| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
TensorFlow ใช้ชุดย่อยของ NumPy API ซึ่งมีอยู่ใน tf.experimental.numpy ซึ่งช่วยให้เรียกใช้โค้ด NumPy ซึ่งเร่งความเร็วโดย TensorFlow ในขณะเดียวกันก็อนุญาตให้เข้าถึง API ของ TensorFlow ทั้งหมดได้
ติดตั้ง
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
เปิดใช้งานพฤติกรรม NumPy
เพื่อที่จะใช้ tnp เป็น NumPy ให้เปิดใช้งานพฤติกรรม NumPy สำหรับ TensorFlow:
tnp.experimental_enable_numpy_behavior()
การเรียกนี้เปิดใช้งานการเลื่อนประเภทประเภทใน TensorFlow และยังเปลี่ยนการอนุมานประเภท เมื่อแปลงตัวอักษรเป็นเทนเซอร์ เพื่อให้เป็นไปตามมาตรฐาน NumPy อย่างเคร่งครัดยิ่งขึ้น
TensorFlow NumPy ND array
ตัวอย่างของ tf.experimental.numpy.ndarray ที่เรียกว่า ND Array แสดงถึงอาร์เรย์หนาแน่นหลายมิติของ dtype ที่กำหนดซึ่งวางไว้บนอุปกรณ์บางอย่าง เป็นนามแฝงของ tf.Tensor ตรวจสอบคลาสอาร์เรย์ ND เพื่อดูวิธีการที่มีประโยชน์ เช่น ndarray.T , ndarray.reshape , ndarray.ravel และอื่นๆ
ขั้นแรกให้สร้างวัตถุอาร์เรย์ ND แล้วเรียกใช้วิธีการต่างๆ
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
พิมพ์โปรโมชั่น
TensorFlow NumPy APIs มีความหมายที่ชัดเจนสำหรับการแปลงตัวอักษรเป็นอาร์เรย์ ND เช่นเดียวกับการดำเนินการส่งเสริมประเภทบนอินพุตอาร์เรย์ ND โปรดดู np.result_type สำหรับรายละเอียดเพิ่มเติม
TensorFlow APIs ปล่อยให้อินพุต tf.Tensor ไม่เปลี่ยนแปลง และไม่ดำเนินการส่งเสริมประเภทกับอินพุตเหล่านั้น ในขณะที่ TensorFlow NumPy APIs จะส่งเสริมอินพุตทั้งหมดตามกฎการส่งเสริมประเภท NumPy ในตัวอย่างถัดไป คุณจะดำเนินการส่งเสริมประเภท ขั้นแรก ให้รันเพิ่มเติมบนอินพุตอาร์เรย์ ND ประเภทต่างๆ และจดบันทึกประเภทเอาต์พุต TensorFlow APIs จะไม่อนุญาตให้โปรโมตประเภทนี้
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
สุดท้าย แปลงตัวอักษรเป็นอาร์เรย์ ND โดยใช้ ndarray.asarray และบันทึกประเภทผลลัพธ์
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
เมื่อแปลงตัวอักษรเป็นอาร์เรย์ ND NumPy ชอบประเภทกว้างเช่น tnp.int64 และ tnp.float64 ในทางตรงกันข้าม tf.convert_to_tensor ชอบประเภท tf.int32 และ tf.float32 สำหรับการแปลงค่าคงที่เป็น tf.Tensor TensorFlow NumPy APIs ยึดตามพฤติกรรม NumPy สำหรับจำนวนเต็ม สำหรับการลอยตัว อาร์กิวเมนต์ prefer_float32 ของ experimental_enable_numpy_behavior ให้คุณควบคุมว่าจะชอบ tf.float32 มากกว่า tf.float64 หรือไม่ (ค่าเริ่มต้นเป็น False ) ตัวอย่างเช่น:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
