
Ce guide montre comment utiliser les outils disponibles avec TensorFlow Profiler pour suivre les performances de vos modèles TensorFlow. Vous apprendrez à comprendre les performances de votre modèle sur l'hôte (CPU), le périphérique (GPU) ou sur une combinaison de l'hôte et du ou des périphériques.
Le profilage permet de comprendre la consommation de ressources matérielles (temps et mémoire) des différentes opérations (ops) TensorFlow de votre modèle, de résoudre les goulots d'étranglement des performances et, en fin de compte, d'accélérer l'exécution du modèle.
Ce guide vous expliquera comment installer le profileur, les différents outils disponibles, les différents modes de collecte des données de performances par le profileur et quelques bonnes pratiques recommandées pour optimiser les performances du modèle.
Si vous souhaitez profiler les performances de votre modèle sur Cloud TPU, reportez-vous au guide Cloud TPU .
Installez les prérequis du Profiler et du GPU
Installez le plugin Profiler pour TensorBoard avec pip. Notez que le profileur nécessite les dernières versions de TensorFlow et TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Pour profiler sur le GPU, vous devez :
- Répondez aux exigences des pilotes NVIDIA® GPU et du CUDA® Toolkit répertoriées dans la section Configuration logicielle requise pour la prise en charge du GPU TensorFlow .
Assurez-vous que l' interface des outils de profilage NVIDIA® CUDA® (CUPTI) existe sur le chemin :
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Si vous n'avez pas CUPTI sur le chemin, ajoutez son répertoire d'installation à la variable d'environnement $LD_LIBRARY_PATH en exécutant :
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Ensuite, exécutez à nouveau la commande ldconfig ci-dessus pour vérifier que la bibliothèque CUPTI est trouvée.
Résoudre les problèmes de privilèges
Lorsque vous exécutez le profilage avec CUDA® Toolkit dans un environnement Docker ou sous Linux, vous pouvez rencontrer des problèmes liés à des privilèges CUPTI insuffisants ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Accédez aux documents NVIDIA Developer Docs pour en savoir plus sur la façon dont vous pouvez résoudre ces problèmes sous Linux.
Pour résoudre les problèmes de privilèges CUPTI dans un environnement Docker, exécutez
docker run option '--privileged=true'
Outils de profileur
Accédez au profileur à partir de l'onglet Profil de TensorBoard, qui apparaît uniquement après avoir capturé certaines données du modèle.
Le Profiler dispose d'une sélection d'outils pour faciliter l'analyse des performances :
- Page de présentation
- Analyseur de pipeline d'entrée
- Statistiques TensorFlow
- Visionneuse de traces
- Statistiques du noyau GPU
- Outil de profil de mémoire
- Visionneuse de pods
Page de présentation
La page de présentation fournit une vue de niveau supérieur des performances de votre modèle lors d'une exécution de profil. La page vous montre une page de présentation agrégée pour votre hôte et tous les appareils, ainsi que quelques recommandations pour améliorer les performances de formation de votre modèle. Vous pouvez également sélectionner des hôtes individuels dans la liste déroulante Hôte.
La page de présentation affiche les données comme suit :
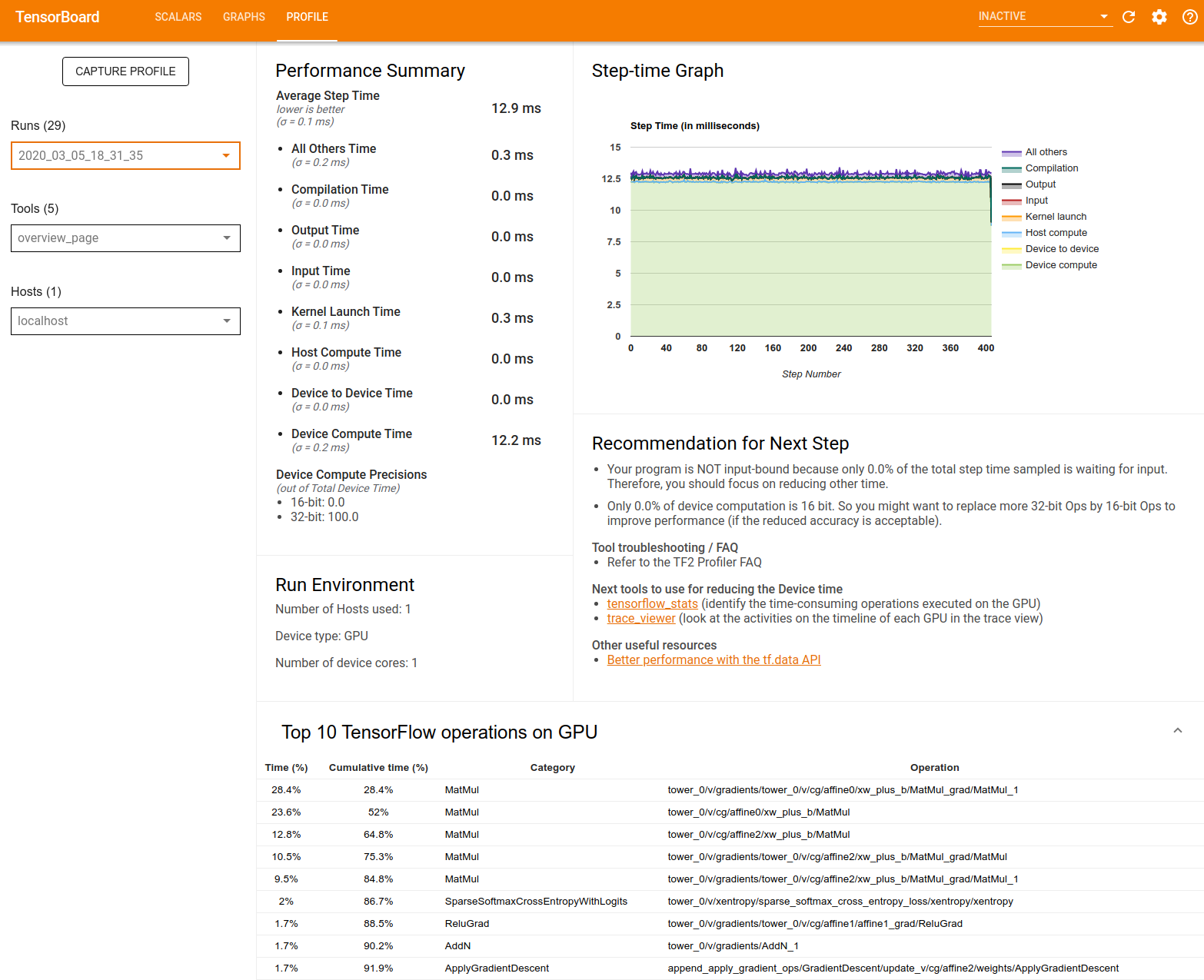
Récapitulatif des performances : affiche un résumé de haut niveau des performances de votre modèle. Le résumé des performances comprend deux parties :
Répartition du temps d'étape : décompose le temps d'étape moyen en plusieurs catégories de temps passé :
- Compilation : Temps passé à compiler les noyaux.
