| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
TensorFlow NumPy API का एक सबसेट लागू करता है, जो tf.experimental.numpy के रूप में उपलब्ध है। यह TensorFlow द्वारा त्वरित किए गए NumPy कोड को चलाने की अनुमति देता है, जबकि TensorFlow के सभी API तक पहुंच की भी अनुमति देता है।
सेट अप
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
NumPy व्यवहार को सक्षम करना
Tnp को NumPy के रूप में उपयोग करने के लिए, tnp के लिए NumPy व्यवहार को सक्षम करें:
tnp.experimental_enable_numpy_behavior()
यह कॉल TensorFlow में टाइप प्रमोशन को सक्षम बनाता है और NumPy मानक का अधिक सख्ती से पालन करने के लिए, शाब्दिक को टेंसर में परिवर्तित करते समय, प्रकार के अनुमान को भी बदलता है।
TensorFlow NumPy ND सरणी
tf.experimental.numpy.ndarray का एक उदाहरण, जिसे ND Array कहा जाता है, एक निश्चित डिवाइस पर रखे गए dtype के बहुआयामी घने सरणी का प्रतिनिधित्व करता है। यह tf.Tensor का उपनाम है। उपयोगी विधियों जैसे ndarray.T , ndarray.reshape , ndarray.ravel और अन्य के लिए ND सरणी वर्ग देखें।
पहले एक एनडी सरणी ऑब्जेक्ट बनाएं, और फिर विभिन्न विधियों का आह्वान करें।
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
प्रचार टाइप करें
TensorFlow NumPy API में अक्षर को ND सरणी में बदलने के साथ-साथ ND सरणी इनपुट पर टाइप प्रमोशन करने के लिए अच्छी तरह से परिभाषित शब्दार्थ है। अधिक जानकारी के लिए कृपया np.result_type देखें।
tf.Tensor APIs tf को छोड़ देते हैं। अगले उदाहरण में, आप टाइप प्रमोशन करेंगे। सबसे पहले, विभिन्न प्रकार के एनडी सरणी इनपुट पर अतिरिक्त चलाएं और आउटपुट प्रकारों को नोट करें। TensorFlow API द्वारा इनमें से किसी भी प्रकार के प्रचार की अनुमति नहीं दी जाएगी।
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
अंत में, ndarray.asarray का उपयोग करके अक्षर को ND सरणी में बदलें और परिणामी प्रकार को नोट करें।
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
अक्षर को ND सरणी में परिवर्तित करते समय, NumPy tnp.int64 और tnp.float64 जैसे विस्तृत प्रकारों को प्राथमिकता देता है। इसके विपरीत, tf.convert_to_tensor स्थिरांक को tf.Tensor में बदलने के लिए tf.int32 और tf.float32 प्रकारों को प्राथमिकता देता है। TensorFlow NumPy API पूर्णांकों के लिए NumPy व्यवहार का पालन करता है। जहां तक फ़्लोट्स का प्रश्न है, experimental_enable_numpy_behavior enable_numpy_behavior का prefer_float32 तर्क आपको यह नियंत्रित करने देता है कि क्या tf.float32 पर tf.float64 (डिफ़ॉल्ट रूप से False ) को प्राथमिकता दी जाए। उदाहरण के लिए:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
प्रसारण
TensorFlow के समान, NumPy "प्रसारण" मूल्यों के लिए समृद्ध शब्दार्थ को परिभाषित करता है। आप अधिक जानकारी के लिए NumPy ब्रॉडकास्टिंग गाइड देख सकते हैं और इसकी तुलना TensorFlow ब्रॉडकास्टिंग सेमेन्टिक्स से कर सकते हैं।
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
इंडेक्सिंग
NumPy बहुत परिष्कृत अनुक्रमण नियमों को परिभाषित करता है। NumPy अनुक्रमण मार्गदर्शिका देखें। नीचे दिए गए सूचकांकों के रूप में एनडी सरणियों के उपयोग पर ध्यान दें।
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
उदाहरण मॉडल
इसके बाद, आप देख सकते हैं कि एक मॉडल कैसे बनाया जाता है और उस पर अनुमान कैसे चलाया जाता है। यह सरल मॉडल एक रेखीय प्रक्षेपण के बाद एक रिले परत लागू करता है। बाद के खंड दिखाएंगे कि TensorFlow के GradientTape का उपयोग करके इस मॉडल के लिए ग्रेडिएंट की गणना कैसे करें।
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy और NumPy
