant, vous effectuerez une promotion de type. Tout d'abord, exécutez l'addition sur les entrées du tableau ND de différents types et notez les types de sortie. Aucune de ces types de promotions ne serait autorisée par les API TensorFlow.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Enfin, convertissez les littéraux en tableau ND à l'aide de ndarray.asarray et notez le type résultant.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Lors de la conversion de littéraux en tableau ND, NumPy préfère les types larges comme tnp.int64 et tnp.float64 . En revanche, tf.convert_to_tensor préfère les types tf.int32 et tf.float32 pour convertir les constantes en tf.Tensor . Les API TensorFlow NumPy adhèrent au comportement NumPy pour les nombres entiers. Comme pour les flottants, l'argument prefer_float32 de experimental_enable_numpy_behavior vous permet de contrôler s'il faut préférer tf.float32 à tf.float64 (par défaut à False ). Par example:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Diffusion
Semblable à TensorFlow, NumPy définit une sémantique riche pour les valeurs de "diffusion". Vous pouvez consulter le guide de diffusion NumPy pour plus d'informations et le comparer avec la sémantique de diffusion TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Indexage
NumPy définit des règles d'indexation très sophistiquées. Voir le guide d'indexation NumPy . Notez l'utilisation des tableaux ND comme indices ci-dessous.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Exemple de modèle
Ensuite, vous pouvez voir comment créer un modèle et y exécuter une inférence. Ce modèle simple applique une couche relu suivie d'une projection linéaire. Les sections ultérieures montreront comment calculer les gradients pour ce modèle à l'aide de GradientTape de TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy et NumPy
TensorFlow NumPy implémente un sous-ensemble de la spécification NumPy complète. Bien que d'autres symboles soient ajoutés au fil du temps, certaines fonctionnalités systématiques ne seront pas prises en charge dans un proche avenir. Ceux-ci incluent la prise en charge de l'API NumPy C, l'intégration Swig, l'ordre de stockage Fortran, les vues et stride_tricks , et certains dtype s (comme np.recarray et np.object ). Pour plus de détails, veuillez consulter la documentation de l'API TensorFlow NumPy .
Interopérabilité NumPy
Les tableaux TensorFlow ND peuvent interagir avec les fonctions NumPy. Ces objets implémentent l'interface __array__ . NumPy utilise cette interface pour convertir les arguments de la fonction en valeurs np.ndarray avant de les traiter.
De même, les fonctions TensorFlow NumPy peuvent accepter des entrées de différents types, y compris np.ndarray . Ces entrées sont converties en un tableau ND en appelant ndarray.asarray dessus.
La conversion du tableau ND vers et depuis np.ndarray peut déclencher des copies de données réelles. Veuillez consulter la section sur les copies tampons pour plus de détails.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Copies tampons
Le mélange de TensorFlow NumPy avec le code NumPy peut déclencher des copies de données. En effet, TensorFlow NumPy a des exigences plus strictes en matière d'alignement de la mémoire que celles de NumPy.
Lorsqu'un np.ndarray est transmis à TensorFlow NumPy, il vérifie les exigences d'alignement et déclenche une copie si nécessaire. Lors du passage d'un tampon CPU de tableau ND à NumPy, généralement le tampon satisfera aux exigences d'alignement et NumPy n'aura pas besoin de créer une copie.
Les tableaux ND peuvent faire référence à des tampons placés sur des périphériques autres que la mémoire CPU locale. Dans de tels cas, l'appel d'une fonction NumPy déclenchera des copies sur le réseau ou l'appareil selon les besoins.
Compte tenu de cela, le mélange avec les appels d'API NumPy doit généralement être fait avec prudence et l'utilisateur doit faire attention aux frais généraux de copie des données. L'entrelacement des appels TensorFlow NumPy avec les appels TensorFlow est généralement sûr et évite la copie de données. Voir la section sur l' interopérabilité de TensorFlow pour plus de détails.
Priorité des opérateurs
TensorFlow NumPy définit une __array_priority__ supérieure à celle de NumPy. Cela signifie que pour les opérateurs impliquant à la fois un tableau ND et np.ndarray , le premier aura priorité, c'est-à-dire que l'entrée np.ndarray sera convertie en un tableau ND et l'implémentation TensorFlow NumPy de l'opérateur sera invoquée.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy et TensorFlow
TensorFlow NumPy est construit sur TensorFlow et interagit donc de manière transparente avec TensorFlow.
tf.Tensor et tableau ND
Le tableau ND est un alias de tf.Tensor , ils peuvent donc évidemment être mélangés sans déclencher de copies de données réelles.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interopérabilité TensorFlow
Un tableau ND peut être transmis aux API TensorFlow, car le tableau ND n'est qu'un alias de tf.Tensor . Comme mentionné précédemment, une telle interopérabilité ne fait pas de copies de données, même pour les données placées sur des accélérateurs ou des appareils distants.
