
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub |
เอกสารประกอบ API: tf.RaggedTensor tf.ragged
ติดตั้ง
import math
import tensorflow as tf
ภาพรวม
ข้อมูลของคุณมีหลายรูปแบบ เทนเซอร์ของคุณควรเช่นกัน เมตริกซ์ขาดๆ หายๆ เทียบเท่ากับ TensorFlow ของรายการความยาวผันแปรที่ซ้อนกัน ทำให้ง่ายต่อการจัดเก็บและประมวลผลข้อมูลด้วยรูปทรงที่ไม่สม่ำเสมอ รวมถึง:
- คุณสมบัติความยาวผันแปรได้ เช่น ชุดนักแสดงในภาพยนตร์
- ชุดของอินพุตตามลำดับความยาวผันแปรได้ เช่น ประโยคหรือคลิปวิดีโอ
- การป้อนข้อมูลตามลำดับชั้น เช่น เอกสารข้อความที่แบ่งออกเป็นส่วน ย่อหน้า ประโยค และคำ
- แต่ละฟิลด์ในอินพุตที่มีโครงสร้าง เช่น บัฟเฟอร์โปรโตคอล
คุณสามารถใช้เทนเซอร์มอมแมมทำอะไรได้บ้าง
เทนเซอร์แบบขาดๆ ได้รับการสนับสนุนโดยการดำเนินการ TensorFlow มากกว่าร้อยรายการ รวมถึงการดำเนินการทางคณิตศาสตร์ (เช่น tf.add และ tf.reduce_mean ) การดำเนินการอาร์เรย์ (เช่น tf.concat และ tf.tile ) การจัดการสตริง ops (เช่น tf.substr ) ควบคุมการทำงานของโฟลว์ (เช่น tf.while_loop และ tf.map_fn ) และอื่นๆ อีกมากมาย:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
นอกจากนี้ยังมีวิธีการและการดำเนินการจำนวนหนึ่งที่เจาะจงสำหรับเทนเซอร์ที่ขาดความต่อเนื่อง ซึ่งรวมถึงวิธีการจากโรงงาน วิธีการแปลง และการดำเนินการแมปค่า สำหรับรายการ ops ที่รองรับ โปรดดูเอกสารประกอบของ แพ็คเกจ tf.ragged
TensorFlow APIs จำนวนมากรองรับ TensorFlow รวมถึง Keras , Datasets , tf.function , SavedModels และ tf.Example สำหรับข้อมูลเพิ่มเติม ตรวจสอบส่วน TensorFlow API ด้านล่าง
เช่นเดียวกับเทนเซอร์ปกติ คุณสามารถใช้การจัดทำดัชนีแบบ Python เพื่อเข้าถึงสไลซ์เฉพาะของเทนเซอร์ที่ขาดความต่อเนื่อง สำหรับข้อมูลเพิ่มเติม โปรดดูหัวข้อการ จัดทำดัชนี ด้านล่าง
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
และเช่นเดียวกับเทนเซอร์ทั่วไป คุณสามารถใช้ตัวดำเนินการเลขคณิตและการเปรียบเทียบของ Python เพื่อดำเนินการตามองค์ประกอบได้ สำหรับข้อมูลเพิ่มเติม ตรวจสอบส่วน โอเวอร์โหลดโอเปอเรเตอร์ ด้านล่าง
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
หากคุณต้องการแปลงตามองค์ประกอบเป็นค่าของ RaggedTensor คุณสามารถใช้ tf.ragged.map_flat_values ซึ่งรับฟังก์ชันบวกหนึ่งอาร์กิวเมนต์ และใช้ฟังก์ชันนี้เพื่อแปลงค่าของ RaggedTensor
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Ragged tensor สามารถแปลงเป็น list Python ที่ซ้อนกัน และ NumPy array s:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