- Entrée : temps passé à lire les données d'entrée.
- Sortie : temps passé à lire les données de sortie.
- Lancement du noyau : temps passé par l'hôte pour lancer les noyaux
- Temps de calcul de l'hôte.
- Temps de communication d’appareil à appareil.
- Temps de calcul sur l'appareil.
- Tous les autres, y compris les frais généraux Python.
Précisions de calcul de l'appareil : indique le pourcentage du temps de calcul de l'appareil qui utilise des calculs 16 et 32 bits.
Graphique du temps de pas : affiche un graphique du temps de pas de l'appareil (en millisecondes) sur toutes les étapes échantillonnées. Chaque étape est divisée en plusieurs catégories (avec des couleurs différentes) où le temps est passé. La zone rouge correspond à la partie du temps pendant laquelle les appareils sont restés inactifs en attendant les données d'entrée de l'hôte. La zone verte indique la durée pendant laquelle l'appareil a réellement fonctionné.
Top 10 des opérations TensorFlow sur l'appareil (par exemple, GPU) : affiche les opérations sur l'appareil qui ont été exécutées le plus longtemps.
Chaque ligne affiche le temps personnel d'une opération (en pourcentage du temps pris par toutes les opérations), le temps cumulé, la catégorie et le nom.
Environnement d'exécution : affiche un résumé de haut niveau de l'environnement d'exécution du modèle, notamment :
- Nombre d'hôtes utilisés.
- Type d'appareil (GPU/TPU).
- Nombre de cœurs de périphérique.
Recommandation pour l'étape suivante : signale lorsqu'un modèle est lié aux entrées et recommande des outils que vous pouvez utiliser pour localiser et résoudre les goulots d'étranglement des performances du modèle.
Analyseur de pipeline d'entrée
Lorsqu'un programme TensorFlow lit les données d'un fichier, cela commence en haut du graphique TensorFlow de manière pipeline. Le processus de lecture est divisé en plusieurs étapes de traitement de données connectées en série, où la sortie d'une étape constitue l'entrée de la suivante. Ce système de lecture des données est appelé pipeline d'entrée .
Un pipeline typique pour lire des enregistrements à partir de fichiers comporte les étapes suivantes :
- Lecture de fichiers.
- Prétraitement des fichiers (facultatif).
- Transfert de fichiers de l'hôte vers l'appareil.
Un pipeline d'entrée inefficace peut considérablement ralentir votre application. Une application est considérée comme liée aux entrées lorsqu’elle passe une partie importante du temps dans le pipeline d’entrée. Utilisez les informations obtenues à partir de l’analyseur de pipeline d’entrée pour comprendre où le pipeline d’entrée est inefficace.
L'analyseur de pipeline d'entrée vous indique immédiatement si votre programme est lié aux entrées et vous guide dans l'analyse côté périphérique et hôte pour déboguer les goulots d'étranglement des performances à n'importe quelle étape du pipeline d'entrée.
Consultez les conseils sur les performances du pipeline d’entrée pour connaître les meilleures pratiques recommandées pour optimiser vos pipelines d’entrée de données.
Tableau de bord du pipeline d'entrée
Pour ouvrir l'analyseur de pipeline d'entrée, sélectionnez Profile , puis sélectionnez input_pipeline_analyzer dans la liste déroulante Outils .
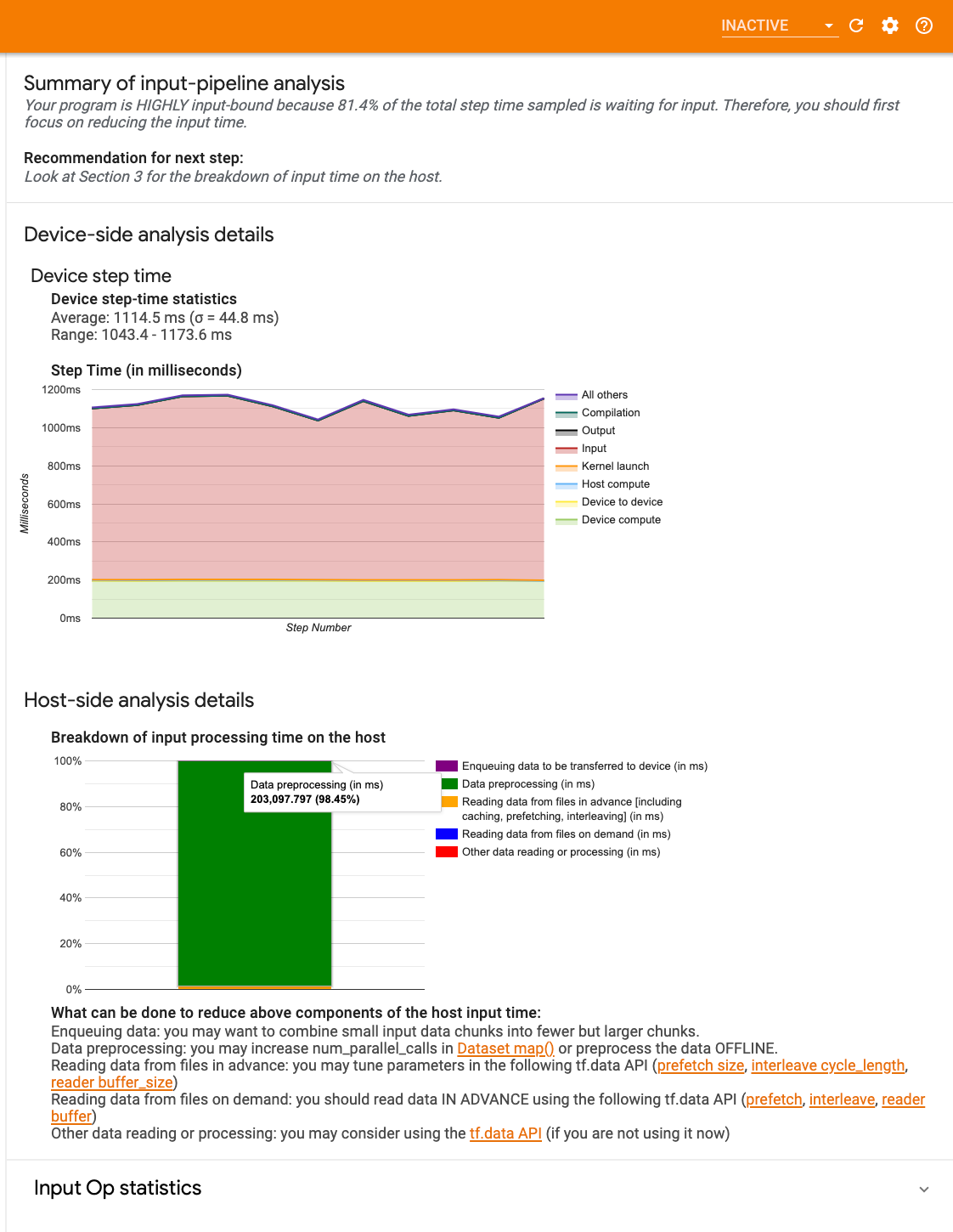
Le tableau de bord contient trois sections :
- Résumé : résume le pipeline d'entrée global avec des informations indiquant si votre application est liée aux entrées et, si oui, dans quelle mesure.
