
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub |
Dokumentacja API: tf.RaggedTensor tf.ragged
Ustawiać
import math
import tensorflow as tf
Przegląd
Twoje dane przybierają różne kształty; twoje tensory też powinny. Ragged tensory są odpowiednikiem TensorFlow zagnieżdżonych list o zmiennej długości. Ułatwiają przechowywanie i przetwarzanie danych o niejednorodnych kształtach, w tym:
- Elementy o zmiennej długości, takie jak zestaw aktorów w filmie.
- Partie wejść sekwencyjnych o zmiennej długości, takie jak zdania lub klipy wideo.
- Dane wejściowe hierarchiczne, takie jak dokumenty tekstowe podzielone na sekcje, akapity, zdania i słowa.
- Poszczególne pola w ustrukturyzowanych danych wejściowych, takich jak bufory protokołu.
Co można zrobić z postrzępionym tensorem
Ragged tensory są obsługiwane przez ponad sto operacji TensorFlow, w tym operacje matematyczne (takie jak tf.add i tf.reduce_mean ), operacje tablicowe (takie jak tf.concat i tf.tile ), operacje manipulacji ciągami (takie jak tf.substr ), kontroluj operacje przepływu (takie jak tf.while_loop i tf.map_fn ) i wiele innych:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Istnieje również wiele metod i operacji, które są specyficzne dla tensorów nierównych, w tym metody fabryczne, metody konwersji i operacje mapowania wartości. Lista obsługiwanych operacji znajduje się w dokumentacji pakietu tf.ragged .
Ragged tensory są obsługiwane przez wiele interfejsów API TensorFlow, w tym Keras , Datasets , tf.function , SavedModels i tf.Example . Aby uzyskać więcej informacji, zapoznaj się z sekcją dotyczącą interfejsów API TensorFlow poniżej.
Podobnie jak w przypadku normalnych tensorów, możesz użyć indeksowania w stylu Pythona, aby uzyskać dostęp do określonych fragmentów postrzępionego tensora. Aby uzyskać więcej informacji, zapoznaj się z sekcją dotyczącą indeksowania poniżej.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Podobnie jak w przypadku normalnych tensorów, do wykonywania operacji elementarnych można używać operatorów arytmetycznych i operatorów porównania Pythona. Aby uzyskać więcej informacji, zapoznaj się z sekcją dotyczącą Przeciążonych operatorów poniżej.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Jeśli musisz wykonać transformację elementową do wartości RaggedTensor , możesz użyć tf.ragged.map_flat_values , który przyjmuje funkcję plus jeden lub więcej argumentów i stosuje funkcję do przekształcenia wartości RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Ragged tensory można przekonwertować na zagnieżdżone list Pythona i array NumPy:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Konstruowanie postrzępionego tensora
Najprostszym sposobem skonstruowania nierównego tensora jest użycie tf.ragged.constant , który buduje RaggedTensor odpowiadający danej zagnieżdżonej list Pythona lub array NumPy :
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Nierówne tensory można również konstruować, łącząc w pary tensory wartości płaskich z tensorami partycjonowania wierszy wskazującymi, w jaki sposób te wartości powinny być podzielone na wiersze, przy użyciu fabrycznych metod klas, takich jak tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths i tf.RaggedTensor.from_row_splits
tf.RaggedTensor.from_value_rowids
Jeśli wiesz, do którego wiersza należy każda wartość, możesz zbudować RaggedTensor przy użyciu tensora partycjonowania wierszy value_rowids :
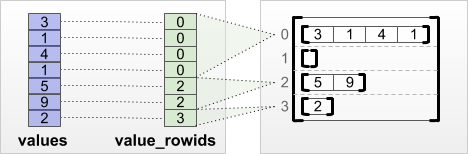
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Jeśli wiesz, jak długi jest każdy wiersz, możesz użyć row_lengths wierszy:
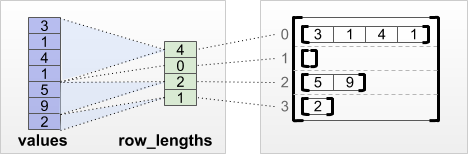
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Jeśli znasz indeks, w którym każdy wiersz zaczyna się i kończy, możesz użyć tensora podziału wierszy row_splits :
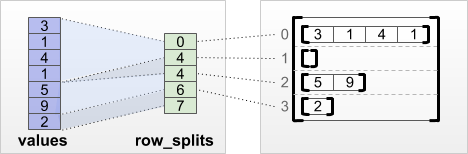
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Zobacz dokumentację klasy tf.RaggedTensor , aby uzyskać pełną listę metod fabrycznych.