การสร้างเทนเซอร์มอมแมม
วิธีที่ง่ายที่สุดในการสร้างเมตริกซ์ที่ขาดตอนคือการใช้ tf.ragged.constant ซึ่งสร้าง RaggedTensor ที่สอดคล้องกับ list Python ที่ซ้อนกันหรือ array NumPy ที่กำหนด:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
เมตริกซ์ที่ขาดหายไปยังสามารถสร้างขึ้นได้โดยการจับคู่เทนเซอร์ ค่า แบนกับเทนเซอร์การ แบ่งแถวเพื่อ ระบุว่าควรแบ่งค่าเหล่านั้นออกเป็นแถวอย่างไร โดยใช้วิธีการคลาสโรงงาน เช่น tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths และ tf.RaggedTensor.from_row_splits
tf.RaggedTensor.from_value_rowids
หากคุณรู้ว่าแต่ละค่าเป็นของแถวใด คุณสามารถสร้าง RaggedTensor โดยใช้เมตริกซ์การแบ่งพาร์ติชันแถว value_rowids :
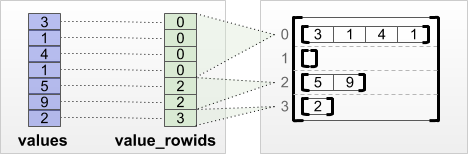
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
หากคุณรู้ว่าแต่ละแถวมีความยาวเท่าใด คุณสามารถใช้ row_lengths row-partitioning tensor:
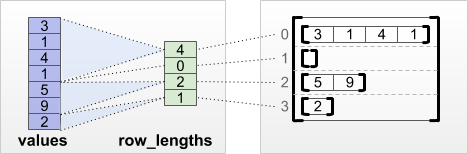
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
หากคุณทราบดัชนีที่แต่ละแถวเริ่มต้นและสิ้นสุด คุณสามารถใช้เมตริกการแบ่งพาร์ติชันแถว row_splits :
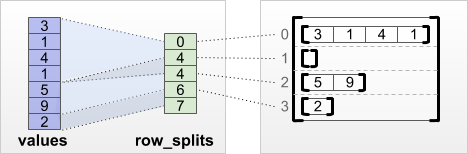
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
ดูเอกสารประกอบคลาส tf.RaggedTensor สำหรับรายการวิธีการจากโรงงานทั้งหมด
สิ่งที่คุณสามารถจัดเก็บในเทนเซอร์มอมแมม
เช่นเดียวกับ Tensor ปกติ ค่าใน RaggedTensor ทั้งหมดต้องมีประเภทเดียวกัน และค่าทั้งหมดต้องอยู่ที่ความลึกของการซ้อนเท่ากัน ( ลำดับ ของเทนเซอร์):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
ตัวอย่างการใช้งาน
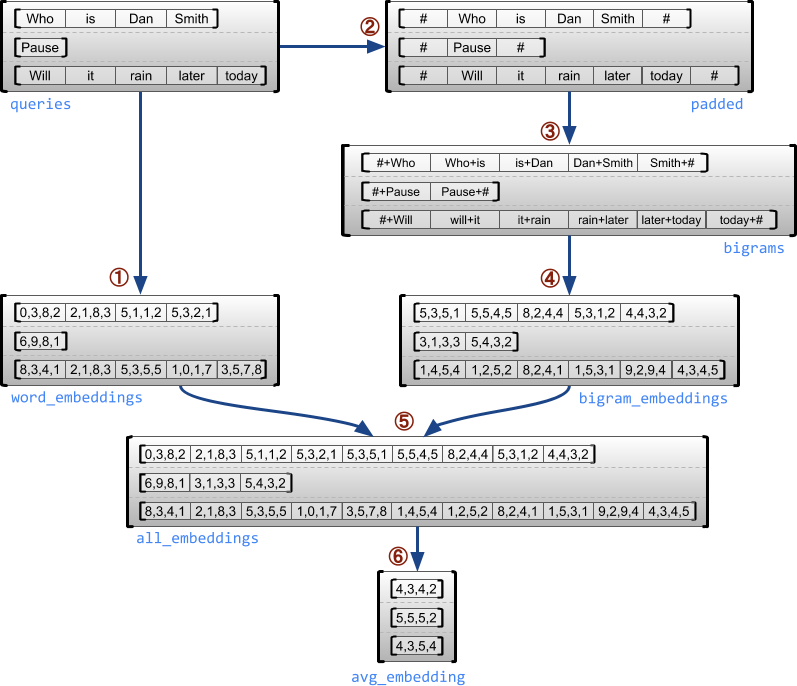
ตัวอย่างต่อไปนี้สาธิตวิธีการ RaggedTensor เพื่อสร้างและรวมการฝัง Unigram และ bigram สำหรับชุดข้อความค้นหาที่มีความยาวผันแปรได้ โดยใช้เครื่องหมายพิเศษสำหรับจุดเริ่มต้นและจุดสิ้นสุดของแต่ละประโยค สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ ops ที่ใช้ในตัวอย่างนี้ ให้ตรวจสอบเอกสารประกอบของแพ็คเกจ tf.ragged
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)ตัวยึดตำแหน่ง39
ขนาดมอมแมมและสม่ำเสมอ
มิติที่ขาด ๆ คือมิติที่สไลซ์อาจมีความยาวต่างกัน ตัวอย่างเช่น มิติข้อมูลภายใน (คอลัมน์) ของ rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] ขาดช่วง เนื่องจากส่วนของคอลัมน์ ( rt[0, :] , ..., rt[4, :] ) มีความยาวต่างกัน ขนาดที่สไลซ์มีความยาวเท่ากันทั้งหมดเรียกว่า มิติสม่ำเสมอ
