| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
TensorFlow implementuje podzbiór NumPy API , dostępny jako tf.experimental.numpy . Pozwala to na uruchamianie kodu NumPy, akcelerowanego przez TensorFlow, jednocześnie umożliwiając dostęp do wszystkich interfejsów API TensorFlow.
Ustawiać
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Włączanie zachowania NumPy
Aby używać tnp jako NumPy, włącz zachowanie NumPy dla TensorFlow:
tnp.experimental_enable_numpy_behavior()
To wywołanie umożliwia promocję typu w TensorFlow, a także zmienia wnioskowanie o typie podczas konwersji literałów na tensory, aby ściślej przestrzegać standardu NumPy.
Macierz TensorFlow NumPy ND
Instancja tf.experimental.numpy.ndarray , zwana ND Array , reprezentuje wielowymiarową gęstą tablicę danego typu dtype umieszczoną na określonym urządzeniu. Jest to alias tf.Tensor . Zapoznaj się z klasą tablicy ND, aby uzyskać przydatne metody, takie jak ndarray.T , ndarray.reshape , ndarray.ravel i inne.
Najpierw utwórz obiekt tablicy ND, a następnie wywołaj różne metody.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Wpisz promocja
Interfejsy API TensorFlow NumPy mają dobrze zdefiniowaną semantykę do konwersji literałów na tablicę ND, a także do przeprowadzania promocji typu na wejściach tablicy ND. Zobacz np.result_type , aby uzyskać więcej informacji.
Interfejsy API TensorFlow pozostawiają wejścia tf.Tensor bez zmian i nie wykonują na nich promocji typu, podczas gdy interfejsy API TensorFlow NumPy promują wszystkie wejścia zgodnie z regułami promocji typu NumPy. W następnym przykładzie wykonasz promocję typu. Najpierw uruchom dodawanie na wejściach tablicy ND różnych typów i zanotuj typy wyjść. Żadna z tych promocji nie byłaby dozwolona przez interfejsy API TensorFlow.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Na koniec przekonwertuj literały na tablicę ND za pomocą ndarray.asarray i zanotuj wynikowy typ.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Podczas konwertowania literałów na tablicę ND, NumPy preferuje szerokie typy, takie jak tnp.int64 i tnp.float64 . Natomiast tf.convert_to_tensor preferuje typy tf.int32 i tf.float32 do konwertowania stałych na tf.Tensor . Interfejsy API TensorFlow NumPy są zgodne z zachowaniem NumPy dla liczb całkowitych. Jeśli chodzi o pływaki, argument prefer_float32 experimental_enable_numpy_behavior pozwala kontrolować, czy preferować tf.float32 tf.float64 (domyślnie False ). Na przykład:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Nadawanie
Podobnie jak TensorFlow, NumPy definiuje bogatą semantykę dla wartości „nadawania”. Możesz zapoznać się z przewodnikiem nadawania NumPy, aby uzyskać więcej informacji i porównać to z semantyką nadawania TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Indeksowanie
NumPy definiuje bardzo wyrafinowane zasady indeksowania. Zobacz przewodnik indeksowania NumPy . Zwróć uwagę na użycie tablic ND jako wskaźników poniżej.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Przykładowy model
Następnie możesz zobaczyć, jak utworzyć model i przeprowadzić na nim wnioskowanie. Ten prosty model nakłada warstwę relu, po której następuje rzut liniowy. Późniejsze sekcje pokażą, jak obliczyć gradienty dla tego modelu za pomocą GradientTape firmy TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy i NumPy
TensorFlow NumPy implementuje podzbiór pełnej specyfikacji NumPy. Chociaż z czasem dodanych zostanie więcej symboli, istnieją systematyczne funkcje, które nie będą obsługiwane w najbliższej przyszłości. Należą do nich obsługa interfejsu API NumPy C, integracja Swig, kolejność przechowywania Fortran, widoki i stride_tricks oraz niektóre dtype s (takie jak np.recarray i np.object ). Aby uzyskać więcej informacji, zapoznaj się z dokumentacją TensorFlow NumPy API .