Co możesz przechowywać w postrzępionym tensorze
Podobnie jak w przypadku normalnych Tensor , wszystkie wartości w RaggedTensor muszą mieć ten sam typ; a wszystkie wartości muszą mieć tę samą głębokość zagnieżdżenia ( ranga tensora):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Przykładowy przypadek użycia
Poniższy przykład pokazuje, jak RaggedTensor s może służyć do konstruowania i łączenia osadzania unigramu i bigramu dla partii zapytań o zmiennej długości przy użyciu specjalnych znaczników na początku i na końcu każdego zdania. Więcej szczegółów na temat operacji użytych w tym przykładzie można znaleźć w dokumentacji pakietu tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
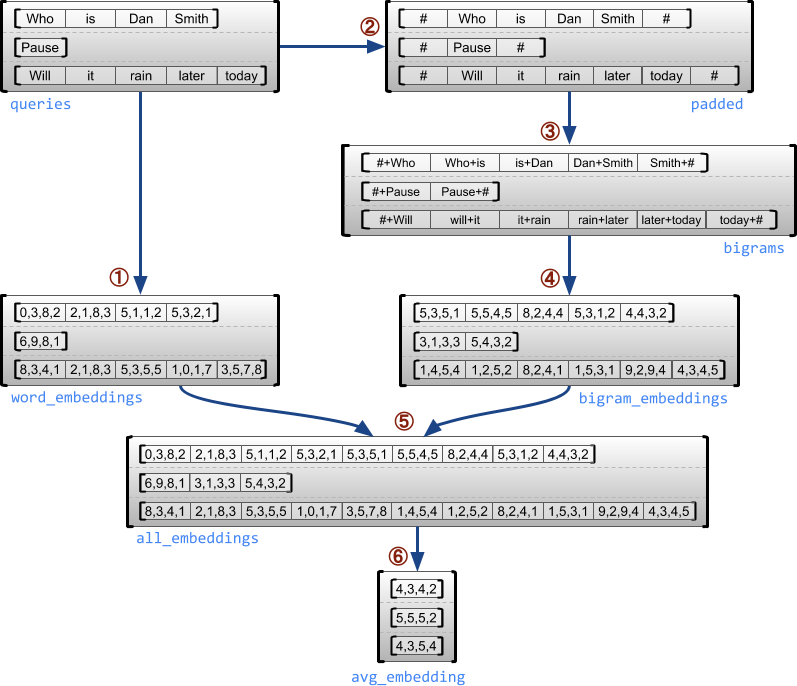
Poszarpane i jednolite wymiary
Wymiar postrzępiony to wymiar, którego plasterki mogą mieć różne długości. Na przykład wymiar wewnętrzny (kolumny) rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] jest nierówny, ponieważ wycinki kolumny ( rt[0, :] , ..., rt[4, :] ) mają różne długości. Wymiary, których wszystkie plastry mają tę samą długość, nazywane są wymiarami jednolitymi .