- Analyse côté appareil : affiche les résultats détaillés de l'analyse côté appareil, y compris le temps d'étape de l'appareil et la plage de temps passé par l'appareil à attendre les données d'entrée sur les cœurs à chaque étape.
- Analyse côté hôte : affiche une analyse détaillée côté hôte, y compris une répartition du temps de traitement des entrées sur l'hôte.
Résumé du pipeline d'entrée
Le résumé indique si votre programme est lié aux entrées en présentant le pourcentage de temps de l'appareil passé à attendre l'entrée de l'hôte. Si vous utilisez un pipeline d'entrée standard instrumenté, l'outil indique où est passée la majeure partie du temps de traitement des entrées.
Analyse côté appareil
L'analyse côté appareil fournit des informations sur le temps passé sur l'appareil par rapport à l'hôte et sur le temps passé par l'appareil à attendre les données d'entrée de l'hôte.
- Temps de pas tracé en fonction du numéro de pas : affiche un graphique du temps de pas de l'appareil (en millisecondes) sur toutes les étapes échantillonnées. Chaque étape est divisée en plusieurs catégories (avec des couleurs différentes) où le temps est passé. La zone rouge correspond à la partie du temps pendant laquelle les appareils sont restés inactifs en attendant les données d'entrée de l'hôte. La zone verte indique la durée pendant laquelle l'appareil a réellement fonctionné.
- Statistiques de temps de pas : indique la moyenne, l'écart type et la plage ([minimum, maximum]) du temps de pas de l'appareil.
Analyse côté hôte
L'analyse côté hôte rapporte une répartition du temps de traitement des entrées (le temps passé sur les opérations de l'API tf.data ) sur l'hôte en plusieurs catégories :
- Lecture de données à partir de fichiers à la demande : temps consacré à la lecture de données à partir de fichiers sans mise en cache, prélecture et entrelacement.
- Lecture préalable des données des fichiers : temps passé à lire les fichiers, y compris la mise en cache, la prélecture et l'entrelacement.
- Prétraitement des données : temps consacré aux opérations de prétraitement, telles que la décompression d'images.
- Mise en file d'attente des données à transférer vers l'appareil : temps passé à placer les données dans une file d'attente d'alimentation avant de transférer les données vers l'appareil.
Développez Statistiques des opérations d'entrée pour inspecter les statistiques des opérations d'entrée individuelles et leurs catégories ventilées par temps d'exécution.
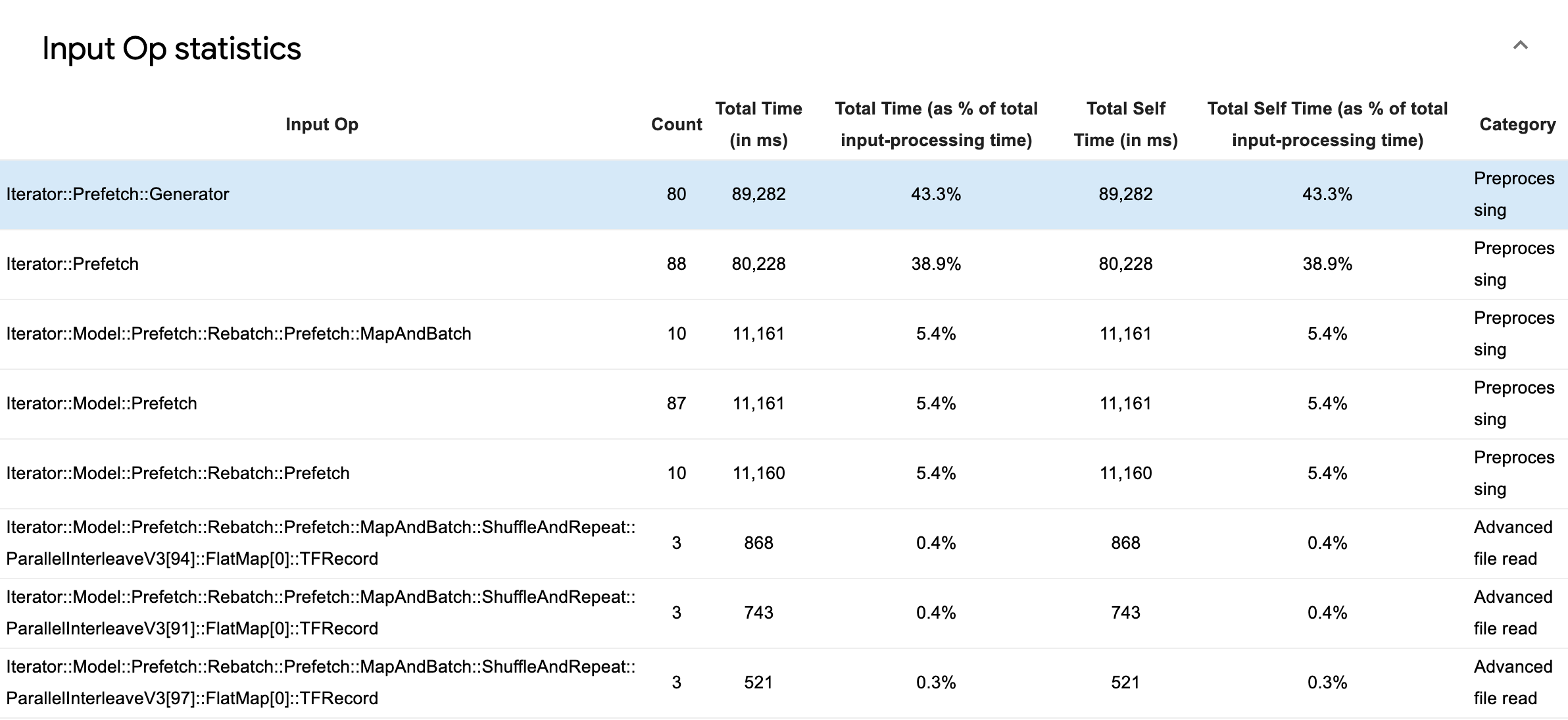
Un tableau de données sources apparaîtra avec chaque entrée contenant les informations suivantes :
- Input Op : affiche le nom de l'opération TensorFlow de l'opération d'entrée.