มิตินอกสุดของเทนเซอร์ขาดๆ หายๆ จะมีความสม่ำเสมอเสมอ เนื่องจากประกอบด้วยชิ้นเดียว (และดังนั้นจึงไม่มีความเป็นไปได้สำหรับความยาวของสไลซ์ที่ต่างกัน) ขนาดที่เหลืออาจเป็นรอยขาดหรือสม่ำเสมอก็ได้ ตัวอย่างเช่น คุณอาจจัดเก็บคำที่ฝังไว้สำหรับแต่ละคำในกลุ่มประโยคโดยใช้เทนเซอร์ที่มีรูปร่าง [num_sentences, (num_words), embedding_size] โดยที่วงเล็บรอบๆ (num_words) ระบุว่ามิติข้อมูลนั้นขาดความต่อเนื่อง
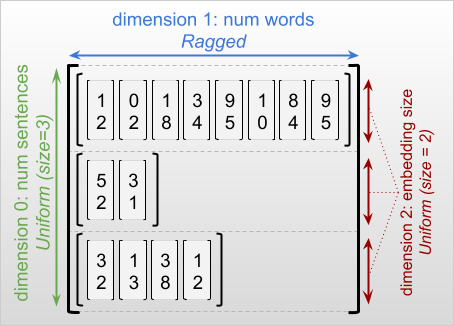
เทนเซอร์มอมแมมอาจมีมิติที่มอมแมมหลายมิติ ตัวอย่างเช่น คุณสามารถจัดเก็บชุดของเอกสารข้อความที่มีโครงสร้างโดยใช้เทนเซอร์ที่มีรูปร่าง [num_documents, (num_paragraphs), (num_sentences), (num_words)] (ซึ่งจะใช้วงเล็บอีกครั้งเพื่อระบุขนาดที่ขาดความชัดเจน)
เช่นเดียวกับ tf.Tensor ลำดับ ของเทนเซอร์มอมแมมคือจำนวนมิติทั้งหมด (รวมทั้งมิติที่ขาดและสม่ำเสมอ) เทนเซอร์ขาด ๆ หายๆ เป็นค่าที่อาจเป็น tf.Tensor หรือ tf.RaggedTensor
เมื่ออธิบายรูปร่างของ RaggedTensor มิติที่ขาดๆ หายๆ จะถูกระบุตามอัตภาพโดยการใส่ไว้ในวงเล็บ ตัวอย่างเช่น ดังที่คุณเห็นด้านบน รูปร่างของ 3D RaggedTensor ที่เก็บการฝังคำสำหรับแต่ละคำในกลุ่มประโยคสามารถเขียนเป็น [num_sentences, (num_words), embedding_size]
แอตทริบิวต์ RaggedTensor.shape ส่งคืน tf.TensorShape สำหรับเมตริกซ์ที่ขาดตอนโดยที่มิติที่ขาดหายไปมีขนาด None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])ตัวยึดตำแหน่ง41
สามารถใช้เมธอด tf.RaggedTensor.bounding_shape เพื่อค้นหารูปร่างที่มีขอบเขตแคบสำหรับ RaggedTensor ที่กำหนด:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)ตัวยึดตำแหน่ง43
มอมแมมกับกระจัดกระจาย
เทนเซอร์ขาดๆ ไม่ ควรถูกมองว่าเป็นเทนเซอร์แบบเบาบาง โดยเฉพาะอย่างยิ่ง sparse tensor เป็นการ เข้ารหัสที่มีประสิทธิภาพสำหรับ tf.Tensor ซึ่งจำลองข้อมูลเดียวกันในรูปแบบกะทัดรัด แต่เทนเซอร์มอมแมมเป็น ส่วนเสริมของ tf.Tensor ซึ่งจำลองคลาสของข้อมูลที่ขยายออกไป ความแตกต่างนี้มีความสำคัญเมื่อกำหนดการดำเนินการ:
- การใช้ op กับเทนเซอร์เบาบางหรือหนาแน่นควรให้ผลลัพธ์เช่นเดียวกัน
- การใช้ op กับเทนเซอร์ขาดๆ หายๆ หรือเบาบางอาจให้ผลลัพธ์ที่ต่างออกไป
เพื่อเป็นตัวอย่าง ให้พิจารณาว่าการดำเนินการอาร์เรย์ เช่น concat , stack และ tile ถูกกำหนดอย่างไรสำหรับเทนเซอร์แบบขาดๆ หายๆ กับ sparse การต่อเทนเซอร์แบบขาดความต่อเนื่องจะเชื่อมแต่ละแถวเข้าด้วยกันเพื่อสร้างแถวเดียวที่มีความยาวรวมกัน:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