Zewnętrzny wymiar postrzępionego tensora jest zawsze jednorodny, ponieważ składa się z jednego plastra (a zatem nie ma możliwości różnicowania długości plastra). Pozostałe wymiary mogą być postrzępione lub jednolite. Na przykład, możesz przechowywać osadzenia słów dla każdego słowa w grupie zdań, używając poszarpanego tensora o kształcie [num_sentences, (num_words), embedding_size] , gdzie nawiasy wokół (num_words) wskazują, że wymiar jest nierówny.
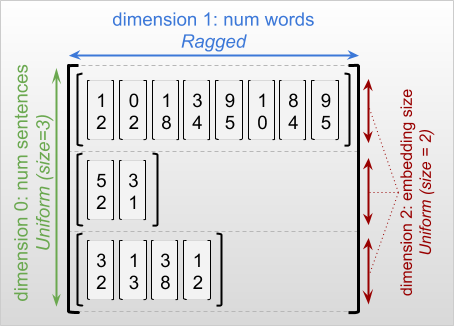
Poszarpane tensory mogą mieć wiele poszarpanych wymiarów. Na przykład możesz przechowywać partię ustrukturyzowanych dokumentów tekstowych, używając tensora o kształcie [num_documents, (num_paragraphs), (num_sentences), (num_words)] (gdzie znowu nawiasy są używane do wskazania nierównych wymiarów).
Podobnie jak w przypadku tf.Tensor , ranga postrzępionego tensora to jego całkowita liczba wymiarów (w tym zarówno wymiary postrzępione, jak i jednolite). Tensor potencjalnie nierówny to wartość, która może być wartością tf.Tensor lub tf.RaggedTensor .
Podczas opisywania kształtu RaggedTensor, poszarpane wymiary są konwencjonalnie wskazywane przez umieszczenie ich w nawiasach. Na przykład, jak widzieliśmy powyżej, kształt 3D RaggedTensor, który przechowuje osadzone słowa dla każdego słowa w grupie zdań, można zapisać jako [num_sentences, (num_words), embedding_size] .
Atrybut RaggedTensor.shape zwraca tf.TensorShape dla poszarpanego tensora, w którym poszarpane wymiary mają rozmiar None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Metoda tf.RaggedTensor.bounding_shape może być użyta do znalezienia kształtu ściśle ograniczającego dla danego RaggedTensor :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Poszarpany vs rzadki
Nierówny tensor nie powinien być traktowany jako rodzaj rzadkiego tensora. W szczególności rzadkie tensory są wydajnymi kodowaniami dla tf.Tensor , które modelują te same dane w kompaktowym formacie; ale nierówny tensor jest rozszerzeniem tf.Tensor , które modeluje rozszerzoną klasę danych. Ta różnica jest kluczowa przy definiowaniu operacji:
- Zastosowanie op do rzadkiego lub gęstego tensora powinno zawsze dawać ten sam rezultat.
- Nałożenie op na poszarpany lub rzadki tensor może dać różne wyniki.
Jako ilustrujący przykład rozważ, jak operacje tablicowe, takie jak concat , stack i tile są definiowane dla tensorów nierównych i rzadkich. Łączenie postrzępionych tensorów łączy każdy rząd, tworząc jeden rząd o łącznej długości:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Jednak łączenie rozrzedzonych tensorów jest równoznaczne z łączeniem odpowiednich gęstych tensorów, co ilustruje poniższy przykład (gdzie Ø wskazuje brakujące wartości):
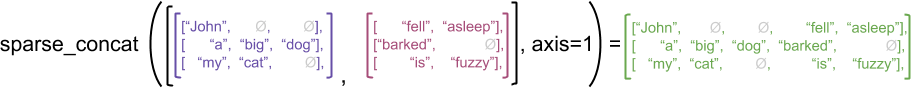
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Jako inny przykład tego, dlaczego to rozróżnienie jest ważne, rozważ definicję „średniej wartości każdego wiersza” dla operacji takiej jak tf.reduce_mean . W przypadku tensora postrzępionego średnia wartość wiersza to suma wartości wiersza podzielona przez szerokość wiersza. Ale dla sparse tensor, średnia wartość dla wiersza jest sumą wartości wiersza podzieloną przez całkowitą szerokość sparse tensor (która jest większa lub równa szerokości najdłuższego wiersza).