TensorFlow NumPy पूर्ण NumPy युक्ति के सबसेट को लागू करता है। जबकि समय के साथ और प्रतीकों को जोड़ा जाएगा, ऐसी व्यवस्थित विशेषताएं हैं जो निकट भविष्य में समर्थित नहीं होंगी। इनमें NumPy C API सपोर्ट, स्विग इंटीग्रेशन, फोरट्रान स्टोरेज ऑर्डर, व्यू और stride_tricks और कुछ dtype s (जैसे np.recarray और np.object ) शामिल हैं। अधिक जानकारी के लिए, कृपया TensorFlow NumPy API Documentation देखें।
NumPy इंटरऑपरेबिलिटी
TensorFlow ND सरणियाँ NumPy फ़ंक्शंस के साथ इंटरऑपरेट कर सकती हैं। ये ऑब्जेक्ट __array__ इंटरफ़ेस को लागू करते हैं। NumPy इस इंटरफ़ेस का उपयोग फ़ंक्शन तर्कों को संसाधित करने से पहले np.ndarray मानों में बदलने के लिए करता है।
इसी तरह, TensorFlow NumPy फ़ंक्शन np.ndarray सहित विभिन्न प्रकार के इनपुट स्वीकार कर सकते हैं। इन इनपुट को ndarray.asarray पर कॉल करके ND सरणी में बदल दिया जाता है।
ND सरणी का np.ndarray में और उससे रूपांतरण वास्तविक डेटा प्रतियों को ट्रिगर कर सकता है। कृपया अधिक विवरण के लिए बफर प्रतियों पर अनुभाग देखें।
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
बफर प्रतियां
NumPy कोड के साथ TensorFlow NumPy को इंटरमिक्स करने से डेटा कॉपी ट्रिगर हो सकती है। ऐसा इसलिए है क्योंकि TensorFlow NumPy में NumPy की तुलना में मेमोरी एलाइनमेंट पर सख्त आवश्यकताएं हैं।
जब एक np.ndarray TensorFlow NumPy को पास किया जाता है, तो यह संरेखण आवश्यकताओं की जांच करेगा और यदि आवश्यक हो तो एक प्रति ट्रिगर करेगा। NumPy को ND सरणी CPU बफर पास करते समय, आम तौर पर बफर संरेखण आवश्यकताओं को पूरा करेगा और NumPy को एक प्रति बनाने की आवश्यकता नहीं होगी।
ND सरणियाँ स्थानीय CPU मेमोरी के अलावा अन्य उपकरणों पर रखे गए बफ़र्स को संदर्भित कर सकती हैं। ऐसे मामलों में, NumPy फ़ंक्शन को लागू करने से आवश्यकतानुसार पूरे नेटवर्क या डिवाइस पर कॉपी ट्रिगर हो जाएगी।
इसे देखते हुए, NumPy API कॉल्स के साथ इंटरमिक्स करना आम तौर पर सावधानी के साथ किया जाना चाहिए और उपयोगकर्ता को डेटा कॉपी करने के ओवरहेड्स पर ध्यान देना चाहिए। TensorFlow कॉल के साथ TensorFlow NumPy कॉल को इंटरलीव करना आम तौर पर सुरक्षित होता है और डेटा कॉपी करने से बचता है। अधिक विवरण के लिए TensorFlow इंटरऑपरेबिलिटी पर अनुभाग देखें।
संचालक वरीयता
TensorFlow NumPy NumPy की तुलना में __array_priority__ अधिक को परिभाषित करता है। इसका मतलब यह है कि ND सरणी और np.ndarray दोनों को शामिल करने वाले ऑपरेटरों के लिए, पूर्व को प्राथमिकता दी जाएगी, अर्थात, np.ndarray इनपुट एक ND सरणी में परिवर्तित हो जाएगा और ऑपरेटर के TensorFlow NumPy कार्यान्वयन को लागू किया जाएगा।
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy और TensorFlow
TensorFlow NumPy को TensorFlow के शीर्ष पर बनाया गया है और इसलिए यह TensorFlow के साथ निर्बाध रूप से इंटरऑपरेट करता है।
tf.Tensor और एनडी सरणी
एनडी सरणी tf.Tensor के लिए एक उपनाम है, इसलिए स्पष्ट रूप से उन्हें वास्तविक डेटा प्रतियों को ट्रिगर किए बिना इंटरमिक्स किया जा सकता है।
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>प्लेसहोल्डर26
TensorFlow इंटरऑपरेबिलिटी
एक ND सरणी को TensorFlow APIs को पास किया जा सकता है, क्योंकि ND सरणी tf.Tensor का केवल एक उपनाम है। जैसा कि पहले उल्लेख किया गया है, इस तरह का इंटरऑपरेशन डेटा कॉपी नहीं करता है, यहां तक कि एक्सेलेरेटर या रिमोट डिवाइस पर रखे गए डेटा के लिए भी।
इसके विपरीत, tf.Tensor ऑब्जेक्ट्स को tf.experimental.numpy APIs को डेटा कॉपी किए बिना पास किया जा सकता है।
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
