
| | |  Voir la source sur GitHub Voir la source sur GitHub |
Documentation API : tf.RaggedTensor tf.ragged
Installer
import math
import tensorflow as tf
Aperçu
Vos données se présentent sous de nombreuses formes ; vos tenseurs devraient aussi. Les tenseurs irréguliers sont l'équivalent TensorFlow des listes imbriquées de longueur variable. Ils facilitent le stockage et le traitement des données avec des formes non uniformes, notamment :
- Fonctionnalités de durée variable, telles que le jeu d'acteurs dans un film.
- Lots d'entrées séquentielles de longueur variable, telles que des phrases ou des clips vidéo.
- Entrées hiérarchiques, telles que des documents texte subdivisés en sections, paragraphes, phrases et mots.
- Champs individuels dans les entrées structurées, telles que les tampons de protocole.
Ce que vous pouvez faire avec un tenseur en lambeaux
Les tenseurs irréguliers sont pris en charge par plus d'une centaine d'opérations TensorFlow, y compris les opérations mathématiques (telles que tf.add et tf.reduce_mean ), les opérations de tableau (telles que tf.concat et tf.tile ), les opérations de manipulation de chaînes (telles que tf.substr ), les opérations de flux de contrôle (telles que tf.while_loop et tf.map_fn ), et bien d'autres :
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Il existe également un certain nombre de méthodes et d'opérations spécifiques aux tenseurs irréguliers, notamment les méthodes d'usine, les méthodes de conversion et les opérations de mappage de valeurs. Pour obtenir une liste des opérations prises en charge, consultez la documentation du package tf.ragged .
Les tenseurs irréguliers sont pris en charge par de nombreuses API TensorFlow, notamment Keras , Datasets , tf.function , SavedModels et tf.Example . Pour plus d'informations, consultez la section sur les API TensorFlow ci-dessous.
Comme avec les tenseurs normaux, vous pouvez utiliser l'indexation de style Python pour accéder à des tranches spécifiques d'un tenseur irrégulier. Pour plus d'informations, reportez-vous à la section sur l' indexation ci-dessous.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Et tout comme les tenseurs normaux, vous pouvez utiliser les opérateurs arithmétiques et de comparaison Python pour effectuer des opérations élément par élément. Pour plus d'informations, consultez la section sur les opérateurs surchargés ci-dessous.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Si vous devez effectuer une transformation élément par élément des valeurs d'un RaggedTensor , vous pouvez utiliser tf.ragged.map_flat_values , qui prend une fonction plus un ou plusieurs arguments, et applique la fonction pour transformer les valeurs du RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Les tenseurs irréguliers peuvent être convertis en list Python imbriquées et en array NumPy :
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Construire un tenseur déchiqueté
Le moyen le plus simple de construire un tenseur irrégulier consiste à utiliser tf.ragged.constant , qui construit le RaggedTensor correspondant à une list Python imbriquée donnée ou à un array NumPy :
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Les tenseurs irréguliers peuvent également être construits en associant des tenseurs de valeurs plates à des tenseurs de partitionnement de lignes indiquant comment ces valeurs doivent être divisées en lignes, en utilisant des méthodes de classe d'usine telles que tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths et tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Si vous savez à quelle ligne appartient chaque valeur, vous pouvez créer un RaggedTensor à l'aide d'un tenseur de partitionnement de lignes value_rowids :
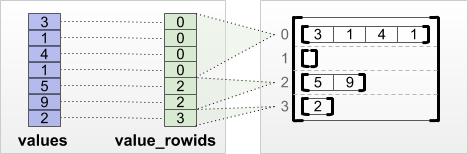
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Si vous connaissez la longueur de chaque ligne, vous pouvez utiliser un tenseur de partitionnement de lignes row_lengths :
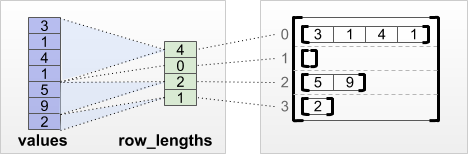
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Si vous connaissez l'index où chaque ligne commence et se termine, vous pouvez utiliser un tenseur de partitionnement de ligne row_splits :
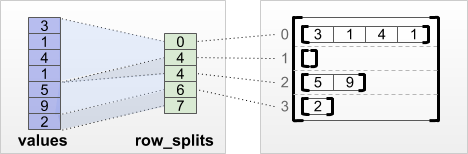
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Voir la documentation de la classe tf.RaggedTensor pour une liste complète des méthodes de fabrique.