อย่างไรก็ตาม การต่อเมตริกซ์แบบกระจายจะเทียบเท่ากับการต่อเมตริกซ์แบบหนาแน่นที่เกี่ยวข้องกัน ดังที่แสดงโดยตัวอย่างต่อไปนี้ (โดยที่ Ø หมายถึงค่าที่หายไป):
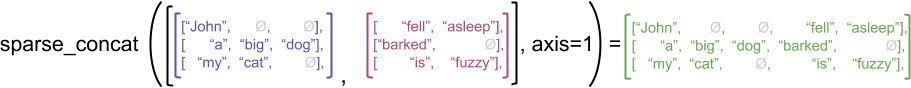
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
สำหรับตัวอย่างอื่นที่ว่าทำไมความแตกต่างนี้จึงสำคัญ ให้พิจารณาคำจำกัดความของ "ค่ากลางของแต่ละแถว" สำหรับ op เช่น tf.reduce_mean สำหรับเทนเซอร์มอมแมม ค่าเฉลี่ยของแถวคือผลรวมของค่าของแถวหารด้วยความกว้างของแถว แต่สำหรับเมตริกซ์แบบกระจาย ค่าเฉลี่ยของแถวคือผลรวมของค่าของแถวหารด้วยความกว้างโดยรวมของเมตริกซ์แบบกระจาย (ซึ่งมากกว่าหรือเท่ากับความกว้างของแถวที่ยาวที่สุด)
TensorFlow APIs
Keras
tf.keras เป็น API ระดับสูงของ TensorFlow สำหรับการสร้างและฝึกอบรมโมเดลการเรียนรู้เชิงลึก เทนเซอร์ขาดๆ อาจถูกส่งผ่านเป็นอินพุตไปยังโมเดล Keras โดยการตั้งค่า ragged=True บน tf.keras.Input หรือ tf.keras.layers.InputLayer นอกจากนี้ เมตริกซ์แบบขาดร่องยังอาจถูกส่งผ่านระหว่างเลเยอร์ Keras และส่งคืนโดยโมเดล Keras ตัวอย่างต่อไปนี้แสดงโมเดลของเล่น LSTM ที่ได้รับการฝึกโดยใช้เทนเซอร์แบบขาดร่อง
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.ตัวอย่าง
tf.Example คือการเข้ารหัส protobuf มาตรฐานสำหรับข้อมูล TensorFlow ข้อมูลที่เข้ารหัสด้วย tf.Example มักจะมีคุณลักษณะที่มีความยาวผันแปรได้ ตัวอย่างเช่น โค้ดต่อไปนี้กำหนดชุดข้อความ tf.Example สี่ข้อความที่มีความยาวคุณลักษณะต่างกัน:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
คุณสามารถแยกวิเคราะห์ข้อมูลที่เข้ารหัสนี้โดยใช้ tf.io.parse_example ซึ่งใช้เมตริกซ์ของสตริงที่เป็นอนุกรมและพจนานุกรมข้อกำหนดคุณลักษณะ และส่งกลับชื่อคุณลักษณะการแมปพจนานุกรมไปยังเมตริกซ์ หากต้องการอ่านคุณสมบัติความยาวผันแปรเป็นเทนเซอร์แบบขาดความ คุณเพียงแค่ใช้ tf.io.RaggedFeature ในพจนานุกรมข้อกำหนดคุณสมบัติ:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>ตัวยึดตำแหน่ง52
tf.io.RaggedFeature ยังใช้อ่านคุณสมบัติที่มีมิติข้อมูลขาดๆ หายๆ หลายรายการได้อีกด้วย สำหรับรายละเอียด โปรดดู เอกสารประกอบ API
ชุดข้อมูล
tf.data เป็น API ที่ช่วยให้คุณสร้างไพพ์ไลน์อินพุตที่ซับซ้อนจากชิ้นส่วนที่เรียบง่ายและนำกลับมาใช้ใหม่ได้ โครงสร้างข้อมูลหลักของมันคือ tf.data.Dataset ซึ่งแสดงถึงลำดับขององค์ประกอบ ซึ่งแต่ละองค์ประกอบประกอบด้วยองค์ประกอบตั้งแต่หนึ่งองค์ประกอบขึ้นไป
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
