
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin |
API Belgeleri: tf.RaggedTensor tf.ragged
Kurmak
import math
import tensorflow as tf
genel bakış
Verileriniz birçok şekilde gelir; tensörleriniz de öyle olmalı. Düzensiz tensörler , iç içe geçmiş değişken uzunluklu listelerin TensorFlow eşdeğeridir. Aşağıdakiler dahil, tek tip olmayan şekillerle verileri depolamayı ve işlemeyi kolaylaştırırlar:
- Bir filmdeki oyuncu seti gibi değişken uzunluktaki özellikler.
- Cümleler veya video klipler gibi değişken uzunluklu ardışık giriş grupları.
- Bölümlere, paragraflara, cümlelere ve sözcüklere bölünmüş metin belgeleri gibi hiyerarşik girdiler.
- Protokol arabellekleri gibi yapılandırılmış girdilerdeki bireysel alanlar.
Düzensiz bir tensör ile neler yapabilirsiniz?
Düzensiz tensörler, matematik işlemleri ( tf.add ve tf.reduce_mean gibi), dizi işlemleri ( tf.concat ve tf.tile gibi), dize işleme operasyonları ( tf.substr gibi) dahil yüzden fazla TensorFlow işlemi tarafından desteklenir. ), akış işlemlerini kontrol edin ( tf.while_loop ve tf.map_fn gibi) ve diğerleri:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Ayrıca fabrika yöntemleri, dönüştürme yöntemleri ve değer eşleme işlemleri dahil olmak üzere düzensiz tensörlere özgü bir dizi yöntem ve işlem vardır. Desteklenen işlemlerin listesi için tf.ragged paket belgelerine bakın.
Düzensiz tensörler, Keras , Datasets , tf.function , SavedModels ve tf.Example dahil olmak üzere birçok TensorFlow API'si tarafından desteklenir. Daha fazla bilgi için aşağıdaki TensorFlow API'leri bölümüne bakın.
Normal tensörlerde olduğu gibi, düzensiz tensörün belirli dilimlerine erişmek için Python tarzı indekslemeyi kullanabilirsiniz. Daha fazla bilgi için aşağıdaki Dizin Oluşturma bölümüne bakın.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Ve tıpkı normal tensörler gibi, eleman bazında işlemleri gerçekleştirmek için Python aritmetiği ve karşılaştırma operatörlerini kullanabilirsiniz. Daha fazla bilgi için aşağıdaki Aşırı Yüklenmiş operatörler bölümüne bakın.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>yer tutucu11 l10n-yer
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
RaggedTensor değerlerine öğe bazında bir dönüşüm gerçekleştirmeniz gerekiyorsa, bir işlev artı bir veya daha fazla bağımsız değişken alan ve işlevi tf.ragged.map_flat_values değerlerini dönüştürmek için uygulayan RaggedTensor RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Düzensiz tensörler, iç içe Python list s ve NumPy array s'ye dönüştürülebilir:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]yer tutucu17 l10n-yer
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Düzensiz bir tensör oluşturma
tf.ragged.constant bir tensör oluşturmanın en basit yolu, belirli bir iç içe Python list veya NumPy array karşılık gelen RaggedTensor oluşturan tf.ragged.constant kullanmaktır:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>yer tutucu21 l10n-yer
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Düzensiz tensörler, düz değer tensörlerini, bu değerlerin satırlara nasıl ayrılması gerektiğini gösteren satır bölümleme tensörleriyle eşleştirerek, tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths ve tf.RaggedTensor.from_row_splits gibi fabrika sınıf yöntemleri kullanılarak da oluşturulabilir.