- Count : affiche le nombre total d'instances d'exécution d'opérations pendant la période de profilage.
- Temps total (en ms) : affiche la somme cumulée du temps passé sur chacune de ces instances.
- % de temps total : affiche le temps total passé sur une opération en tant que fraction du temps total passé au traitement des entrées.
- Temps personnel total (en ms) : affiche la somme cumulée du temps personnel passé sur chacune de ces instances. Le temps personnel mesure ici le temps passé à l'intérieur du corps de la fonction, à l'exclusion du temps passé dans la fonction qu'il appelle.
- % de temps libre total . Affiche le temps libre total sous forme de fraction du temps total consacré au traitement des entrées.
- Catégorie . Affiche la catégorie de traitement de l'opération d'entrée.
Statistiques TensorFlow
L'outil TensorFlow Stats affiche les performances de chaque opération TensorFlow exécutée sur l'hôte ou l'appareil au cours d'une session de profilage.
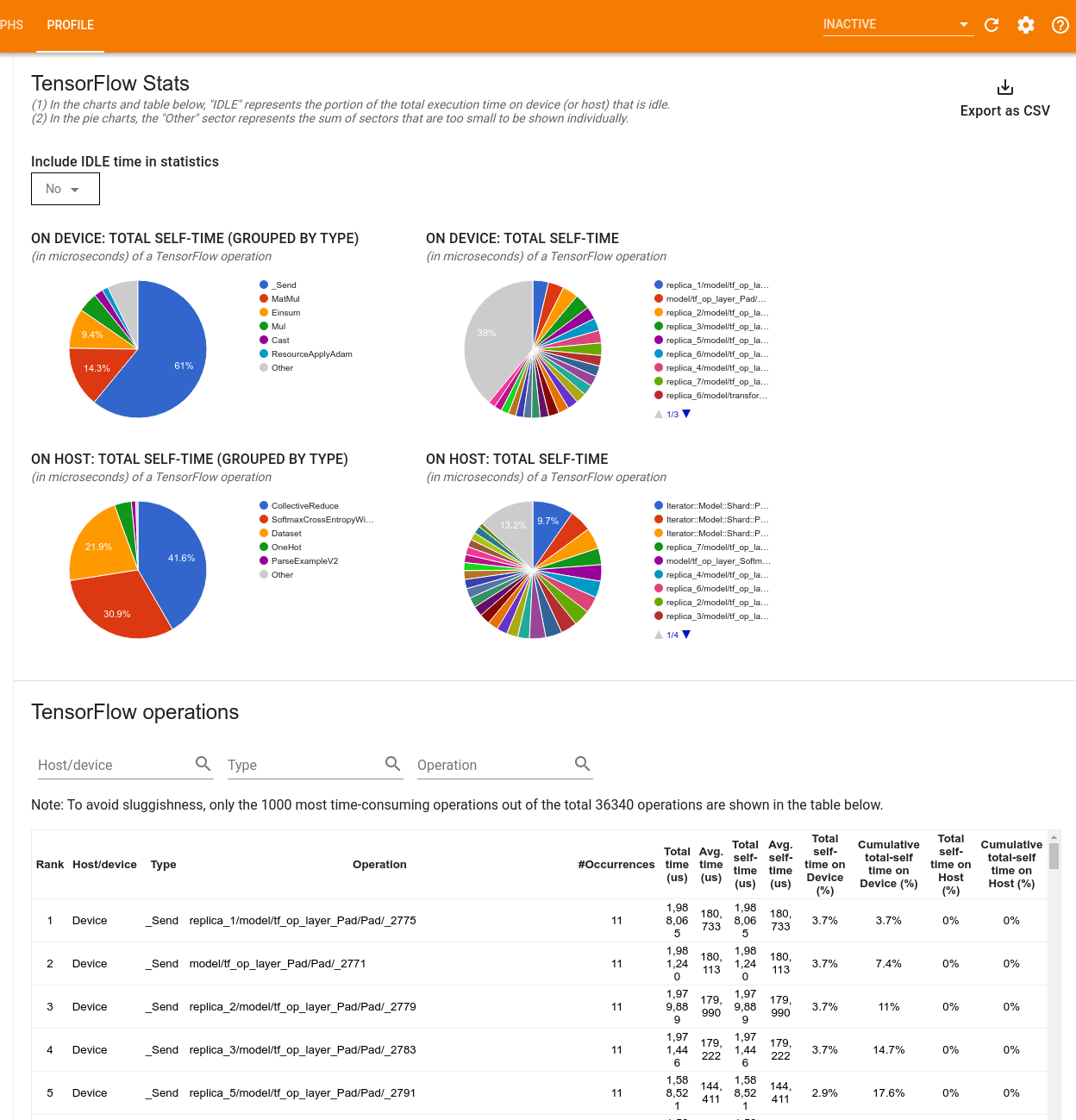
L'outil affiche les informations sur les performances dans deux volets :
Le volet supérieur affiche jusqu'à quatre diagrammes circulaires :
- La répartition du temps d'auto-exécution de chaque opération sur l'hôte.
- La répartition du temps d'auto-exécution de chaque type d'opération sur l'hôte.
- La répartition du temps d'auto-exécution de chaque opération sur l'appareil.
- La répartition du temps d'auto-exécution de chaque type d'opération sur l'appareil.
Le volet inférieur affiche un tableau qui rapporte les données sur les opérations TensorFlow avec une ligne pour chaque opération et une colonne pour chaque type de données (triez les colonnes en cliquant sur l'en-tête de la colonne). Cliquez sur le bouton Exporter au format CSV sur le côté droit du volet supérieur pour exporter les données de ce tableau sous forme de fichier CSV.