Ce que vous pouvez stocker dans un tenseur en lambeaux
Comme avec les Tensor s normaux, les valeurs d'un RaggedTensor doivent toutes avoir le même type ; et les valeurs doivent toutes être à la même profondeur d'imbrication (le rang du tenseur) :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Exemple de cas d'utilisation
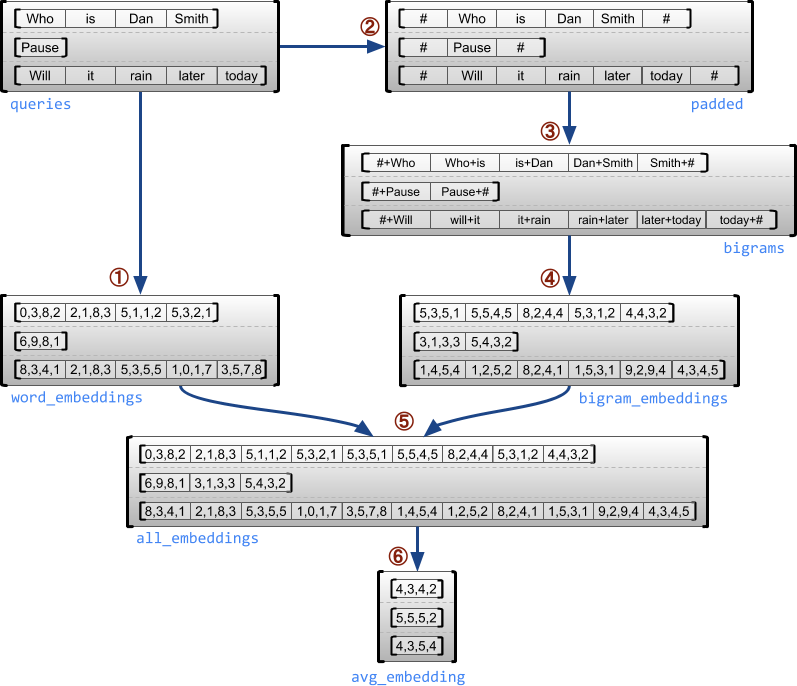
L'exemple suivant montre comment RaggedTensor s peut être utilisé pour construire et combiner des représentations vectorielles continues d'unigramme et de bigramme pour un lot de requêtes de longueur variable, en utilisant des marqueurs spéciaux pour le début et la fin de chaque phrase. Pour plus de détails sur les opérations utilisées dans cet exemple, consultez la documentation du package tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Dimensions irrégulières et uniformes
Une dimension irrégulière est une dimension dont les tranches peuvent avoir des longueurs différentes. Par exemple, la dimension intérieure (colonne) de rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] est irrégulière, car les tranches de colonne ( rt[0, :] , ..., rt[4, :] ) ont des longueurs différentes. Les dimensions dont les tranches ont toutes la même longueur sont appelées dimensions uniformes .
La dimension la plus externe d'un tenseur déchiqueté est toujours uniforme, car il se compose d'une seule tranche (et, par conséquent, il n'y a aucune possibilité de longueurs de tranche différentes). Les dimensions restantes peuvent être irrégulières ou uniformes. Par exemple, vous pouvez stocker les incorporations de mots pour chaque mot dans un lot de phrases à l'aide d'un tenseur irrégulier avec la forme [num_sentences, (num_words), embedding_size] , où les parenthèses autour de (num_words) indiquent que la dimension est irrégulière.
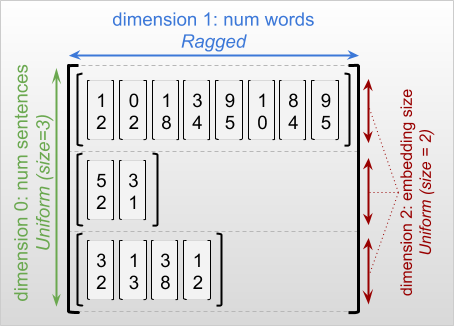
Les tenseurs irréguliers peuvent avoir plusieurs dimensions irrégulières. Par exemple, vous pouvez stocker un lot de documents texte structuré à l'aide d'un tenseur de forme [num_documents, (num_paragraphs), (num_sentences), (num_words)] (où encore des parenthèses sont utilisées pour indiquer des dimensions irrégulières).