การสร้างชุดข้อมูลที่มีเทนเซอร์ขาดๆ
สามารถสร้างชุดข้อมูลจากเทนเซอร์ที่ขาดความต่อเนื่องโดยใช้วิธีการเดียวกับที่ใช้สร้างจาก array tf.Tensor หรือ NumPy เช่น Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
ตัวยึดตำแหน่ง55แบทช์และเลิกแบทช์ชุดข้อมูลที่มีเทนเซอร์ขาดๆ หายๆ
ชุดข้อมูลที่มีเทนเซอร์ขาดๆ หายๆ สามารถแบทช์ได้ (ซึ่งรวมองค์ประกอบที่ต่อเนื่องกัน n รายการเป็นองค์ประกอบเดียว) โดยใช้เมธอด Dataset.batch
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
ในทางกลับกัน ชุดข้อมูลแบบแบตช์สามารถแปลงเป็นชุดข้อมูลแบบแฟลตได้โดยใช้ Dataset.unbatch
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
แบทช์ชุดข้อมูลที่มีเทนเซอร์ที่ไม่มีความยาวผันแปรได้
หากคุณมีชุดข้อมูลที่มีเทนเซอร์แบบไม่มีรอยขาด และความยาวเทนเซอร์แตกต่างกันไปตามองค์ประกอบต่างๆ คุณสามารถแบทช์เทนเซอร์ที่ไม่เป็นรอยเป็นเมตริกซ์แบบขาดช่วงได้โดยใช้การแปลงแบบ dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
การแปลงชุดข้อมูลด้วยเทนเซอร์มอมแมม
คุณยังสามารถสร้างหรือแปลงเทนเซอร์ที่ขาดความต่อเนื่องในชุดข้อมูลโดยใช้ Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function เป็นมัณฑนากรที่คำนวณล่วงหน้ากราฟ TensorFlow สำหรับฟังก์ชัน Python ซึ่งสามารถปรับปรุงประสิทธิภาพของโค้ด TensorFlow ของคุณได้อย่างมาก สามารถใช้เมตริกซ์ที่ขาดความโปร่งใสด้วย @tf.function -decorated functions ตัวอย่างเช่น ฟังก์ชันต่อไปนี้ใช้ได้กับเทนเซอร์ทั้งแบบขาดช่วงและไม่มีรอยหยัก:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
หากคุณต้องการระบุ input_signature สำหรับ tf.function อย่างชัดเจน คุณสามารถทำได้โดยใช้ tf.RaggedTensorSpec
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
ฟังก์ชั่นคอนกรีต
ฟังก์ชันที่เป็นรูปธรรมจะ ห่อหุ้มกราฟที่ลากเส้นแต่ละรายการที่สร้างขึ้นโดย tf.function สามารถใช้เทนเซอร์แบบขาดๆ หายๆ ได้อย่างโปร่งใสด้วยฟังก์ชันที่เป็นรูปธรรม
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>ตัวยึดตำแหน่ง72
โมเดลที่บันทึกไว้
SavedModel เป็นโปรแกรม TensorFlow แบบอนุกรม ซึ่งรวมถึงทั้งน้ำหนักและการคำนวณ สามารถสร้างได้จากโมเดล Keras หรือจากโมเดลแบบกำหนดเอง ไม่ว่าในกรณีใด สามารถใช้เทนเซอร์แบบขาดความโปร่งใสด้วยฟังก์ชันและเมธอดที่กำหนดโดย SavedModel
ตัวอย่าง: การบันทึกโมเดล Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
ตัวอย่าง: การบันทึกโมเดลแบบกำหนดเอง
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