Noter que:
Si des opérations ont des opérations enfants :
- Le temps total « accumulé » d’une opération inclut le temps passé à l’intérieur des opérations enfants.
- Le temps total « auto » d'une opération n'inclut pas le temps passé à l'intérieur des opérations enfants.
Si une opération s'exécute sur l'hôte :
- Le pourcentage du temps libre total sur l'appareil encouru par l'op on sera de 0.
- Le pourcentage cumulé du temps libre total sur l'appareil jusqu'à cette opération incluse sera de 0.
Si une opération s'exécute sur l'appareil :
- Le pourcentage du temps libre total sur l'hôte encouru par cette opération sera de 0.
- Le pourcentage cumulé du temps libre total sur l'hôte jusqu'à cette opération incluse sera de 0.
Vous pouvez choisir d'inclure ou d'exclure le temps d'inactivité dans les diagrammes circulaires et le tableau.
Visionneuse de traces
La visionneuse de traces affiche une chronologie qui montre :
- Durées des opérations exécutées par votre modèle TensorFlow
- Quelle partie du système (hôte ou périphérique) a exécuté une opération. En règle générale, l'hôte exécute les opérations d'entrée, prétraite les données d'entraînement et les transfère à l'appareil, tandis que l'appareil exécute l'entraînement du modèle lui-même.
La visionneuse de traces vous permet d'identifier les problèmes de performances dans votre modèle, puis de prendre des mesures pour les résoudre. Par exemple, à un niveau élevé, vous pouvez identifier si la formation sur les entrées ou sur le modèle prend la majorité du temps. En approfondissant, vous pouvez identifier les opérations qui prennent le plus de temps à s’exécuter. Notez que la visionneuse de traces est limitée à 1 million d'événements par appareil.
Interface du visualiseur de traces
Lorsque vous ouvrez la visionneuse de traces, elle apparaît et affiche votre exécution la plus récente :
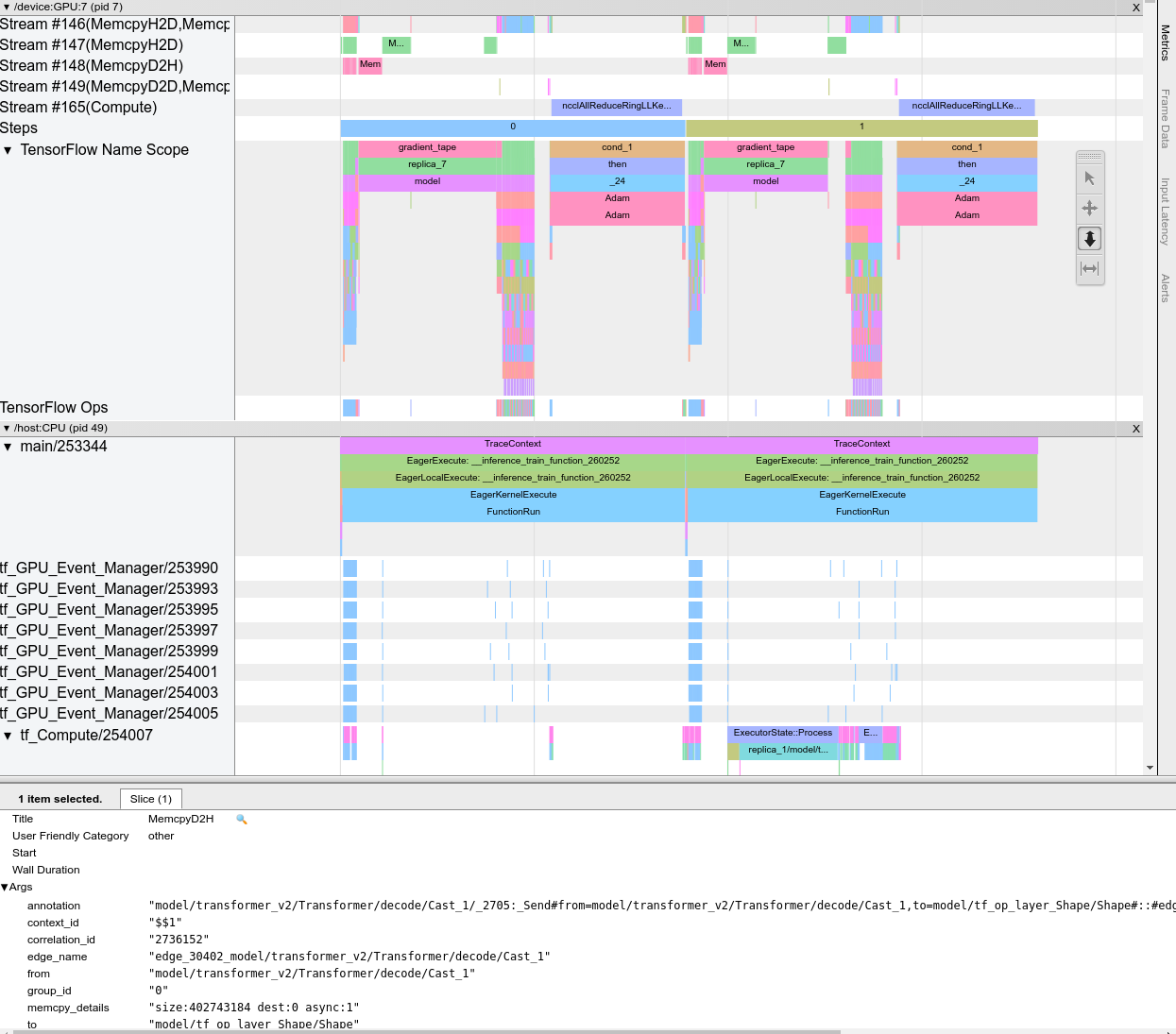
Cet écran contient les principaux éléments suivants :
- Volet Chronologie : affiche les opérations que l'appareil et l'hôte ont exécutées au fil du temps.
- Volet Détails : affiche des informations supplémentaires sur les opérations sélectionnées dans le volet Chronologie.
Le volet Chronologie contient les éléments suivants :
- Barre supérieure : Contient diverses commandes auxiliaires.
- Axe du temps : affiche le temps par rapport au début de la trace.
- Étiquettes de section et de piste : chaque section contient plusieurs pistes et comporte un triangle sur la gauche sur lequel vous pouvez cliquer pour développer et réduire la section. Il existe une section pour chaque élément de traitement du système.