tf.RaggedTensor.from_value_rowids
Her değerin hangi satıra ait olduğunu biliyorsanız, bir value_rowids satır bölümleme tensörü kullanarak bir RaggedTensor oluşturabilirsiniz:
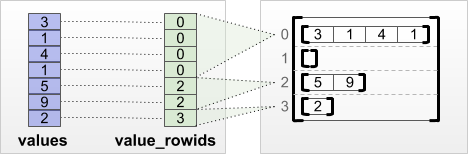
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Her satırın ne kadar uzun olduğunu biliyorsanız, o zaman bir row_lengths satır bölümleme tensörü kullanabilirsiniz:
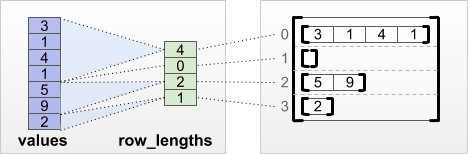
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Her satırın başladığı ve bittiği dizini biliyorsanız, bir row_splits satır bölümleme tensörü kullanabilirsiniz:
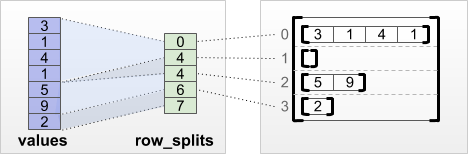
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Fabrika yöntemlerinin tam listesi için tf.RaggedTensor sınıfı belgelerine bakın.
Düzensiz bir tensörde ne saklayabilirsiniz?
Normal RaggedTensor Tensor tümü aynı tipte olmalıdır; ve değerlerin tümü aynı yuvalama derinliğinde olmalıdır (tensörün sırası ):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
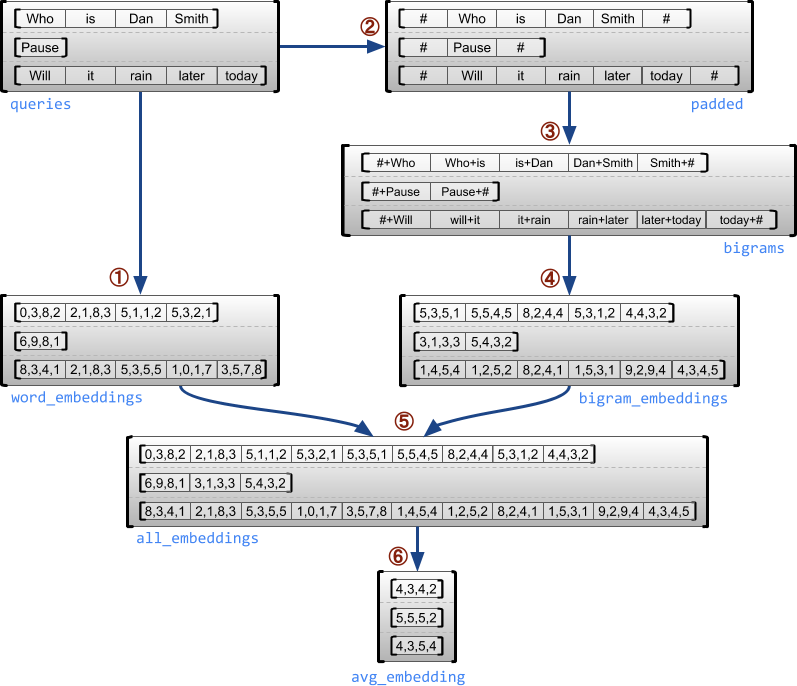
Örnek kullanım durumu
Aşağıdaki örnek, her cümlenin başı ve sonu için özel işaretler kullanarak, değişken uzunluktaki sorgular için unigram ve bigram yerleştirmelerini oluşturmak ve birleştirmek için RaggedTensor s'nin nasıl kullanılabileceğini gösterir. Bu örnekte kullanılan işlemler hakkında daha fazla ayrıntı için tf.ragged paket belgelerine bakın.
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Düzensiz ve tek tip boyutlar
Düzensiz boyut , dilimleri farklı uzunluklara sahip olabilen bir boyuttur. Örneğin, rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] öğesinin iç (sütun) boyutu, sütun dilimleri ( rt[0, :] , ..., rt[4, :] ) farklı uzunluklara sahiptir. Dilimleri aynı uzunlukta olan boyutlara tek biçimli boyutlar denir.