Comme avec tf.Tensor , le rang d'un tenseur irrégulier est son nombre total de dimensions (y compris les dimensions irrégulières et uniformes). Un tenseur potentiellement irrégulier est une valeur qui peut être soit un tf.Tensor soit un tf.RaggedTensor .
Lors de la description de la forme d'un RaggedTensor, les dimensions irrégulières sont conventionnellement indiquées en les mettant entre parenthèses. Par exemple, comme vous l'avez vu ci-dessus, la forme d'un RaggedTensor 3D qui stocke les incorporations de mots pour chaque mot dans un lot de phrases peut être écrite comme [num_sentences, (num_words), embedding_size] .
L'attribut RaggedTensor.shape renvoie un tf.TensorShape pour un tenseur irrégulier où les dimensions irrégulières ont la taille None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
La méthode tf.RaggedTensor.bounding_shape peut être utilisée pour trouver une forme de délimitation serrée pour un RaggedTensor donné :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Ragged vs clairsemé
Un tenseur irrégulier ne doit pas être considéré comme un type de tenseur clairsemé. En particulier, les tenseurs clairsemés sont des encodages efficaces pour tf.Tensor qui modélisent les mêmes données dans un format compact ; mais tensor ragged est une extension de tf.Tensor qui modélise une classe étendue de données. Cette différence est cruciale lors de la définition des opérations :
- L'application d'un op à un tenseur clairsemé ou dense devrait toujours donner le même résultat.
- L'application d'un op à un tenseur irrégulier ou clairsemé peut donner des résultats différents.
À titre d'exemple illustratif, considérons comment les opérations de tableau telles que concat , stack et tile sont définies pour les tenseurs irréguliers par rapport aux tenseurs clairsemés. La concaténation des tenseurs irréguliers joint chaque ligne pour former une seule ligne avec la longueur combinée :

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Cependant, concaténer les tenseurs clairsemés revient à concaténer les tenseurs denses correspondants, comme illustré par l'exemple suivant (où Ø indique les valeurs manquantes) :
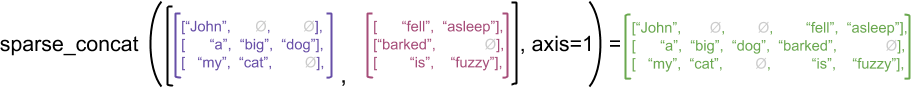
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Pour un autre exemple de l'importance de cette distinction, considérons la définition de "la valeur moyenne de chaque ligne" pour un op tel que tf.reduce_mean . Pour un tenseur irrégulier, la valeur moyenne d'une ligne est la somme des valeurs de la ligne divisée par la largeur de la ligne. Mais pour un tenseur clairsemé, la valeur moyenne d'une ligne est la somme des valeurs de la ligne divisée par la largeur globale du tenseur clairsemé (qui est supérieure ou égale à la largeur de la ligne la plus longue).
API TensorFlow
Keras
tf.keras est l'API de haut niveau de TensorFlow pour la création et la formation de modèles d'apprentissage en profondeur. Les tenseurs irréguliers peuvent être transmis en tant qu'entrées à un modèle Keras en définissant ragged=True sur tf.keras.Input ou tf.keras.layers.InputLayer . Les tenseurs irréguliers peuvent également être passés entre les couches Keras et renvoyés par les modèles Keras. L'exemple suivant montre un modèle LSTM jouet formé à l'aide de tenseurs irréguliers.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Exemple
tf.Example est un encodage protobuf standard pour les données TensorFlow. Les données encodées avec tf.Example s incluent souvent des fonctionnalités de longueur variable. Par exemple, le code suivant définit un lot de quatre messages tf.Example avec différentes longueurs de fonctionnalité :
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Vous pouvez analyser ces données encodées à l'aide de tf.io.parse_example , qui prend un tenseur de chaînes sérialisées et un dictionnaire de spécification de caractéristiques, et renvoie un dictionnaire mappant les noms de caractéristiques aux tenseurs. Pour lire les caractéristiques de longueur variable dans des tenseurs irréguliers, vous utilisez simplement tf.io.RaggedFeature dans le dictionnaire de spécification des caractéristiques :
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature peut également être utilisé pour lire des entités avec plusieurs dimensions irrégulières. Pour plus de détails, reportez-vous à la documentation de l'API .