- Sélecteur d'outils : contient divers outils permettant d'interagir avec la visionneuse de traces, tels que Zoom, Panoramique, Sélection et Synchronisation. Utilisez l'outil Chronométrage pour marquer un intervalle de temps.
- Événements : Ceux-ci affichent le temps pendant lequel une opération a été exécutée ou la durée des méta-événements, tels que les étapes de formation.
Sections et pistes
La visionneuse de trace contient les sections suivantes :
- Une section pour chaque nœud de périphérique , étiquetée avec le numéro de la puce du périphérique et le nœud du périphérique au sein de la puce (par exemple,
/device:GPU:0 (pid 0)). Chaque section de nœud de périphérique contient les pistes suivantes :- Étape : affiche la durée des étapes d'entraînement en cours d'exécution sur l'appareil.
- TensorFlow Ops : affiche les opérations exécutées sur l'appareil
- XLA Ops : affiche les opérations XLA (ops) exécutées sur l'appareil si XLA est le compilateur utilisé (chaque opération TensorFlow est traduite en une ou plusieurs opérations XLA. Le compilateur XLA traduit les opérations XLA en code qui s'exécute sur l'appareil).
- Une section pour les threads exécutés sur le processeur de la machine hôte, intitulée "Host Threads" . La section contient une piste pour chaque thread CPU. Notez que vous pouvez ignorer les informations affichées à côté des étiquettes de section.
Événements
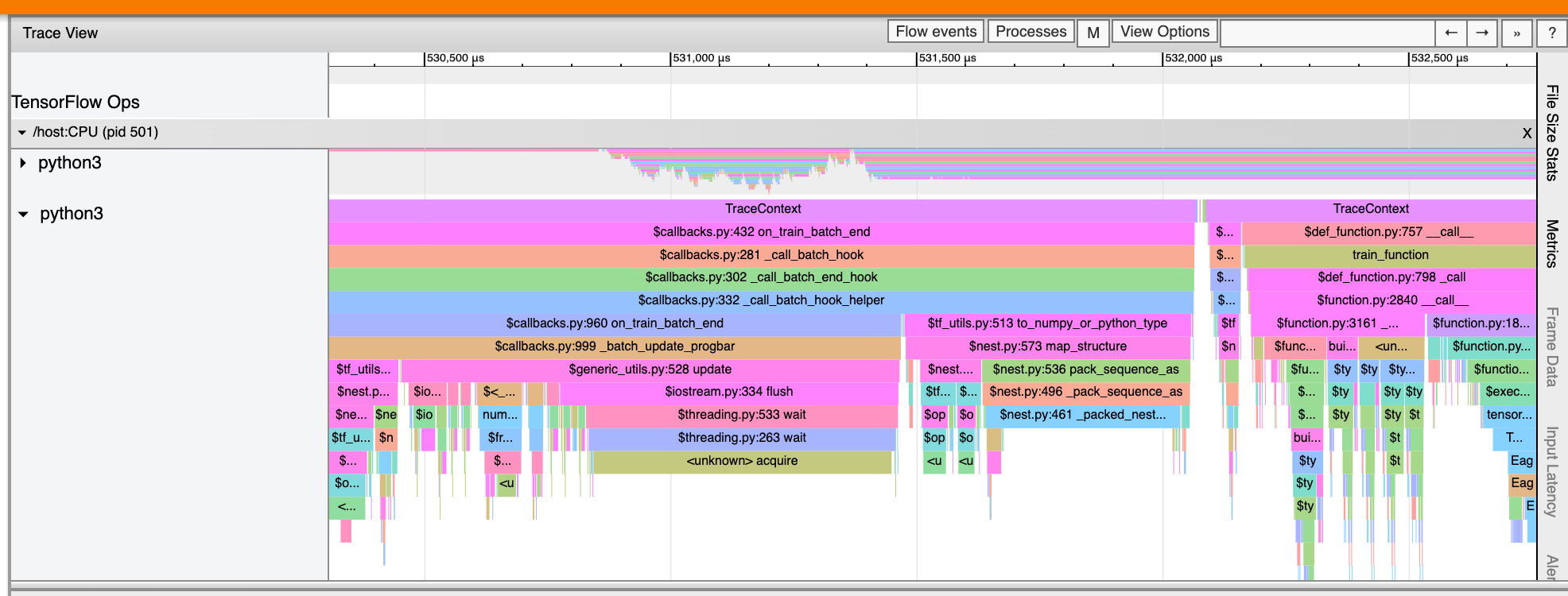
Les événements dans la chronologie sont affichés dans différentes couleurs ; les couleurs elles-mêmes n'ont pas de signification particulière.
La visionneuse de traces peut également afficher les traces des appels de fonctions Python dans votre programme TensorFlow. Si vous utilisez l'API tf.profiler.experimental.start , vous pouvez activer le traçage Python à l'aide du tuple nommé ProfilerOptions lors du démarrage du profilage. Alternativement, si vous utilisez le mode d'échantillonnage pour le profilage, vous pouvez sélectionner le niveau de traçage à l'aide des options déroulantes dans la boîte de dialogue Capturer le profil .
Statistiques du noyau GPU
Cet outil affiche les statistiques de performances et l'opération d'origine pour chaque noyau accéléré par GPU.