Interoperacyjność NumPy
Macierze TensorFlow ND mogą współpracować z funkcjami NumPy. Te obiekty implementują interfejs __array__ . NumPy używa tego interfejsu do konwertowania argumentów funkcji na wartości np.ndarray przed ich przetworzeniem.
Podobnie funkcje TensorFlow NumPy mogą akceptować dane wejściowe różnych typów, w tym np.ndarray . Te dane wejściowe są konwertowane na tablicę ND przez wywołanie na nich ndarray.asarray .
Konwersja tablicy ND do iz np.ndarray może wywołać rzeczywiste kopie danych. Więcej informacji można znaleźć w sekcji o kopiach buforowych .
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Kopie buforowe
Mieszanie TensorFlow NumPy z kodem NumPy może powodować kopiowanie danych. Dzieje się tak, ponieważ TensorFlow NumPy ma bardziej rygorystyczne wymagania dotyczące wyrównania pamięci niż NumPy.
Gdy np.ndarray zostanie przekazany do TensorFlow NumPy, sprawdzi on wymagania dotyczące wyrównania i w razie potrzeby uruchomi kopię. Podczas przekazywania bufora procesora tablicy ND do NumPy, ogólnie bufor spełni wymagania wyrównania i NumPy nie będzie musiał tworzyć kopii.
Tablice ND mogą odnosić się do buforów umieszczonych na urządzeniach innych niż lokalna pamięć procesora. W takich przypadkach wywołanie funkcji NumPy spowoduje uruchomienie kopii w sieci lub urządzeniu w razie potrzeby.
Biorąc to pod uwagę, mieszanie z wywołaniami API NumPy powinno być wykonywane z ostrożnością, a użytkownik powinien uważać na narzuty związane z kopiowaniem danych. Przeplatanie wywołań TensorFlow NumPy z wywołaniami TensorFlow jest ogólnie bezpieczne i pozwala uniknąć kopiowania danych. Zobacz sekcję dotyczącą współdziałania TensorFlow , aby uzyskać więcej informacji.
Pierwszeństwo operatora
TensorFlow NumPy definiuje __array_priority__ wyższy niż NumPy. Oznacza to, że w przypadku operatorów obejmujących zarówno tablicę ND, jak i np.ndarray , pierwszeństwo będzie miał ten pierwszy, tj. dane wejściowe np.ndarray zostaną przekonwertowane na tablicę ND i zostanie wywołana implementacja operatora TensorFlow NumPy.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy i TensorFlow
TensorFlow NumPy jest zbudowany na bazie TensorFlow, dzięki czemu bezproblemowo współpracuje z TensorFlow.
tf.Tensor i tablica ND
Tablica ND jest aliasem do tf.Tensor , więc oczywiście można je mieszać bez wyzwalania rzeczywistych kopii danych.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interoperacyjność TensorFlow
Tablica ND może zostać przekazana do API TensorFlow, ponieważ tablica ND jest tylko aliasem do tf.Tensor . Jak wspomniano wcześniej, taka współpraca nie wykonuje kopii danych, nawet danych umieszczonych na akceleratorach lub urządzeniach zdalnych.
I odwrotnie, obiekty tf.Tensor można przekazywać do interfejsów API tf.experimental.numpy bez wykonywania kopii danych.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradienty i jakobiany: tf.GradientTape
GradientTape firmy TensorFlow może być używana do wstecznej propagacji błędów za pomocą kodu TensorFlow i TensorFlow NumPy.