Jeux de données
tf.data est une API qui vous permet de créer des pipelines d'entrée complexes à partir de pièces simples et réutilisables. Sa structure de données de base est tf.data.Dataset , qui représente une séquence d'éléments, dans laquelle chaque élément est constitué d'un ou plusieurs composants.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Construire des ensembles de données avec des tenseurs irréguliers
Les ensembles de données peuvent être construits à partir de tenseurs irréguliers en utilisant les mêmes méthodes que celles utilisées pour les construire à partir de tf.Tensor s ou NumPy array s, comme Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Regrouper et dégrouper des ensembles de données avec des tenseurs irréguliers
Les ensembles de données avec des tenseurs irréguliers peuvent être regroupés (qui combine n éléments consécutifs en un seul élément) à l'aide de la méthode Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Inversement, un ensemble de données par lots peut être transformé en un ensemble de données plat à l'aide Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Regroupement d'ensembles de données avec des tenseurs non irréguliers de longueur variable
Si vous avez un ensemble de données qui contient des tenseurs non irréguliers et que les longueurs des tenseurs varient d'un élément à l'autre, vous pouvez regrouper ces tenseurs non irréguliers en tenseurs irréguliers en appliquant la transformation dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Transformer des ensembles de données avec des tenseurs irréguliers
Vous pouvez également créer ou transformer des tenseurs irréguliers dans des ensembles de données à l'aide Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.fonction
tf.function est un décorateur qui précalcule les graphiques TensorFlow pour les fonctions Python, ce qui peut considérablement améliorer les performances de votre code TensorFlow. Les tenseurs irréguliers peuvent être utilisés de manière transparente avec les fonctions @tf.function -décorées. Par exemple, la fonction suivante fonctionne avec les tenseurs irréguliers et non irréguliers :
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Si vous souhaitez spécifier explicitement la input_signature pour la tf.function , vous pouvez le faire en utilisant tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Fonctions concrètes
Les fonctions concrètes encapsulent des graphes tracés individuels qui sont construits par tf.function . Les tenseurs irréguliers peuvent être utilisés de manière transparente avec des fonctions concrètes.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Modèles enregistrés
Un SavedModel est un programme TensorFlow sérialisé, comprenant à la fois des pondérations et des calculs. Il peut être construit à partir d'un modèle Keras ou d'un modèle personnalisé. Dans les deux cas, les tenseurs irréguliers peuvent être utilisés de manière transparente avec les fonctions et les méthodes définies par un SavedModel.
Exemple : enregistrement d'un modèle Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Exemple : enregistrement d'un modèle personnalisé
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Opérateurs surchargés
La classe RaggedTensor surcharge les opérateurs d'arithmétique et de comparaison Python standard, ce qui facilite l'exécution de calculs élémentaires élémentaires :
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Étant donné que les opérateurs surchargés effectuent des calculs élément par élément, les entrées de toutes les opérations binaires doivent avoir la même forme ou être diffusables sous la même forme. Dans le cas de diffusion le plus simple, un seul scalaire est combiné élément par élément avec chaque valeur dans un tenseur irrégulier :
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Pour une discussion sur des cas plus avancés, consultez la section sur la diffusion .
Les tenseurs irréguliers surchargent le même ensemble d'opérateurs que les Tensor s normaux : les opérateurs unaires - , ~ et abs() ; et les opérateurs binaires + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > et >= .
Indexage
Les tenseurs irréguliers prennent en charge l'indexation de style Python, y compris l'indexation et le découpage multidimensionnels. Les exemples suivants illustrent l'indexation du tenseur irrégulier avec un tenseur irrégulier 2D et 3D.
Exemples d'indexation : tenseur irrégulier 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Exemples d'indexation : tenseur irrégulier 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor prennent en charge l'indexation et le découpage multidimensionnels avec une restriction : l'indexation dans une dimension irrégulière n'est pas autorisée. Ce cas est problématique car la valeur indiquée peut exister dans certaines lignes mais pas dans d'autres. Dans de tels cas, il n'est pas évident de savoir si vous devez (1) lever une IndexError ; (2) utiliser une valeur par défaut ; ou (3) ignorez cette valeur et renvoyez un tenseur avec moins de lignes que vous avez commencé. Suivant les principes directeurs de Python ("Face à l'ambiguïté, refusez la tentation de deviner"), cette opération est actuellement interdite.