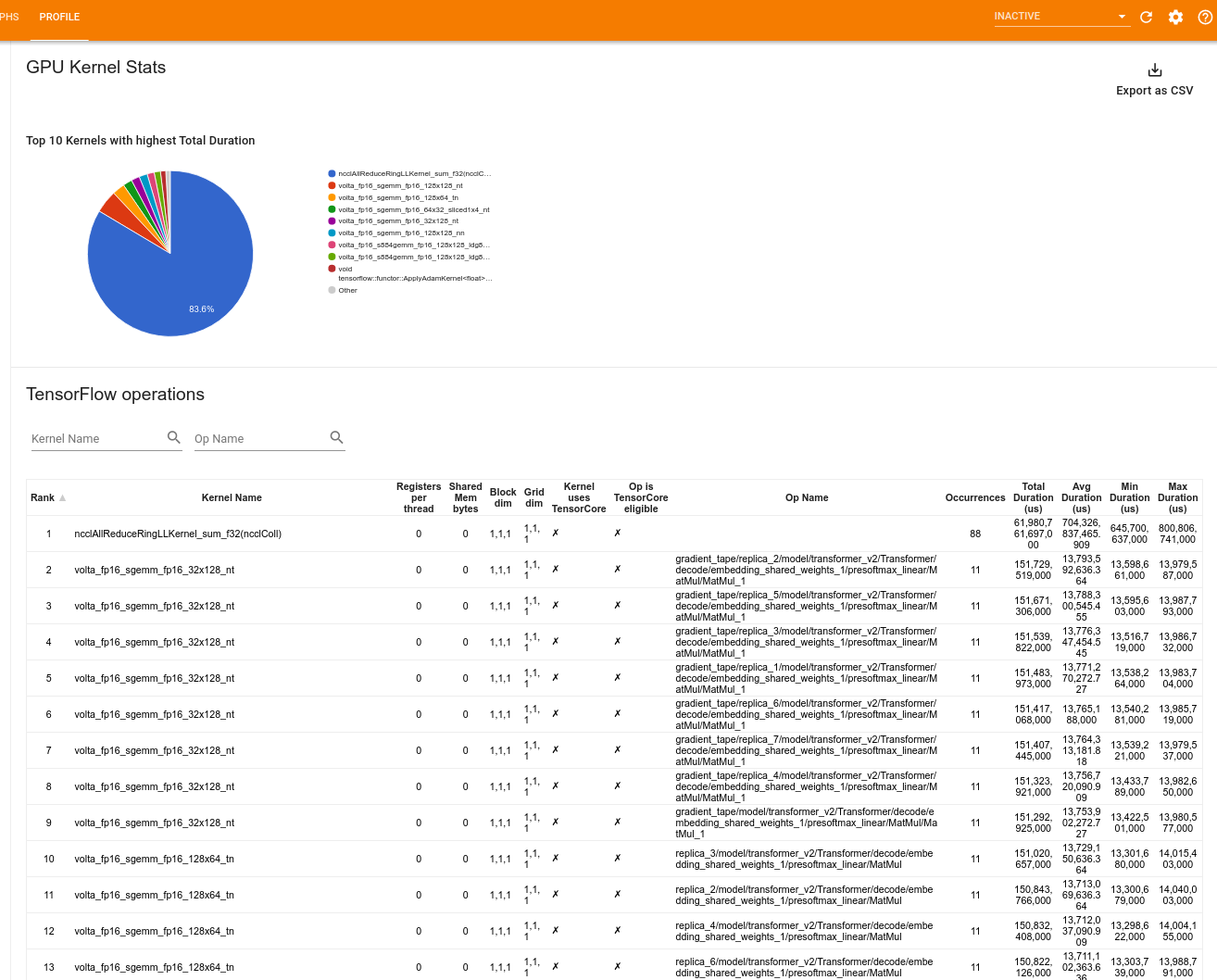
L'outil affiche les informations dans deux volets :
Le volet supérieur affiche un diagramme circulaire qui montre les noyaux CUDA pour lesquels le temps total écoulé est le plus élevé.
Le volet inférieur affiche un tableau avec les données suivantes pour chaque paire noyau-opération unique :
- Un classement par ordre décroissant de la durée totale écoulée du GPU, regroupé par paire noyau-opération.
- Le nom du noyau lancé.
- Le nombre de registres GPU utilisés par le noyau.
- Taille totale de la mémoire partagée (partagée statique + dynamique) utilisée en octets.
- La dimension du bloc exprimée sous la forme
blockDim.x, blockDim.y, blockDim.z. - Les dimensions de la grille exprimées sous la forme
gridDim.x, gridDim.y, gridDim.z. - Indique si l'opération est éligible à l'utilisation de Tensor Cores .
- Si le noyau contient des instructions Tensor Core.
- Le nom de l'opération qui a lancé ce noyau.
- Le nombre d'occurrences de cette paire noyau-opération.
- Temps GPU total écoulé en microsecondes.
- Temps GPU écoulé moyen en microsecondes.
- Temps GPU écoulé minimum en microsecondes.
- Temps GPU écoulé maximum en microsecondes.
Outil de profil de mémoire
L'outil Profil de mémoire surveille l'utilisation de la mémoire de votre appareil pendant l'intervalle de profilage. Vous pouvez utiliser cet outil pour :
- Déboguez les problèmes de manque de mémoire (MOO) en identifiant l'utilisation maximale de la mémoire et l'allocation de mémoire correspondante aux opérations TensorFlow. Vous pouvez également déboguer les problèmes de MOO qui peuvent survenir lorsque vous exécutez une inférence multi-client .
- Déboguer les problèmes de fragmentation de la mémoire.
L'outil de profil de mémoire affiche les données en trois sections :
- Résumé du profil de mémoire
- Graphique chronologique de la mémoire
- Tableau de répartition de la mémoire
Résumé du profil de mémoire
Cette section affiche un résumé de haut niveau du profil de mémoire de votre programme TensorFlow, comme indiqué ci-dessous :
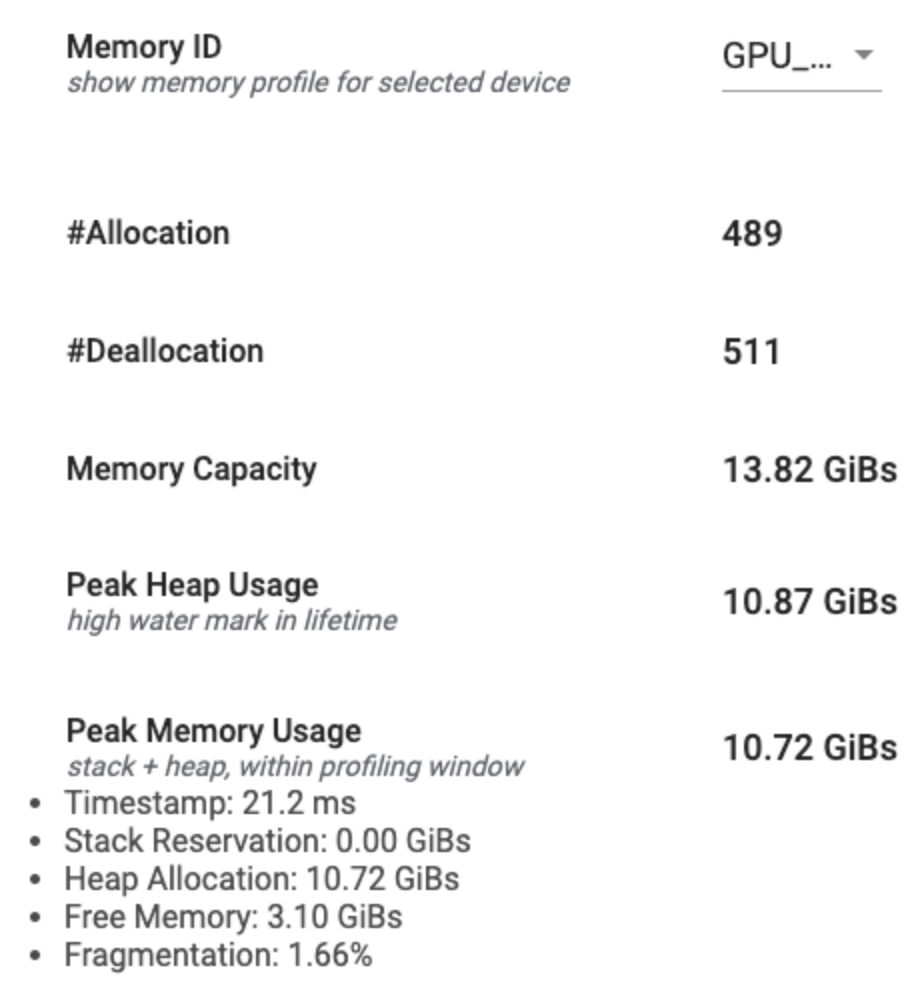
Le résumé du profil de mémoire comporte six champs :
- ID mémoire : liste déroulante qui répertorie tous les systèmes de mémoire de l'appareil disponibles. Sélectionnez le système de mémoire que vous souhaitez afficher dans la liste déroulante.