ग्रेडिएंट्स और जैकोबियन: tf.GradientTape
TensorFlow के GradientTape का उपयोग TensorFlow और TensorFlow NumPy कोड के माध्यम से बैकप्रोपेगेशन के लिए किया जा सकता है।
उदाहरण मॉडल अनुभाग में बनाए गए मॉडल का उपयोग करें, और ग्रेडिएंट और जैकोबियन की गणना करें।
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
ट्रेस संकलन: tf.function
TensorFlow का tf.function कोड को "ट्रेस कंपाइलिंग" करके काम करता है और फिर इन ट्रेस को बहुत तेज प्रदर्शन के लिए अनुकूलित करता है। रेखांकन और कार्यों का परिचय देखें।
tf.function का उपयोग TensorFlow NumPy कोड को भी अनुकूलित करने के लिए किया जा सकता है। स्पीडअप प्रदर्शित करने के लिए यहां एक सरल उदाहरण दिया गया है। ध्यान दें कि tf.function कोड के मुख्य भाग में TensorFlow NumPy API को कॉल शामिल हैं।
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
सदिशीकरण: tf.vectorized_map
TensorFlow में समानांतर लूप को वेक्टराइज़ करने के लिए इनबिल्ट सपोर्ट है, जो परिमाण के एक से दो ऑर्डर के स्पीडअप की अनुमति देता है। ये tf.vectorized_map API के माध्यम से सुलभ हैं और TensorFlow NumPy कोड पर भी लागू होते हैं।
बैच में प्रत्येक आउटपुट के ग्रेडिएंट की गणना करने के लिए कभी-कभी उपयोगी होता है, जो संबंधित इनपुट बैच तत्व को wrt करता है। इस तरह की गणना tf.vectorized_map का उपयोग करके कुशलतापूर्वक की जा सकती है जैसा कि नीचे दिखाया गया है।
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
डिवाइस प्लेसमेंट
TensorFlow NumPy CPU, GPU, TPU और दूरस्थ उपकरणों पर संचालन कर सकता है। यह डिवाइस प्लेसमेंट के लिए मानक TensorFlow तंत्र का उपयोग करता है। एक सरल उदाहरण के नीचे दिखाता है कि सभी उपकरणों को कैसे सूचीबद्ध किया जाए और फिर किसी विशेष उपकरण पर कुछ गणना की जाए।
TensorFlow में सभी उपकरणों में गणना की नकल करने और सामूहिक कटौती करने के लिए एपीआई भी हैं जिन्हें यहां कवर नहीं किया जाएगा।
उपकरणों की सूची बनाएं
tf.config.list_logical_devices और tf.config.list_physical_devices का उपयोग यह पता लगाने के लिए किया जा सकता है कि किन उपकरणों का उपयोग करना है।
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
प्लेसमेंट ऑपरेशन: tf.device
किसी डिवाइस को tf.device स्कोप में कॉल करके उसके संचालन को रखा जा सकता है।
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
सभी उपकरणों में ND सरणियों की प्रतिलिपि बनाना: tnp.copy
tnp.copy को एक निश्चित डिवाइस स्कोप में रखा गया कॉल, डेटा को उस डिवाइस पर कॉपी कर देगा, जब तक कि डेटा पहले से ही उस डिवाइस पर न हो।
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
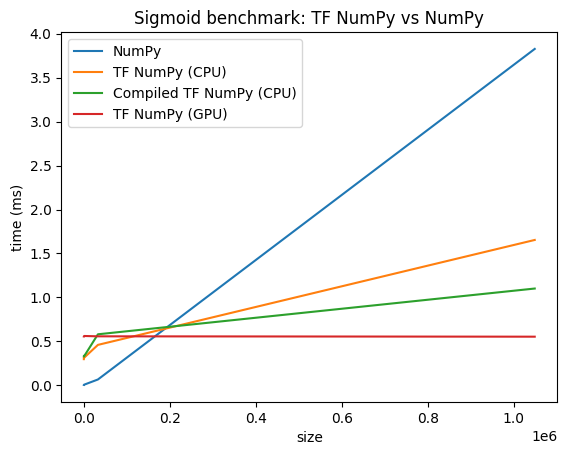
प्रदर्शन तुलना
TensorFlow NumPy अत्यधिक अनुकूलित TensorFlow कर्नेल का उपयोग करता है जिसे CPU, GPU और TPU पर भेजा जा सकता है। TensorFlow कई कंपाइलर ऑप्टिमाइज़ेशन भी करता है, जैसे ऑपरेशन फ़्यूज़न, जो प्रदर्शन और मेमोरी में सुधार के लिए अनुवाद करता है। अधिक जानने के लिए ग्रेप्लर के साथ TensorFlow ग्राफ़ ऑप्टिमाइज़ेशन देखें।
हालाँकि, TensorFlow में NumPy की तुलना में प्रेषण संचालन के लिए उच्च ओवरहेड्स हैं। छोटे ऑपरेशन (लगभग 10 माइक्रोसेकंड से कम) से बने वर्कलोड के लिए, ये ओवरहेड्स रनटाइम पर हावी हो सकते हैं और NumPy बेहतर प्रदर्शन प्रदान कर सकता है। अन्य मामलों के लिए, TensorFlow को आम तौर पर बेहतर प्रदर्शन प्रदान करना चाहिए।
विभिन्न इनपुट आकारों के लिए NumPy और TensorFlow NumPy प्रदर्शन की तुलना करने के लिए नीचे दिए गए बेंचमार्क को चलाएँ।
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)