Düzensiz bir tensörün en dış boyutu, tek bir dilimden oluştuğu için her zaman tekdüzedir (ve bu nedenle, farklı dilim uzunlukları olasılığı yoktur). Kalan boyutlar düzensiz veya tek tip olabilir. Örneğin, [num_sentences, (num_words), embedding_size] şeklinde düzensiz bir tensör kullanarak her bir sözcük için sözcük yerleştirmelerini bir cümle yığınında saklayabilirsiniz, burada parantezler (num_words) boyutun düzensiz olduğunu gösterir.
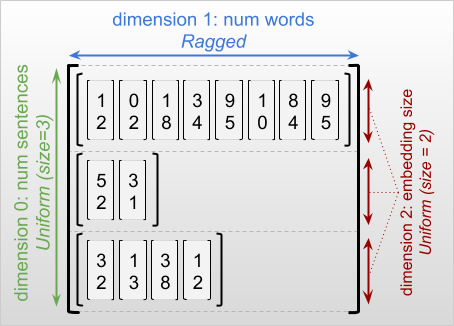
Düzensiz tensörler birden çok düzensiz boyuta sahip olabilir. Örneğin, [num_documents, (num_paragraphs), (num_sentences), (num_words)] şeklinde bir tensör kullanarak bir grup yapılandırılmış metin belgesi saklayabilirsiniz (burada düzensiz boyutları belirtmek için yine parantezler kullanılır).
tf.Tensor ile olduğu gibi, düzensiz bir tensörün rankı , toplam boyut sayısıdır (hem düzensiz hem de tek biçimli boyutlar dahil). Potansiyel olarak düzensiz bir tensör , tf.Tensor veya tf.RaggedTensor olabilen bir değerdir.
Bir RaggedTensor şeklini tanımlarken, düzensiz boyutlar geleneksel olarak parantez içine alınarak belirtilir. Örneğin, yukarıda gördüğünüz gibi, bir grup cümledeki her bir kelime için kelime yerleştirmelerini depolayan bir 3D RaggedTensor'ın şekli [num_sentences, (num_words), embedding_size] olarak yazılabilir.
RaggedTensor.shape özniteliği, düzensiz boyutların None boyutuna sahip olduğu düzensiz bir tensör için bir tf.TensorShape döndürür:
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
tf.RaggedTensor.bounding_shape yöntemi, belirli bir RaggedTensor için sıkı bir sınırlayıcı şekil bulmak için kullanılabilir:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Düzensiz vs seyrek
Düzensiz bir tensör, bir tür seyrek tensör olarak düşünülmemelidir . Özellikle, seyrek tensörler, aynı verileri kompakt bir biçimde modelleyen tf.Tensor için verimli kodlamalardır ; ancak düzensiz tensör, genişletilmiş bir veri sınıfını tf.Tensor bir uzantısıdır . Bu fark, işlemleri tanımlarken çok önemlidir:
- Seyrek veya yoğun bir tensöre op uygulamak her zaman aynı sonucu vermelidir.
- Düzensiz veya seyrek bir tensöre op uygulamak farklı sonuçlar verebilir.
Açıklayıcı bir örnek olarak, concat , stack ve tile gibi dizi işlemlerinin düzensiz ve seyrek tensörler için nasıl tanımlandığını düşünün. Birleştiren düzensiz tensörler, birleşik uzunluk ile tek bir satır oluşturmak için her satırı birleştirir:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Bununla birlikte, seyrek tensörleri bitiştirmek, aşağıdaki örnekte gösterildiği gibi, karşılık gelen yoğun tensörleri bitiştirmeye eşdeğerdir (burada Ø eksik değerleri gösterir):
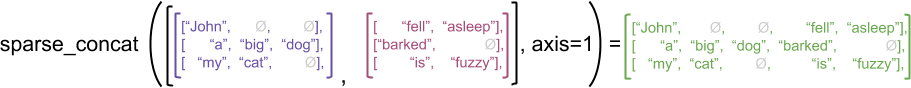
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Bu ayrımın neden önemli olduğuna dair başka bir örnek için, tf.reduce_mean gibi bir işlem için "her satırın ortalama değeri" tanımını düşünün. Düzensiz bir tensör için, bir satırın ortalama değeri, satırın genişliğine bölünen satır değerlerinin toplamıdır. Ancak, bir seyrek tensör için, bir sıranın ortalama değeri, sıranın değerlerinin, seyrek tensörün toplam genişliğine (en uzun satırın genişliğinden daha büyük veya ona eşittir) bölünmesiyle elde edilir.