โอเปอเรเตอร์โอเวอร์โหลด
คลาส RaggedTensor โอเวอร์โหลดตัวดำเนินการทางคณิตศาสตร์และการเปรียบเทียบของ Python มาตรฐาน ทำให้ง่ายต่อการคำนวณตามองค์ประกอบพื้นฐาน:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
เนื่องจากโอเปอเรเตอร์โอเวอร์โหลดทำการคำนวณตามองค์ประกอบ อินพุตสำหรับการดำเนินการไบนารีทั้งหมดจะต้องมีรูปร่างเหมือนกันหรือสามารถแพร่ภาพเป็นรูปร่างเดียวกันได้ ในกรณีการกระจายเสียงที่ง่ายที่สุด สเกลาร์เดี่ยวจะถูกรวมตามองค์ประกอบกับแต่ละค่าในเทนเซอร์ที่ขาดความต่อเนื่อง:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
สำหรับการอภิปรายเกี่ยวกับกรณีและปัญหาขั้นสูงเพิ่มเติม ให้ดูส่วนเรื่องการ แพร่ภาพกระจายเสียง
เทนเซอร์มอมแมมโอเวอร์โหลดโอเปอเรเตอร์ชุดเดียวกันกับ Tensor ปกติ: ตัวดำเนินการ unary - , ~ และ abs() ; และตัวดำเนินการไบนารี + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > และ >=
การจัดทำดัชนี
เมตริกซ์แบบขาดๆ รองรับการสร้างดัชนีสไตล์ Python รวมถึงการจัดทำดัชนีและการแบ่งส่วนข้อมูลหลายมิติ ตัวอย่างต่อไปนี้สาธิตการจัดทำดัชนีเทนเซอร์แบบขาดร่องกับเมตริกซ์แบบ 2 มิติและ 3 มิติ
ตัวอย่างการจัดทำดัชนี: เทนเซอร์มอมแมม 2 มิติ
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
ตัวอย่างการจัดทำดัชนี: เทนเซอร์มอมแมม 3 มิติ
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor รองรับการทำดัชนีและการแบ่งส่วนแบบหลายมิติด้วยข้อจำกัดเดียว: ไม่อนุญาตให้สร้างดัชนีในมิติที่ขาดความต่อเนื่อง กรณีนี้เป็นปัญหาเนื่องจากค่าที่ระบุอาจมีอยู่ในบางแถว แต่ไม่มีค่าอื่น ในกรณีเช่นนี้ ไม่ชัดเจนว่าคุณควร (1) เพิ่ม IndexError หรือไม่ (2) ใช้ค่าเริ่มต้น; หรือ (3) ข้ามค่านั้นและส่งคืนเทนเซอร์ที่มีแถวน้อยกว่าที่คุณเริ่มต้น ตามหลักการชี้นำของ Python ("ในการเผชิญกับความกำกวม ปฏิเสธที่จะคาดเดา") การดำเนินการนี้ไม่ได้รับอนุญาตในขณะนี้
การแปลงประเภทเทนเซอร์
คลาส RaggedTensor กำหนดวิธีการที่สามารถใช้แปลงระหว่าง RaggedTensor s และ tf.Tensor s หรือ tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
การประเมินเทนเซอร์มอมแมม
ในการเข้าถึงค่าในเทนเซอร์ที่ขาดความต่อเนื่อง คุณสามารถ:
- ใช้
tf.RaggedTensor.to_listเพื่อแปลงเทนเซอร์ที่ขาดช่วงเป็นรายการ Python ที่ซ้อนกัน - ใช้
tf.RaggedTensor.numpyเพื่อแปลงเทนเซอร์แบบขาดๆ หายๆ เป็นอาร์เรย์ NumPy ที่มีค่าเป็นอาร์เรย์ NumPy ที่ซ้อนกัน - แยกส่วนเทนเซอร์ขาดเป็นส่วนประกอบ โดยใช้คุณสมบัติ