Interfejsy API TensorFlow
Keras
tf.keras to wysokopoziomowy interfejs API firmy TensorFlow do tworzenia i trenowania modeli uczenia głębokiego. Ragged tensory mogą być przekazywane jako dane wejściowe do modelu Keras, ustawiając ragged=True na tf.keras.Input lub tf.keras.layers.InputLayer . Poszarpane tensory mogą być również przekazywane między warstwami Keras i zwracane przez modele Keras. Poniższy przykład przedstawia zabawkowy model LSTM, który jest wytrenowany przy użyciu nierównych tensorów.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Przykład
tf.Example to standardowe kodowanie protobuf dla danych TensorFlow. Dane zakodowane za pomocą tf.Example s często zawierają cechy o zmiennej długości. Na przykład poniższy kod definiuje zestaw czterech komunikatów tf.Example o różnych długościach funkcji:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Możesz przeanalizować te zakodowane dane za pomocą tf.io.parse_example , który pobiera tensor zserializowanych ciągów i słownik specyfikacji funkcji i zwraca słownikowe nazwy funkcji mapujących na tensory. Aby wczytać funkcje o zmiennej długości do postrzępionych tensorów, wystarczy użyć tf.io.RaggedFeature w słowniku specyfikacji funkcji:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature może być również używany do odczytywania obiektów o wielu poszarpanych wymiarach. Szczegółowe informacje znajdziesz w dokumentacji API .
Zbiory danych
tf.data to interfejs API, który umożliwia budowanie złożonych potoków wejściowych z prostych elementów wielokrotnego użytku. Jego podstawową strukturą danych jest tf.data.Dataset , która reprezentuje sekwencję elementów, w której każdy element składa się z jednego lub więcej składników.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Budowanie zbiorów danych z poszarpanymi tensorami
Zestawy danych można budować z nierównych tensorów przy użyciu tych samych metod, które są używane do tworzenia ich z array tf.Tensor lub NumPy, takich jak Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Grupowanie i rozpakowywanie zbiorów danych z poszarpanymi tensorami
Zestawy danych z nierównymi tensorami można grupować (co łączy n kolejnych elementów w jeden element) przy użyciu metody Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Z kolei zestaw danych wsadowych można przekształcić w płaski zestaw danych za pomocą Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Grupowanie zbiorów danych z tensorami o zmiennej długości, które nie są postrzępione
Jeśli masz zestaw danych, który zawiera tensory nieobszarpane, a długości tensorów różnią się w zależności od elementów, możesz połączyć te tensory nieobszarpane w tensory nierówne, stosując przekształcenie dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Przekształcanie zbiorów danych za pomocą postrzępionych tensorów
Możesz także tworzyć lub przekształcać postrzępione tensory w zestawach danych za pomocą Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.funkcja
tf.function to dekorator, który wstępnie oblicza wykresy TensorFlow dla funkcji Pythona, co może znacznie poprawić wydajność Twojego kodu TensorFlow. Ragged tensory mogą być używane przezroczyście z @tf.function . Na przykład poniższa funkcja działa zarówno z tensorami postrzępionymi, jak i nierównymi:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Jeśli chcesz jawnie określić input_signature dla funkcji tf.function , możesz to zrobić za pomocą tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Konkretne funkcje
Konkretne funkcje hermetyzują poszczególne grafy śledzone, które są budowane przez tf.function . Poszarpane tensory mogą być używane w przejrzysty sposób z konkretnymi funkcjami.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Zapisane modele
SavedModel to serializowany program TensorFlow, obejmujący zarówno wagi, jak i obliczenia. Może być zbudowany z modelu Keras lub z modelu niestandardowego. W obu przypadkach nierówne tensory mogą być używane w sposób przezroczysty z funkcjami i metodami zdefiniowanymi przez SavedModel.