TensorFlow API'leri
Keras
tf.keras , derin öğrenme modelleri oluşturmak ve eğitmek için TensorFlow'un üst düzey API'sidir. Düzensiz tensörler, tf.keras.Input veya tf.keras.layers.InputLayer üzerinde ragged=True ayarlanarak Keras modeline girdi olarak geçirilebilir. Düzensiz tensörler de Keras katmanları arasında geçirilebilir ve Keras modelleri tarafından döndürülebilir. Aşağıdaki örnek, düzensiz tensörler kullanılarak eğitilmiş bir oyuncak LSTM modelini göstermektedir.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Örnek
tf.Example , TensorFlow verileri için standart bir protobuf kodlamasıdır. tf.Example s ile kodlanmış veriler genellikle değişken uzunluklu özellikler içerir. Örneğin, aşağıdaki kod, farklı özellik uzunluklarına sahip dört tf.Example mesajdan oluşan bir toplu işi tanımlar:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Serileştirilmiş dizelerin bir tensörünü ve bir özellik belirtim sözlüğünü alan ve tensörlere bir sözlük eşleme özelliği adları döndüren tf.io.parse_example kullanarak bu kodlanmış verileri ayrıştırabilirsiniz. Değişken uzunluklu özellikleri düzensiz tensörlere okumak için, özellik belirtimi sözlüğünde tf.io.RaggedFeature kullanmanız yeterlidir:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature , birden çok düzensiz boyuta sahip özellikleri okumak için de kullanılabilir. Ayrıntılar için API belgelerine bakın.
veri kümeleri
tf.data , basit, yeniden kullanılabilir parçalardan karmaşık girdi ardışık düzenleri oluşturmanıza olanak sağlayan bir API'dir. Temel veri yapısı, her öğenin bir veya daha fazla bileşenden oluştuğu bir dizi öğeyi temsil eden tf.data.Dataset .
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Düzensiz tensörlerle Veri Kümeleri Oluşturma
Veri kümeleri, Dataset.from_tensor_slices gibi tf.Tensor s veya NumPy array oluşturmak için kullanılan yöntemlerle aynı yöntemlerle düzensiz tensörlerden oluşturulabilir:
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Düzensiz tensörlerle Veri Kümelerini gruplama ve gruplamadan çıkarma
Düzensiz tensörlü veri kümeleri, Dataset.batch yöntemi kullanılarak toplu işlenebilir ( n ardışık öğeyi tek bir öğede birleştirir).
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Tersine, toplu bir veri kümesi, Dataset.unbatch kullanılarak düz bir veri kümesine dönüştürülebilir.
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Değişken uzunluklu düzensiz tensörlerle Veri Kümelerini Toplu İşleme
Düzensiz tensörler içeren bir Veri Kümeniz varsa ve tensör uzunlukları öğelere göre değişiklik gösteriyorsa, dense_to_ragged_batch dönüşümünü uygulayarak bu düzensiz tensörleri düzensiz tensörlere gruplayabilirsiniz:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Düzensiz tensörlerle Veri Kümelerini Dönüştürme
Dataset.map kullanarak Veri Kümelerinde düzensiz tensörler de oluşturabilir veya dönüştürebilirsiniz:
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.fonksiyonu
tf.function , TensorFlow kodunuzun performansını önemli ölçüde artırabilen Python işlevleri için TensorFlow grafiklerini önceden hesaplayan bir dekoratördür. Düzensiz tensörler, @tf.function -decorated fonksiyonları ile şeffaf bir şekilde kullanılabilir. Örneğin, aşağıdaki işlev hem düzensiz hem de düzensiz tensörlerle çalışır:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
input_signature için tf.function açıkça belirtmek istiyorsanız, bunu tf.RaggedTensorSpec kullanarak yapabilirsiniz.