Conversion de type de tenseur
La classe RaggedTensor définit des méthodes qui peuvent être utilisées pour convertir entre RaggedTensor s et tf.Tensor s ou tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Évaluation des tenseurs irréguliers
Pour accéder aux valeurs d'un tenseur irrégulier, vous pouvez :
- Utilisez
tf.RaggedTensor.to_listpour convertir le tenseur irrégulier en une liste Python imbriquée. - Utilisez
tf.RaggedTensor.numpypour convertir le tenseur irrégulier en un tableau NumPy dont les valeurs sont des tableaux NumPy imbriqués. - Décomposez le tenseur irrégulier en ses composants, à l'aide des propriétés
tf.RaggedTensor.valuesettf.RaggedTensor.row_splits, ou des méthodes de partitionnement de lignes telles quetf.RaggedTensor.row_lengthsettf.RaggedTensor.value_rowids. - Utilisez l'indexation Python pour sélectionner des valeurs à partir du tenseur irrégulier.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Diffusion
La diffusion est le processus consistant à faire en sorte que des tenseurs de formes différentes aient des formes compatibles pour les opérations élémentaires. Pour plus d'informations sur la diffusion, reportez-vous à :
Les étapes de base pour diffuser deux entrées x et y pour avoir des formes compatibles sont :
Si
xetyn'ont pas le même nombre de dimensions, ajoutez les dimensions extérieures (avec la taille 1) jusqu'à ce qu'ils le fassent.Pour chaque dimension où
xetyont des tailles différentes :
- Si
xouyont la taille1dans la dimensiond, répétez ses valeurs dans la dimensiondpour correspondre à la taille de l'autre entrée. - Sinon, déclenchez une exception (
xetyne sont pas compatibles avec la diffusion).
Où la taille d'un tenseur dans une dimension uniforme est un nombre unique (la taille des tranches à travers cette dimension); et la taille d'un tenseur dans une dimension irrégulière est une liste de longueurs de tranches (pour toutes les tranches de cette dimension).
Exemples de diffusion
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Voici quelques exemples de formes qui ne diffusent pas :
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Encodage RaggedTensor
Les tenseurs irréguliers sont encodés à l'aide de la classe RaggedTensor . En interne, chaque RaggedTensor se compose de :
- Un tenseur de
values, qui concatène les lignes de longueur variable dans une liste aplatie. - Une
row_partition, qui indique comment ces valeurs aplaties sont divisées en lignes.
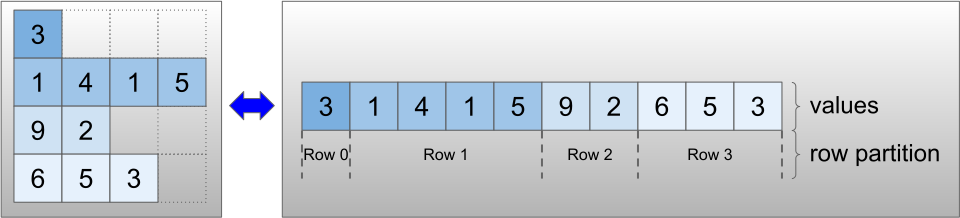
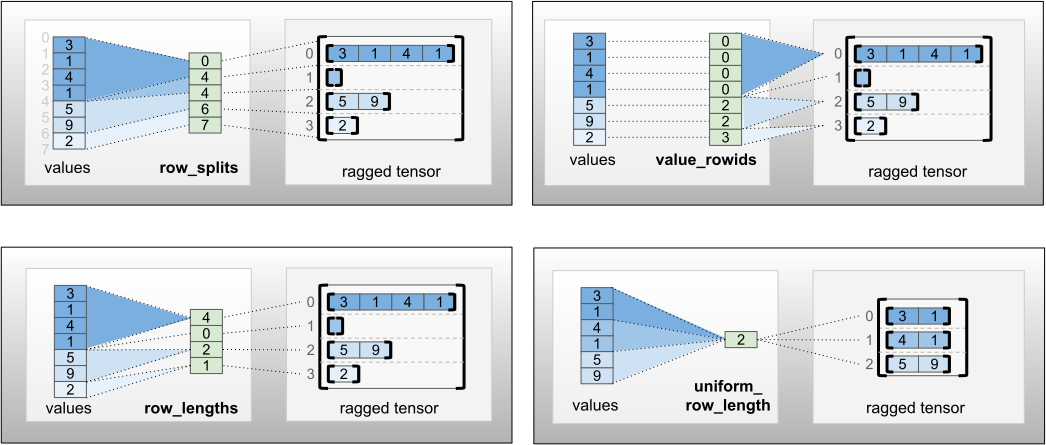
La row_partition peut être stockée à l'aide de quatre encodages différents :
-
row_splitsest un vecteur entier spécifiant les points de partage entre les lignes. -
value_rowidsest un vecteur entier spécifiant l'index de ligne pour chaque valeur. -
row_lengthsest un vecteur entier spécifiant la longueur de chaque ligne. -
uniform_row_lengthest un entier scalaire spécifiant une seule longueur pour toutes les lignes.