ออกอากาศ
คล้ายกับ TensorFlow NumPy กำหนดความหมายที่สมบูรณ์สำหรับค่า "การแพร่ภาพ" คุณสามารถดูข้อมูลเพิ่มเติมใน คู่มือการออกอากาศ NumPy และเปรียบเทียบกับความหมายของ การออกอากาศ TensorFlow
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
การจัดทำดัชนี
NumPy กำหนดกฎการจัดทำดัชนีที่ซับซ้อนมาก ดู คู่มือการจัดทำดัชนี NumPy สังเกตการใช้อาร์เรย์ ND เป็นดัชนีด้านล่าง
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
ตัวอย่างรุ่น
ถัดไป คุณสามารถดูวิธีสร้างแบบจำลองและเรียกใช้การอนุมานได้ โมเดลง่ายๆ นี้ใช้เลเยอร์ relu ตามด้วยเส้นโครงเชิงเส้น ส่วนต่อมาจะแสดงวิธีคำนวณการไล่ระดับสีสำหรับโมเดลนี้โดยใช้ GradientTape ของ TensorFlow
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy และ NumPy
TensorFlow NumPy ใช้ชุดย่อยของข้อมูลจำเพาะ NumPy แบบเต็ม แม้ว่าจะมีการเพิ่มสัญลักษณ์มากขึ้นเมื่อเวลาผ่านไป แต่ก็มีคุณลักษณะที่เป็นระบบที่จะไม่ได้รับการสนับสนุนในอนาคตอันใกล้นี้ ซึ่งรวมถึงการสนับสนุน NumPy C API, การรวม Swig, ลำดับการจัดเก็บ Fortran, มุมมองและ stride_tricks และ dtype บางส่วน (เช่น np.recarray และ np.object ) สำหรับรายละเอียดเพิ่มเติม โปรดดูเอกสารประกอบ TensorFlow NumPy API
การทำงานร่วมกันของ NumPy
อาร์เรย์ TensorFlow ND สามารถทำงานร่วมกับฟังก์ชัน NumPy ออบเจ็กต์เหล่านี้ใช้อินเทอร์เฟซ __array__ NumPy ใช้อินเทอร์เฟซนี้เพื่อแปลงอาร์กิวเมนต์ของฟังก์ชันเป็นค่า np.ndarray ก่อนประมวลผล
ในทำนองเดียวกัน ฟังก์ชัน TensorFlow NumPy สามารถรับอินพุตประเภทต่างๆ รวมทั้ง np.ndarray อินพุตเหล่านี้จะถูกแปลงเป็นอาร์เรย์ ND โดยเรียก ndarray.asarray
การแปลงอาร์เรย์ ND เป็นและกลับจาก np.ndarray อาจทำให้เกิดการคัดลอกข้อมูลจริง โปรดดูส่วน บัฟเฟอร์สำเนา สำหรับรายละเอียดเพิ่มเติม
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
สำเนาบัฟเฟอร์
การผสมระหว่าง TensorFlow NumPy ด้วยรหัส NumPy อาจทำให้เกิดการคัดลอกข้อมูล เนื่องจาก TensorFlow NumPy มีข้อกำหนดในการจัดตำแหน่งหน่วยความจำที่เข้มงวดกว่า NumPy
เมื่อ np.ndarray ถูกส่งไปยัง TensorFlow NumPy จะตรวจสอบข้อกำหนดการจัดตำแหน่งและเรียกใช้สำเนาหากจำเป็น เมื่อส่งบัฟเฟอร์ CPU ND array ไปยัง NumPy โดยทั่วไปแล้วบัฟเฟอร์จะเป็นไปตามข้อกำหนดการจัดตำแหน่งและ NumPy จะไม่จำเป็นต้องสร้างสำเนา
อาร์เรย์ ND สามารถอ้างถึงบัฟเฟอร์ที่วางอยู่บนอุปกรณ์อื่นที่ไม่ใช่หน่วยความจำ CPU ในเครื่อง ในกรณีดังกล่าว การเรียกใช้ฟังก์ชัน NumPy จะทริกเกอร์การคัดลอกผ่านเครือข่ายหรืออุปกรณ์ตามความจำเป็น