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
somut fonksiyonlar
Somut işlevler , tf.function tarafından oluşturulan tek tek izlenen grafikleri kapsar. Düzensiz tensörler, somut işlevlerle şeffaf bir şekilde kullanılabilir.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Kaydedilen Modeller
SavedModel , hem ağırlıkları hem de hesaplamayı içeren serileştirilmiş bir TensorFlow programıdır. Bir Keras modelinden veya özel bir modelden oluşturulabilir. Her iki durumda da, düzensiz tensörler, SavedModel tarafından tanımlanan işlevler ve yöntemlerle şeffaf bir şekilde kullanılabilir.
Örnek: bir Keras modelini kaydetme
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Örnek: özel bir modeli kaydetme
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Aşırı yüklenmiş operatörler
RaggedTensor sınıfı, standart Python aritmetiği ve karşılaştırma operatörlerini aşırı yükleyerek temel eleman bazında matematiği gerçekleştirmeyi kolaylaştırır:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Aşırı yüklenmiş operatörler eleman bazında hesaplamalar yaptıklarından, tüm ikili işlemlerin girdileri aynı şekle sahip olmalı veya aynı şekle yayınlanabilir olmalıdır. En basit yayın durumunda, tek bir skaler, düzensiz bir tensördeki her bir değerle eleman bazında birleştirilir:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Daha gelişmiş vakaların tartışması için Yayıncılık bölümüne bakın.
Düzensiz tensörler, normal Tensor ile aynı operatör setini aşırı yükler: tekli operatörler - , ~ ve abs() ; ve ikili operatörler + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > , ve >= .
indeksleme
Düzensiz tensörler, çok boyutlu indeksleme ve dilimleme dahil olmak üzere Python tarzı indekslemeyi destekler. Aşağıdaki örnekler, 2B ve 3B düzensiz tensör ile düzensiz tensör indekslemeyi göstermektedir.
Dizin oluşturma örnekleri: 2B düzensiz tensör
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Dizin oluşturma örnekleri: 3B düzensiz tensör
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor s, çok boyutlu indekslemeyi ve tek bir kısıtlama ile dilimlemeyi destekler: düzensiz bir boyuta indekslemeye izin verilmez. Bu durum sorunludur çünkü belirtilen değer bazı satırlarda varken bazılarında olmayabilir. Bu gibi durumlarda, (1) bir IndexError ; (2) varsayılan bir değer kullanın; veya (3) bu değeri atlayın ve başladığınızdan daha az satıra sahip bir tensör döndürün. Python'un yol gösterici ilkelerini takiben ("Belirsizlik karşısında, tahmin etme cazibesini reddedin"), bu işleme şu anda izin verilmemektedir.
Tensör tipi dönüştürme
RaggedTensor sınıfı, RaggedTensor s ve tf.Tensor s veya tf.SparseTensors arasında dönüştürme yapmak için kullanılabilecek yöntemleri tanımlar:
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Düzensiz tensörlerin değerlendirilmesi
Düzensiz bir tensördeki değerlere erişmek için şunları yapabilirsiniz:
- Düzensiz tensörü iç içe Python listesine dönüştürmek için
tf.RaggedTensor.to_listkullanın. - Düzensiz tensörü değerleri iç içe NumPy dizileri olan bir NumPy dizisine dönüştürmek için
tf.RaggedTensor.numpykullanın. -
tf.RaggedTensor.valuesvetf.RaggedTensor.row_splitsözelliklerini veyatf.RaggedTensor.row_lengthsvetf.RaggedTensor.value_rowidsgibi satır bölümleme yöntemlerini kullanarak düzensiz tensörü bileşenlerine ayırın. - Düzensiz tensörden değerler seçmek için Python indekslemeyi kullanın.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
yayın
Yayıncılık, farklı şekillerdeki tensörlerin elementsel işlemler için uyumlu şekillere sahip olma sürecidir. Yayıncılık hakkında daha fazla bilgi için bkz.