Użyj modelu utworzonego w sekcji Przykładowy model i oblicz gradienty i jakoby.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Kompilacja śladów: tf.function
Funkcja tf.Flow w tf.function działa poprzez "kompilację śledzenia" kodu, a następnie optymalizację tych śladów w celu uzyskania znacznie większej wydajności. Zobacz Wprowadzenie do wykresów i funkcji .
tf.function może być również użyty do optymalizacji kodu TensorFlow NumPy. Oto prosty przykład demonstrujący przyspieszenia. Zwróć uwagę, że treść kodu tf.function zawiera wywołania interfejsów API TensorFlow NumPy.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Wektoryzacja: tf.vectorized_map
TensorFlow ma wbudowaną obsługę wektoryzacji pętli równoległych, co pozwala na przyspieszenie od jednego do dwóch rzędów wielkości. Te przyspieszenia są dostępne za pośrednictwem interfejsu API tf.vectorized_map i dotyczą również kodu TensorFlow NumPy.
Czasami przydatne jest obliczenie gradientu każdego wyjścia w partii względem odpowiedniego wejściowego elementu partii. Takie obliczenia można wykonać wydajnie za pomocą tf.vectorized_map , jak pokazano poniżej.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Umieszczenie urządzenia
TensorFlow NumPy może wykonywać operacje na procesorach, GPU, TPU i urządzeniach zdalnych. Wykorzystuje standardowe mechanizmy TensorFlow do umieszczania urządzeń. Poniżej prosty przykład pokazuje, jak wyświetlić listę wszystkich urządzeń, a następnie umieścić obliczenia na konkretnym urządzeniu.
TensorFlow ma również interfejsy API do replikacji obliczeń na różnych urządzeniach i wykonywania zbiorczych redukcji, które nie zostaną tutaj omówione.
Lista urządzeń
tf.config.list_logical_devices i tf.config.list_physical_devices mogą służyć do wyszukiwania urządzeń do użycia.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Operacje umieszczania: tf.device
Operacje można umieszczać na urządzeniu, wywołując je w zakresie tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Kopiowanie tablic ND między urządzeniami: tnp.copy
Wywołanie tnp.copy , umieszczone w określonym zakresie urządzenia, skopiuje dane na to urządzenie, chyba że dane są już na tym urządzeniu.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
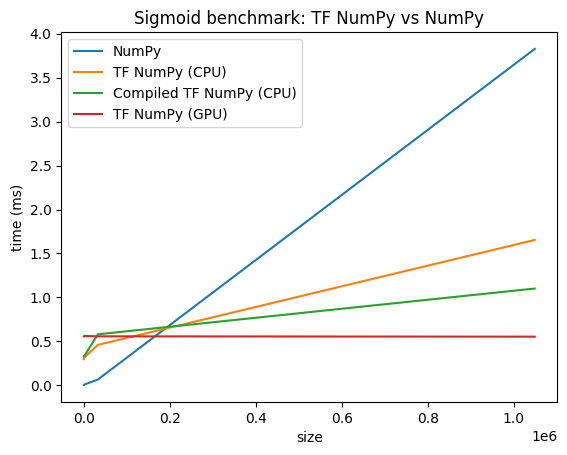
Porównania wydajności
TensorFlow NumPy wykorzystuje wysoce zoptymalizowane jądra TensorFlow, które mogą być wysyłane na procesory, GPU i TPU. TensorFlow przeprowadza również wiele optymalizacji kompilatorów, takich jak fuzja operacji, co przekłada się na poprawę wydajności i pamięci. Zobacz Optymalizacja wykresów TensorFlow za pomocą Grapplera , aby dowiedzieć się więcej.
Jednak TensorFlow ma wyższe koszty ogólne operacji wysyłania w porównaniu z NumPy. W przypadku obciążeń składających się z małych operacji (mniej niż około 10 mikrosekund) te koszty ogólne mogą zdominować środowisko uruchomieniowe, a NumPy może zapewnić lepszą wydajność. W innych przypadkach TensorFlow powinien ogólnie zapewniać lepszą wydajność.
Uruchom poniższy test porównawczy, aby porównać wydajność NumPy i TensorFlow NumPy dla różnych rozmiarów danych wejściowych.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)