Inversement, les objets tf.Tensor peuvent être transmis aux API tf.experimental.numpy , sans effectuer de copies de données.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Dégradés et jacobiens : tf.GradientTape
GradientTape de TensorFlow peut être utilisé pour la rétropropagation via le code TensorFlow et TensorFlow NumPy.
Utilisez le modèle créé dans la section Exemple de modèle et calculez les gradients et les jacobiens.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Compilation de traces : tf.fonction
La fonction tf.function de TensorFlow fonctionne en "compilant les traces" du code, puis en optimisant ces traces pour des performances beaucoup plus rapides. Voir Introduction aux graphes et aux fonctions .
tf.function peut également être utilisé pour optimiser le code TensorFlow NumPy. Voici un exemple simple pour démontrer les accélérations. Notez que le corps du code tf.function inclut des appels aux API TensorFlow NumPy.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vectorisation : tf.vectorized_map
TensorFlow prend en charge la vectorisation des boucles parallèles, ce qui permet des accélérations d'un à deux ordres de grandeur. Ces accélérations sont accessibles via l'API tf.vectorized_map et s'appliquent également au code TensorFlow NumPy.
Il est parfois utile de calculer le gradient de chaque sortie dans un lot par rapport à l'élément de lot d'entrée correspondant. Un tel calcul peut être effectué efficacement en utilisant tf.vectorized_map comme indiqué ci-dessous.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Emplacement de l'appareil
TensorFlow NumPy peut effectuer des opérations sur les CPU, les GPU, les TPU et les appareils distants. Il utilise les mécanismes TensorFlow standard pour le placement des appareils. Ci-dessous, un exemple simple montre comment répertorier tous les appareils, puis placer des calculs sur un appareil particulier.
TensorFlow dispose également d'API pour répliquer les calculs sur tous les appareils et effectuer des réductions collectives qui ne seront pas couvertes ici.
Lister les appareils
tf.config.list_logical_devices et tf.config.list_physical_devices peuvent être utilisés pour trouver les périphériques à utiliser.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Opérations de placement : tf.device
Les opérations peuvent être placées sur un périphérique en l'appelant dans une portée tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Copie de baies ND sur plusieurs appareils : tnp.copy
Un appel à tnp.copy , placé dans une certaine portée de périphérique, copiera les données sur ce périphérique, à moins que les données ne soient déjà sur ce périphérique.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
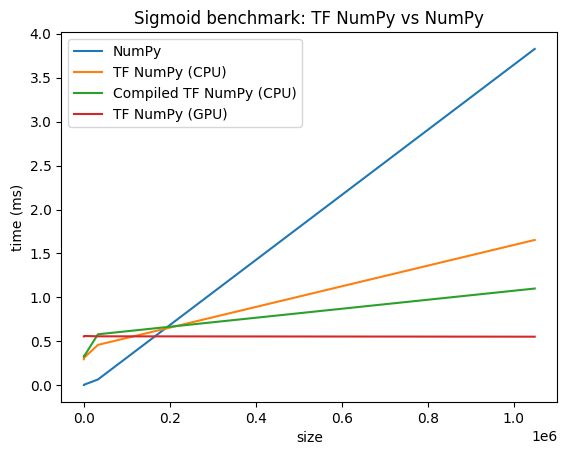
Comparaisons de performances
TensorFlow NumPy utilise des noyaux TensorFlow hautement optimisés qui peuvent être répartis sur les CPU, les GPU et les TPU. TensorFlow effectue également de nombreuses optimisations du compilateur, comme la fusion d'opérations, qui se traduisent par des améliorations des performances et de la mémoire. Voir Optimisation des graphiques TensorFlow avec Grappler pour en savoir plus.
Cependant, TensorFlow a des frais généraux plus élevés pour la répartition des opérations par rapport à NumPy. Pour les charges de travail composées de petites opérations (moins d'environ 10 microsecondes), ces frais généraux peuvent dominer le temps d'exécution et NumPy pourrait fournir de meilleures performances. Dans les autres cas, TensorFlow devrait généralement offrir de meilleures performances.
Exécutez le benchmark ci-dessous pour comparer les performances NumPy et TensorFlow NumPy pour différentes tailles d'entrée.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)