tf.RaggedTensor.valuesและtf.RaggedTensor.row_splitsหรือวิธีการแบ่งแถว เช่นtf.RaggedTensor.row_lengthsและtf.RaggedTensor.value_rowids - ใช้การจัดทำดัชนี Python เพื่อเลือกค่าจากเทนเซอร์ที่ขาดความต่อเนื่อง
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
ออกอากาศ
การแพร่ภาพเป็นกระบวนการสร้างเทนเซอร์ที่มีรูปร่างต่างกันให้มีรูปร่างที่เข้ากันได้สำหรับการทำงานตามองค์ประกอบ สำหรับพื้นฐานเพิ่มเติมเกี่ยวกับการออกอากาศ โปรดดูที่:
ขั้นตอนพื้นฐานสำหรับการแพร่สัญญาณอินพุต x และ y สองรายการเพื่อให้มีรูปร่างที่เข้ากันได้คือ:
หาก
xและyไม่มีจำนวนมิติเท่ากัน ให้เพิ่มมิติภายนอก (ด้วยขนาด 1) จนกว่าจะถึงขนาดสำหรับแต่ละมิติที่
xและyมีขนาดต่างกัน:
- หาก
xหรือyมีขนาด1ในมิติdให้ทำซ้ำค่าในมิติdเพื่อให้ตรงกับขนาดของอินพุตอื่น - มิฉะนั้น ให้ยกข้อยกเว้น (
xและyไม่รองรับการออกอากาศ)
โดยที่ขนาดของเทนเซอร์ในมิติที่สม่ำเสมอเป็นตัวเลขเดียว (ขนาดของสไลซ์ข้ามมิตินั้น) และขนาดของเทนเซอร์ในมิติที่ขาดช่วงคือรายการความยาวสไลซ์ (สำหรับสไลซ์ทั้งหมดที่อยู่ในมิตินั้น)
ตัวอย่างการออกอากาศ
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
ต่อไปนี้คือตัวอย่างบางส่วนของรูปร่างที่ไม่ได้ออกอากาศ:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
การเข้ารหัส RaggedTensor
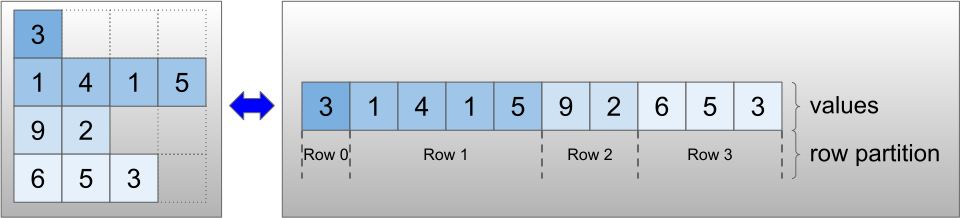
RaggedTensor ถูกเข้ารหัสโดยใช้คลาส RaggedTensor ภายใน RaggedTensor แต่ละอันประกอบด้วย:
-
valuesเทนเซอร์ ซึ่งเชื่อมแถวที่มีความยาวผันแปรได้ในรายการแบบแบน -
row_partitionซึ่งระบุว่าค่าที่แบนเหล่านั้นถูกแบ่งออกเป็นแถวอย่างไร
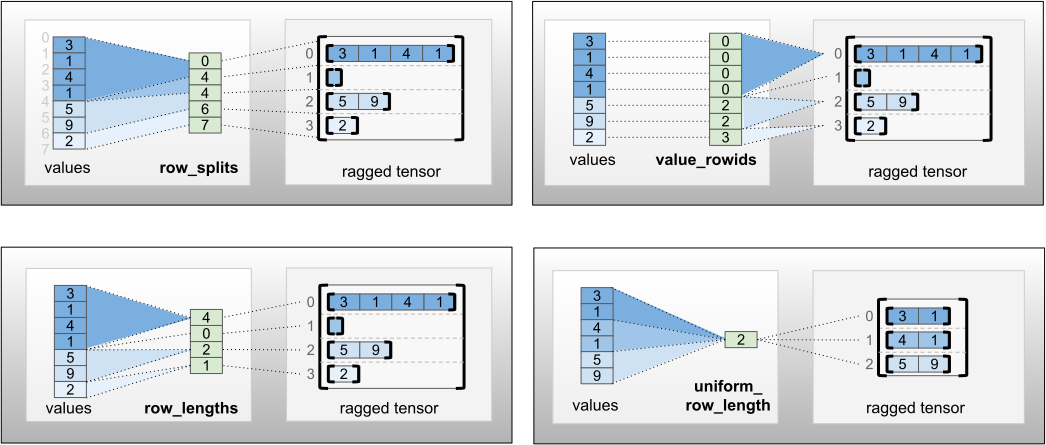
row_partition สามารถจัดเก็บได้โดยใช้การเข้ารหัสที่แตกต่างกันสี่แบบ:
-
row_splitsเป็นเวกเตอร์จำนวนเต็มที่ระบุจุดแยกระหว่างแถว -
value_rowidsเป็นเวกเตอร์จำนวนเต็มที่ระบุดัชนีแถวสำหรับแต่ละค่า -
row_lengthsเป็นเวกเตอร์จำนวนเต็มที่ระบุความยาวของแต่ละแถว -
uniform_row_lengthเป็นสเกลาร์จำนวนเต็มที่ระบุความยาวเดียวสำหรับแถวทั้งหมด
ยังสามารถรวมสเกลาร์จำนวนเต็ม nrows ในการเข้ารหัส row_partition เพื่อพิจารณาแถวต่อท้ายที่ว่างเปล่าด้วย value_rowids หรือแถว uniform_row_length ด้วย
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>ตัวยึดตำแหน่ง127
ตัวเลือกการเข้ารหัสที่จะใช้สำหรับพาร์ติชั่นแถวได้รับการจัดการภายในโดยเทนเซอร์ที่ขาดความต่อเนื่อง เพื่อปรับปรุงประสิทธิภาพในบางบริบท โดยเฉพาะอย่างยิ่ง ข้อดีและข้อเสียบางประการของรูปแบบการแบ่งแถวแบบต่างๆ ได้แก่:
- การทำดัชนีอย่างมีประสิทธิภาพ : การเข้ารหัส