İki x ve y girişini uyumlu şekillere sahip olacak şekilde yayınlamak için temel adımlar şunlardır:
xveyaynı sayıda boyuta sahip değilse, o zaman elde edene kadar dış boyutları (1 boyutuyla) ekleyin.xveyfarklı boyutlara sahip olduğu her boyut için:
-
xveyay,dboyutunda1boyutuna sahipse, diğer girdinin boyutuyla eşleşmesi için değerlerinidboyutu boyunca tekrarlayın. - Aksi takdirde, bir istisna oluşturun (
xveyyayın uyumlu değildir).
Tek tip boyutta bir tensörün boyutunun tek bir sayı olduğu durumlarda (o boyuttaki dilimlerin boyutu); ve düzensiz boyuttaki bir tensörün boyutu, dilim uzunluklarının bir listesidir (o boyuttaki tüm dilimler için).
yayın örnekleri
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Yayın yapmayan bazı şekil örnekleri şunlardır:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
RaggedTensor kodlaması
Düzensiz tensörler, RaggedTensor sınıfı kullanılarak kodlanır. Dahili olarak, her RaggedTensor şunlardan oluşur:
- Değişken uzunluktaki satırları düzleştirilmiş bir listede birleştiren bir
valuestensörü. - Bu düzleştirilmiş değerlerin satırlara nasıl bölündüğünü gösteren bir
row_partition.
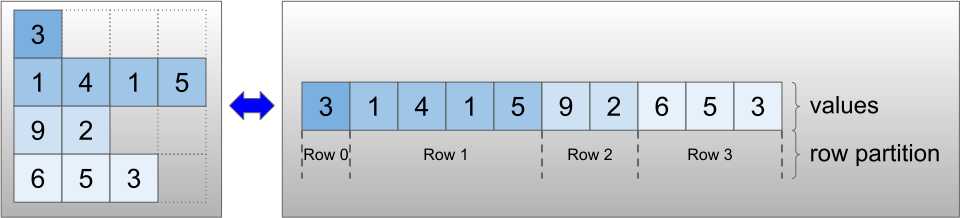
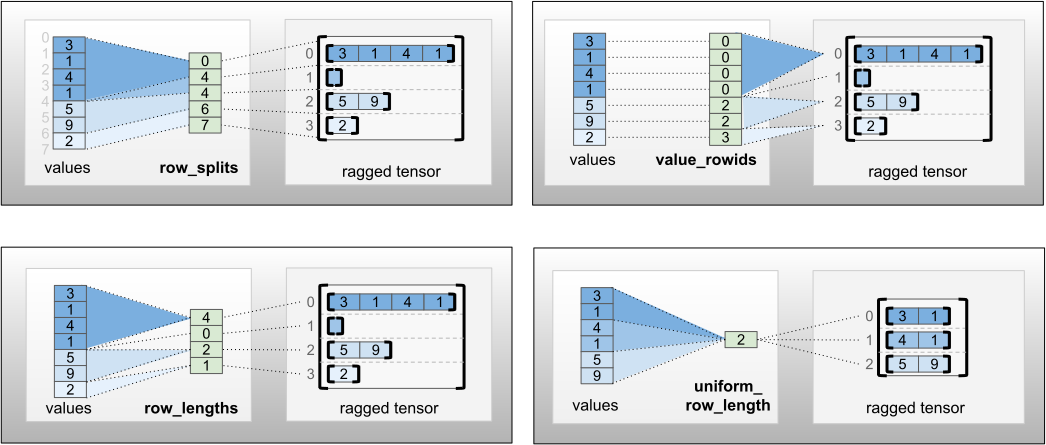
row_partition dört farklı kodlama kullanılarak saklanabilir:
-
row_splits, satırlar arasındaki bölünme noktalarını belirten bir tamsayı vektörüdür. -
value_rowids, her değer için satır indeksini belirten bir tamsayı vektörüdür. -
row_lengths, her satırın uzunluğunu belirten bir tamsayı vektörüdür. -
uniform_row_length, tüm satırlar için tek bir uzunluk belirten bir tam sayı skalerdir.