Przykład: zapisywanie modelu Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Przykład: zapisywanie niestandardowego modelu
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Przeciążeni operatorzy
Klasa RaggedTensor przeciąża standardowe operatory arytmetyczne i porównania Pythona, ułatwiając wykonywanie podstawowej matematyki elementarnej:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Ponieważ przeciążone operatory wykonują obliczenia elementwise, dane wejściowe do wszystkich operacji binarnych muszą mieć ten sam kształt lub mogą być emitowane do tego samego kształtu. W najprostszym przypadku rozgłaszania pojedynczy skalar jest łączony elementarnie z każdą wartością w postrzępionym tensorze:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Aby zapoznać się z bardziej zaawansowanymi sprawami, zapoznaj się z sekcją Nadawanie .
Tensory postrzępione przeciążają ten sam zestaw operatorów, co normalne Tensor : operatory jednoargumentowe - , ~ i abs() ; oraz operatory binarne + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > i >= .
Indeksowanie
Ragged tensory obsługują indeksowanie w stylu Pythona, w tym indeksowanie wielowymiarowe i dzielenie na plasterki. Poniższe przykłady przedstawiają poszarpane indeksowanie tensora za pomocą poszarpanego tensora 2D i 3D.
Przykłady indeksowania: postrzępiony tensor 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Przykłady indeksowania: postrzępiony tensor 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor obsługują indeksowanie wielowymiarowe i wycinanie z jednym ograniczeniem: indeksowanie do nierównego wymiaru jest niedozwolone. Ten przypadek jest problematyczny, ponieważ wskazana wartość może występować w niektórych wierszach, ale nie w innych. W takich przypadkach nie jest oczywiste, czy należy (1) zgłosić IndexError ; (2) użyj wartości domyślnej; lub (3) pomiń tę wartość i zwróć tensor z mniejszą liczbą wierszy niż na początku. Zgodnie z naczelnymi zasadami Pythona („W obliczu niejasności, odrzuć pokusę zgadywania”), operacja ta jest obecnie niedozwolona.
Konwersja typu tensora
Klasa RaggedTensor definiuje metody, których można użyć do konwersji między RaggedTensor s i tf.Tensor s lub tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Ocena poszarpanych tensorów
Aby uzyskać dostęp do wartości w postrzępionym tensorze, możesz:
- Użyj
tf.RaggedTensor.to_list, aby przekonwertować nierówny tensor na zagnieżdżoną listę Pythona. - Użyj
tf.RaggedTensor.numpy, aby przekonwertować nierówny tensor na tablicę NumPy, której wartości są zagnieżdżonymi tablicami NumPy. - Rozłóż nierówny tensor na jego składniki przy użyciu właściwości
tf.RaggedTensor.valuesitf.RaggedTensor.row_splitslub metod dzielenia wierszy, takich jaktf.RaggedTensor.row_lengthsitf.RaggedTensor.value_rowids. - Użyj indeksowania Pythona, aby wybrać wartości z nierównego tensora.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Nadawanie
Nadawanie to proces polegający na tym, że tensory o różnych kształtach mają kompatybilne kształty do operacji elementarnych. Więcej informacji na temat nadawania można znaleźć w:
Podstawowe kroki rozgłaszania dwóch wejść x i y w celu uzyskania zgodnych kształtów to:
Jeśli
xiynie mają tej samej liczby wymiarów, dodaj wymiary zewnętrzne (o rozmiarze 1), aż tak się stanie.Dla każdego wymiaru, gdzie
xiymają różne rozmiary:
- Jeśli
xlubymają rozmiar1w wymiarzed, powtórz jego wartości w wymiarzed, aby dopasować rozmiar innych danych wejściowych. - W przeciwnym razie zgłoś wyjątek (
xiynie są zgodne z rozgłaszaniem).