Un scalaire entier nrows peut également être inclus dans l'encodage row_partition pour tenir compte des lignes de fin vides avec value_rowids ou des lignes vides avec uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Le choix de l'encodage à utiliser pour les partitions de lignes est géré en interne par des tenseurs irréguliers pour améliorer l'efficacité dans certains contextes. En particulier, certains des avantages et des inconvénients des différents schémas de partitionnement de lignes sont :
- Indexation efficace : L'encodage
row_splitspermet une indexation en temps constant et un découpage en tenseurs irréguliers. - Concaténation efficace : L'encodage
row_lengthsest plus efficace lors de la concaténation de tenseurs irréguliers, car les longueurs de ligne ne changent pas lorsque deux tenseurs sont concaténés ensemble. - Petite taille d'encodage : L'encodage
value_rowidsest plus efficace lors du stockage de tenseurs irréguliers qui ont un grand nombre de lignes vides, puisque la taille du tenseur ne dépend que du nombre total de valeurs. D'autre part, lesrow_splitsetrow_lengthssont plus efficaces lors du stockage de tenseurs irréguliers avec des lignes plus longues, car ils ne nécessitent qu'une seule valeur scalaire pour chaque ligne. - Compatibilité : le schéma
value_rowidscorrespond au format de segmentation utilisé par les opérations, telles quetf.segment_sum. Le schémarow_limitscorrespond au format utilisé par les opérations telles quetf.sequence_mask. - Dimensions uniformes : comme indiqué ci-dessous, le codage
uniform_row_lengthest utilisé pour coder des tenseurs irréguliers avec des dimensions uniformes.
Plusieurs dimensions irrégulières
Un tenseur irrégulier avec plusieurs dimensions irrégulières est codé à l'aide d'un RaggedTensor imbriqué pour le tenseur de values . Chaque RaggedTensor imbriqué ajoute une seule dimension irrégulière.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
La fonction d'usine tf.RaggedTensor.from_nested_row_splits peut être utilisée pour construire un RaggedTensor avec plusieurs dimensions irrégulières directement en fournissant une liste de tenseurs row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Rang irrégulier et valeurs plates
Le rang irrégulier d'un tenseur irrégulier est le nombre de fois que le tenseur de values sous-jacent a été partitionné (c'est-à-dire la profondeur d'imbrication des objets RaggedTensor ). Le tenseur des values les plus internes est connu sous le nom de flat_values . Dans l'exemple suivant, conversations a Tensor =3, et ses flat_values est un tenseur 1D avec 24 chaînes :
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Dimensions intérieures uniformes
Les tenseurs irréguliers avec des dimensions internes uniformes sont codés en utilisant un tf.Tensor multidimensionnel pour les flat_values (c'est-à-dire les values les plus internes).
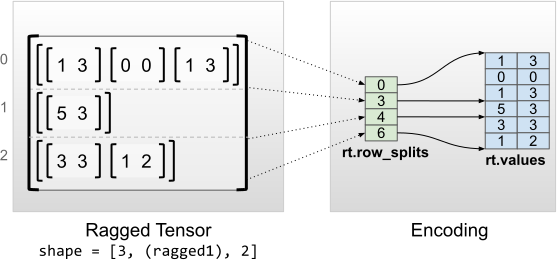
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Dimensions non intérieures uniformes
Les tenseurs irréguliers avec des dimensions non internes uniformes sont encodés en partitionnant les lignes avec uniform_row_length .
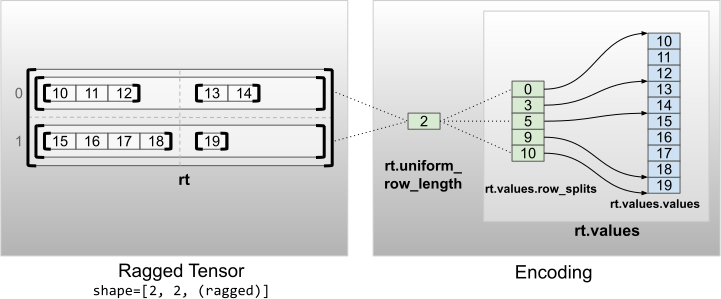
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2