Value_rowids içeren boş sondaki satırları veya value_rowids ile boş satırları hesaba katmak için row_partition kodlamasına bir tamsayı skaler nrows da dahil uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Satır bölümleri için hangi kodlamanın kullanılacağı seçimi, bazı bağlamlarda verimliliği artırmak için düzensiz tensörler tarafından dahili olarak yönetilir. Özellikle, farklı satır bölümleme şemalarının bazı avantaj ve dezavantajları şunlardır:
- Verimli indeksleme :
row_splitskodlaması, sabit zamanlı indekslemeyi ve düzensiz tensörlere dilimlemeyi mümkün kılar. - Efficient concatenation :
row_lengthskodlaması, düzensiz tensörleri birleştirirken daha verimlidir, çünkü iki tensör bir araya getirildiğinde satır uzunlukları değişmez. - Küçük kodlama boyutu : Tansörün boyutu yalnızca toplam değer sayısına bağlı olduğundan, çok sayıda boş satıra sahip düzensiz tensörler depolanırken
value_rowidskodlaması daha verimlidir. Öte yandan,row_splitsverow_lengthskodlamaları, her satır için yalnızca bir skaler değer gerektirdiğinden, daha uzun satırlara sahip düzensiz tensörleri depolarken daha verimlidir. - Uyumluluk :
value_rowidsşeması,tf.segment_sumgibi işlemler tarafından kullanılan segmentasyon biçimiyle eşleşir.row_limitsşeması,tf.sequence_maskgibi işlemler tarafından kullanılan formatla eşleşir. - Tek biçimli boyutlar : Aşağıda tartışıldığı gibi, tek biçimli boyutlara sahip düzensiz tensörleri kodlamak için
uniform_row_lengthkodlaması kullanılır.
Çoklu düzensiz boyutlar
Birden çok düzensiz boyuta sahip düzensiz bir tensör, values tensörü için iç içe bir RaggedTensor kullanılarak kodlanır. Her yuvalanmış RaggedTensor , tek bir düzensiz boyut ekler.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
tf.RaggedTensor.from_nested_row_splits fabrika işlevi, row_splits tensörlerinin bir listesini sağlayarak doğrudan birden çok düzensiz boyuta sahip bir RaggedTensor oluşturmak için kullanılabilir:
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Düzensiz sıra ve düz değerler
Düzensiz bir tensörün düzensiz sıralaması , temel alınan tensör values bölümlenme sayısıdır (yani, RaggedTensor nesnelerinin yuvalama derinliği). En içteki tensör values , onun flat_values olarak bilinir. Aşağıdaki örnekte, conversations ragged_rank=3 değerine sahiptir ve flat_values değeri 24 dizeye sahip bir 1D Tensor :
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Tek tip iç boyutlar
Düzgün iç boyutlara sahip düzensiz tensörler, düz değerler (yani en içteki values ) için çok boyutlu bir tf.Tensor kullanılarak kodlanır.
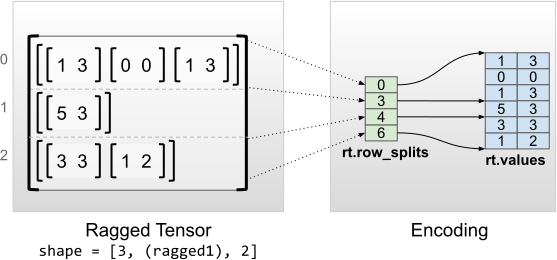
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Tek tip iç olmayan boyutlar
Düzgün iç olmayan boyutlara sahip düzensiz tensörler, satırları uniform_row_length ile bölümleyerek kodlanır.
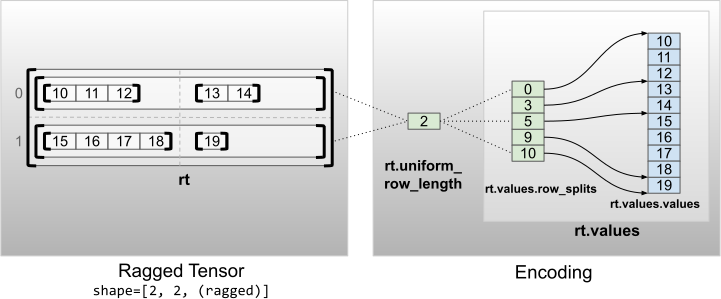
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2