Gdzie rozmiar tensora w jednolitym wymiarze jest pojedynczą liczbą (wielkość plasterków w tym wymiarze); a rozmiar tensora w poszarpanym wymiarze to lista długości plasterków (dla wszystkich plasterków w tym wymiarze).
Przykłady transmisji
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Oto kilka przykładów kształtów, które nie są transmitowane:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Kodowanie RaggedTensor
Ragged tensory są kodowane przy użyciu klasy RaggedTensor . Wewnętrznie każdy RaggedTensor składa się z:
- Tensor
values, który łączy wiersze o zmiennej długości w spłaszczoną listę. -
row_partition, która wskazuje, jak te spłaszczone wartości są podzielone na wiersze.
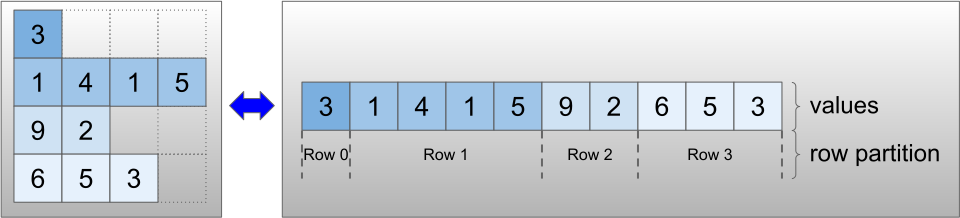
row_partition może być przechowywany przy użyciu czterech różnych kodowań:
-
row_splitsto wektor całkowity określający punkty podziału między wierszami. -
value_rowidsto wektor całkowity określający indeks wiersza dla każdej wartości. -
row_lengthsto wektor całkowity określający długość każdego wiersza. -
uniform_row_lengthto liczba całkowita skalarna określająca pojedynczą długość dla wszystkich wierszy.
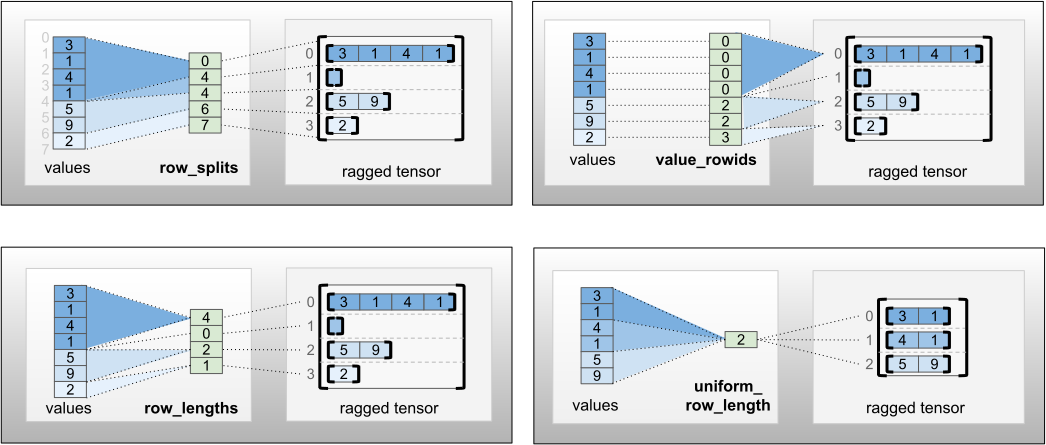
nrows skalarne liczb całkowitych można również uwzględnić w kodowaniu row_partition , aby uwzględnić puste wiersze końcowe z uniform_row_length value_rowids
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Wybór kodowania do użycia dla partycji wierszowych jest zarządzany wewnętrznie przez nierówne tensory w celu poprawy wydajności w niektórych kontekstach. W szczególności niektóre zalety i wady różnych schematów partycjonowania wierszy to:
- Wydajne indeksowanie : kodowanie
row_splitsumożliwia indeksowanie w czasie stałym i cięcie na nierówne tensory. - Wydajna konkatenacja : kodowanie
row_lengthsjest bardziej wydajne podczas łączenia nierównych tensorów, ponieważ długości wierszy nie zmieniają się, gdy dwa tensory są ze sobą łączone. - Mały rozmiar kodowania : kodowanie