จากสิ่งนี้ การผสมผสานกับการเรียก NumPy API ควรทำด้วยความระมัดระวัง และผู้ใช้ควรระวังโอเวอร์เฮดในการคัดลอกข้อมูล การโทรระหว่าง TensorFlow NumPy กับการโทร TensorFlow โดยทั่วไปจะปลอดภัยและหลีกเลี่ยงการคัดลอกข้อมูล ดูหัวข้อความสามารถในการทำงานร่วมกันของ TensorFlow สำหรับรายละเอียดเพิ่มเติม
ลำดับความสำคัญของตัวดำเนินการ
TensorFlow NumPy กำหนด __array_priority__ ที่สูงกว่าของ NumPy ซึ่งหมายความว่าสำหรับโอเปอเรเตอร์ที่เกี่ยวข้องกับทั้ง ND array และ np.ndarray อดีตจะมีความสำคัญเหนือกว่า กล่าวคือ อินพุต np.ndarray จะถูกแปลงเป็นอาร์เรย์ ND และการใช้งาน TensorFlow NumPy ของโอเปอเรเตอร์จะถูกเรียกใช้
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy และ TensorFlow
TensorFlow NumPy สร้างขึ้นบน TensorFlow และทำงานร่วมกับ TensorFlow ได้อย่างราบรื่น
tf.Tensor และอาร์เรย์ ND
ND array เป็นนามแฝงของ tf.Tensor ดังนั้นจึงสามารถผสมกันได้โดยไม่ทำให้เกิดการคัดลอกข้อมูลจริง
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
การทำงานร่วมกันของ TensorFlow
อาร์เรย์ ND สามารถส่งผ่านไปยัง TensorFlow API ได้ เนื่องจากอาร์เรย์ ND เป็นเพียงนามแฝงสำหรับ tf.Tensor ดังที่ได้กล่าวไว้ก่อนหน้านี้ การทำงานร่วมกันดังกล่าวจะไม่ทำสำเนาข้อมูล แม้แต่ข้อมูลที่วางอยู่บนคันเร่งหรืออุปกรณ์ระยะไกล
ในทางกลับกัน ออบเจ็กต์ tf.Tensor สามารถส่งผ่านไปยัง API tf.experimental.numpy ได้โดยไม่ต้องทำการคัดลอกข้อมูล
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
การไล่ระดับสีและจาโคเบียน: tf.GradientTape
GradientTape ของ TensorFlow สามารถใช้สำหรับการขยายพันธุ์ย้อนหลังผ่านโค้ด TensorFlow และ TensorFlow NumPy
ใช้แบบจำลองที่สร้างขึ้นในส่วน แบบจำลองตัวอย่าง และคำนวณการไล่ระดับสีและจาโคเบียน
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
การรวบรวมการติดตาม: tf.function
tf.function ของ tf.function ทำงานโดย "รวบรวมการติดตาม" โค้ด จากนั้นจึงปรับการติดตามเหล่านี้ให้เหมาะสมเพื่อประสิทธิภาพที่รวดเร็วยิ่งขึ้น ดูข้อมูล เบื้องต้นเกี่ยวกับกราฟและฟังก์ชัน
tf.function สามารถใช้เพื่อเพิ่มประสิทธิภาพโค้ด TensorFlow NumPy ได้เช่นกัน นี่เป็นตัวอย่างง่ายๆ ในการสาธิตการเพิ่มความเร็ว โปรดทราบว่าเนื้อหาของโค้ด tf.function มีการเรียก TensorFlow NumPy API
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
เวกเตอร์: tf.vectorized_map