row_splitsช่วยให้สามารถจัดทำดัชนีและแบ่งส่วนข้อมูลออกเป็นเทนเซอร์แบบขาดช่วง - การต่อข้อมูลอย่างมีประสิทธิภาพ : การเข้ารหัส
row_lengthsจะมีประสิทธิภาพมากขึ้นเมื่อทำการต่อเทนเซอร์ที่ขาดความต่อเนื่อง เนื่องจากความยาวของแถวจะไม่เปลี่ยนแปลงเมื่อมีการต่อเมตริกซ์สองตัวเข้าด้วยกัน - ขนาดการเข้ารหัสขนาดเล็ก : การเข้ารหัส
value_rowidsมีประสิทธิภาพมากกว่าเมื่อจัดเก็บเทนเซอร์แบบขาดๆ หายๆ ที่มีแถวว่างจำนวนมาก เนื่องจากขนาดของเทนเซอร์ขึ้นอยู่กับจำนวนค่าทั้งหมดเท่านั้น ในทางกลับกัน การเข้ารหัสrow_splitsและrow_lengthsจะมีประสิทธิภาพมากกว่าเมื่อจัดเก็บเทนเซอร์ที่ขาดช่วงด้วยแถวที่ยาวกว่า เนื่องจากต้องการค่าสเกลาร์เพียงค่าเดียวสำหรับแต่ละแถว - ความเข้ากันได้ : แบบแผน
value_rowidsตรงกับรูปแบบ การแบ่งส่วน ที่ใช้โดยการดำเนินการ เช่นtf.segment_sumโครงร่างrow_limitsตรงกับรูปแบบที่ใช้โดย ops เช่นtf.sequence_mask - ขนาดสม่ำเสมอ : ตามที่กล่าวไว้ด้านล่าง การเข้ารหัส
uniform_row_lengthใช้เพื่อเข้ารหัสเทนเซอร์แบบขาดขอบด้วยขนาดที่สม่ำเสมอ
หลายมิติมอมแมม
เมตริกซ์ขาดมิติที่มีมิติข้อมูลมอมแมมหลายมิติถูกเข้ารหัสโดยใช้ RaggedTensor ที่ซ้อนกันสำหรับ values เทนเซอร์ RaggedTensor ที่ซ้อนกันแต่ละรายการจะเพิ่มมิติที่ขาดตอนเดียว
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
ฟังก์ชันโรงงาน tf.RaggedTensor.from_nested_row_splits อาจใช้เพื่อสร้าง RaggedTensor ที่มีมิติข้อมูลขาดๆ หายๆ หลายรายการได้โดยตรงโดยระบุรายการของ row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>ตัวยึดตำแหน่ง131
อันดับมอมแมมและค่าคงที่
ยศที่ขาดมิติ ของเทนเซอร์คือจำนวนครั้งที่ values พื้นฐานเทนเซอร์ถูกแบ่งออก (กล่าวคือ ความลึกของการซ้อนของออบเจ็กต์ RaggedTensor ) values เทนเซอร์ในสุดเรียกว่า flat_values ในตัวอย่างต่อไปนี้ conversations มี ragged_rank=3 และ flat_values คือ 1D Tensor ที่มี 24 สตริง:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
ขนาดภายในสม่ำเสมอ
เทนเซอร์มอมแมมที่มีมิติภายในสม่ำเสมอจะถูกเข้ารหัสโดยใช้ tf.Tensor แบบหลายมิติสำหรับ flat_values (กล่าวคือ values ที่อยู่ด้านในสุด)
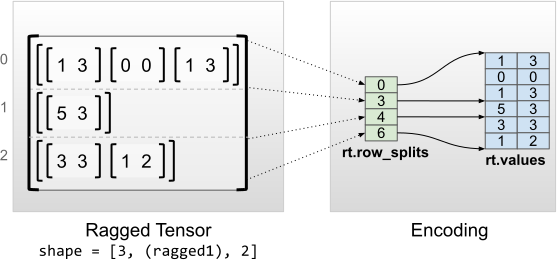
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]ตัวยึดตำแหน่ง139
ขนาดที่ไม่ใช่ภายในสม่ำเสมอ
เทนเซอร์มอมแมมที่มีขนาดไม่เท่ากันภายในถูกเข้ารหัสโดยการแบ่งพาร์ติชั่นแถวด้วย uniform_row_length
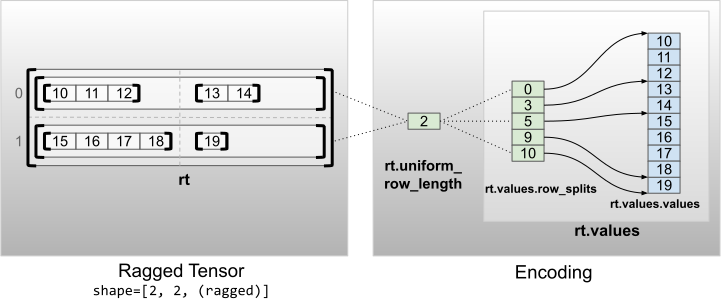
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2