value_rowidsjest bardziej wydajne podczas przechowywania nierównych tensorów, które mają dużą liczbę pustych wierszy, ponieważ rozmiar tensora zależy tylko od całkowitej liczby wartości. Z drugiej strony kodowaniarow_splitsirow_lengthssą bardziej wydajne podczas przechowywania nierównych tensorów z dłuższymi wierszami, ponieważ wymagają tylko jednej wartości skalarnej dla każdego wiersza. - Zgodność : schemat
value_rowidsjest zgodny z formatem segmentacji używanym przez operacje, takim jaktf.segment_sum. Schematrow_limitsodpowiada formatowi używanemu przez operacje, takie jaktf.sequence_mask. - Jednolite wymiary : jak omówiono poniżej, kodowanie
uniform_row_lengthsłuży do kodowania nierównych tensorów o jednolitych wymiarach.
Wiele poszarpanych wymiarów
Nierówny tensor z wieloma nierównymi wymiarami jest kodowany przy użyciu zagnieżdżonego RaggedTensor dla tensora values . Każdy zagnieżdżony RaggedTensor dodaje jeden nierówny wymiar.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
Funkcji fabrycznej tf.RaggedTensor.from_nested_row_splits można użyć do bezpośredniego skonstruowania RaggedTensor z wieloma nierównymi wymiarami, dostarczając listę tensorów row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Ragged rank i płaskie wartości
Nierówna pozycja tensora nierównego to liczba podzielonych na partycje tensora values bazowych (tj. głębokość zagnieżdżenia obiektów RaggedTensor ). Tensor values najbardziej wewnętrznych jest znany jako jego flat_values . W poniższym przykładzie conversations mają Tensor =3, a ich flat_values to tensor 1D z 24 ciągami znaków:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Jednolite wymiary wewnętrzne
Nierówne tensory o jednolitych wymiarach wewnętrznych są kodowane przy użyciu wielowymiarowego tf.Tensor dla flat_values (tj. najbardziej wewnętrznych values ).
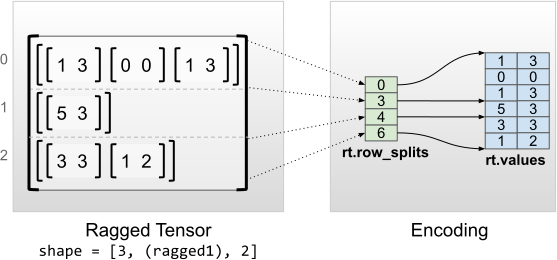
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Jednolite wymiary inne niż wewnętrzne
Nierówne tensory o jednolitych wymiarach innych niż wewnętrzne są kodowane przez partycjonowanie wierszy z uniform_row_length .
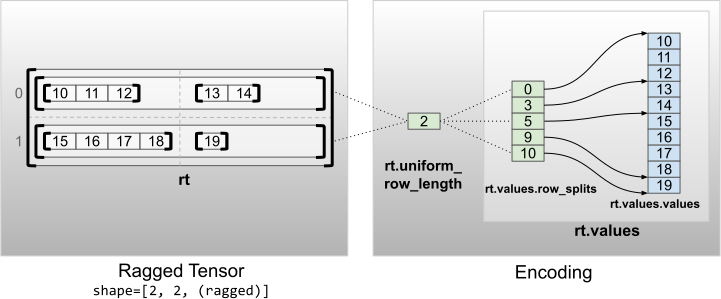
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2