TensorFlow มีการสนับสนุนในตัวสำหรับการสร้างเวคเตอร์ลูปคู่ขนาน ซึ่งช่วยให้เร่งความเร็วได้ตั้งแต่หนึ่งถึงสองลำดับความสำคัญ การเร่งความเร็วเหล่านี้สามารถเข้าถึงได้ผ่านทาง tf.vectorized_map API และนำไปใช้กับโค้ด TensorFlow NumPy ด้วย
บางครั้งมีประโยชน์ในการคำนวณการไล่ระดับสีของแต่ละเอาต์พุตในแบตช์ wrt องค์ประกอบแบทช์อินพุตที่สอดคล้องกัน การคำนวณดังกล่าวสามารถทำได้อย่างมีประสิทธิภาพโดยใช้ tf.vectorized_map ดังที่แสดงด้านล่าง
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
ตำแหน่งอุปกรณ์
TensorFlow NumPy สามารถดำเนินการกับ CPU, GPU, TPU และอุปกรณ์ระยะไกล ใช้กลไก TensorFlow มาตรฐานสำหรับการจัดวางอุปกรณ์ ด้านล่างตัวอย่างง่ายๆ จะแสดงวิธีการแสดงรายการอุปกรณ์ทั้งหมด จากนั้นจึงทำการคำนวณบนอุปกรณ์หนึ่งๆ
TensorFlow ยังมี API สำหรับการจำลองการคำนวณข้ามอุปกรณ์และดำเนินการลดแบบรวมซึ่งจะไม่ครอบคลุมในที่นี้
รายการอุปกรณ์
สามารถใช้ tf.config.list_logical_devices และ tf.config.list_physical_devices เพื่อค้นหาอุปกรณ์ที่จะใช้
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
การดำเนินการวาง: tf.device
สามารถวางการทำงานบนอุปกรณ์ได้โดยการเรียกอุปกรณ์นั้นในขอบเขต tf.device
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0ตัวยึดตำแหน่ง42
การคัดลอกอาร์เรย์ ND ระหว่างอุปกรณ์ต่างๆ: tnp.copy
การเรียก tnp.copy ซึ่งอยู่ในขอบเขตอุปกรณ์บางอย่าง จะคัดลอกข้อมูลไปยังอุปกรณ์นั้น เว้นแต่ว่าข้อมูลจะอยู่ในอุปกรณ์นั้นอยู่แล้ว
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
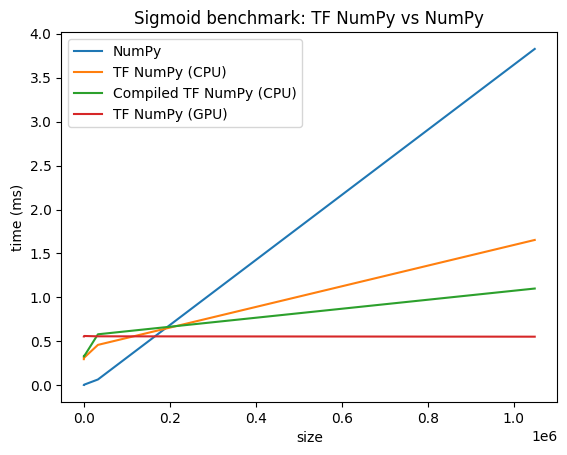
การเปรียบเทียบประสิทธิภาพ
TensorFlow NumPy ใช้เคอร์เนล TensorFlow ที่ได้รับการปรับแต่งอย่างสูงซึ่งสามารถจัดส่งบน CPU, GPU และ TPU TensorFlow ยังทำการเพิ่มประสิทธิภาพคอมไพเลอร์หลายอย่าง เช่น การผสานการทำงาน ซึ่งแปลเป็นการปรับปรุงประสิทธิภาพและหน่วยความจำ ดู การเพิ่มประสิทธิภาพกราฟ TensorFlow ด้วย Grappler เพื่อเรียนรู้เพิ่มเติม
อย่างไรก็ตาม TensorFlow มีค่าใช้จ่ายสูงกว่าสำหรับการดำเนินการจัดส่งเมื่อเปรียบเทียบกับ NumPy สำหรับปริมาณงานที่ประกอบด้วยการดำเนินการขนาดเล็ก (น้อยกว่าประมาณ 10 ไมโครวินาที) โอเวอร์เฮดเหล่านี้สามารถครอบงำรันไทม์ได้ และ NumPy สามารถให้ประสิทธิภาพที่ดีขึ้น สำหรับกรณีอื่นๆ โดยทั่วไป TensorFlow ควรให้ประสิทธิภาพที่ดีกว่า
เรียกใช้เบนช์มาร์กด้านล่างเพื่อเปรียบเทียบประสิทธิภาพของ NumPy และ TensorFlow NumPy สำหรับขนาดอินพุตต่างๆ
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)