- #Allocation : Le nombre d'allocations de mémoire effectuées pendant l'intervalle de profilage.
- #Deallocation : Le nombre de désallocations de mémoire dans l'intervalle de profilage
- Capacité de la mémoire : capacité totale (en Gio) du système de mémoire que vous sélectionnez.
- Utilisation maximale du tas : utilisation maximale de la mémoire (en Gio) depuis le début de l'exécution du modèle.
- Utilisation maximale de la mémoire : utilisation maximale de la mémoire (en Gio) dans l'intervalle de profilage. Ce champ contient les sous-champs suivants :
- Horodatage : horodatage du moment où l'utilisation maximale de la mémoire s'est produite sur le graphique chronologique.
- Réservation de pile : Quantité de mémoire réservée sur la pile (en GiB).
- Allocation du tas : quantité de mémoire allouée sur le tas (en GiB).
- Mémoire libre : quantité de mémoire libre (en GiB). La capacité de mémoire est la somme totale de la réservation de pile, de l'allocation de tas et de la mémoire libre.
- Fragmentation : Le pourcentage de fragmentation (le plus bas est le mieux). Il est calculé en pourcentage de
(1 - Size of the largest chunk of free memory / Total free memory).
Graphique chronologique de la mémoire
Cette section affiche un graphique de l'utilisation de la mémoire (en GiB) et du pourcentage de fragmentation en fonction du temps (en ms).
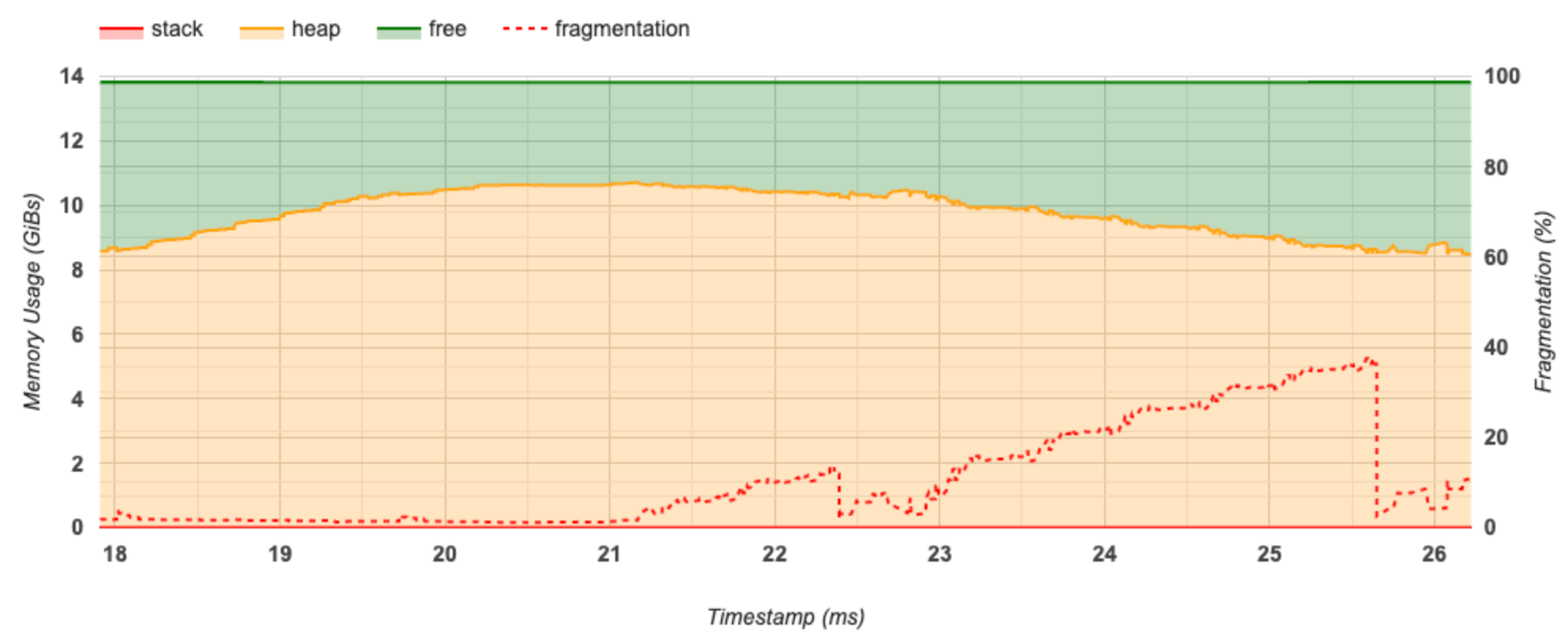
L'axe X représente la chronologie (en ms) de l'intervalle de profilage. L'axe Y à gauche représente l'utilisation de la mémoire (en GiB) et l'axe Y à droite représente le pourcentage de fragmentation. A chaque instant sur l'axe X, la mémoire totale est décomposée en trois catégories : pile (en rouge), tas (en orange) et libre (en vert). Passez la souris sur un horodatage spécifique pour afficher les détails sur les événements d'allocation/désallocation de mémoire à ce stade, comme ci-dessous :
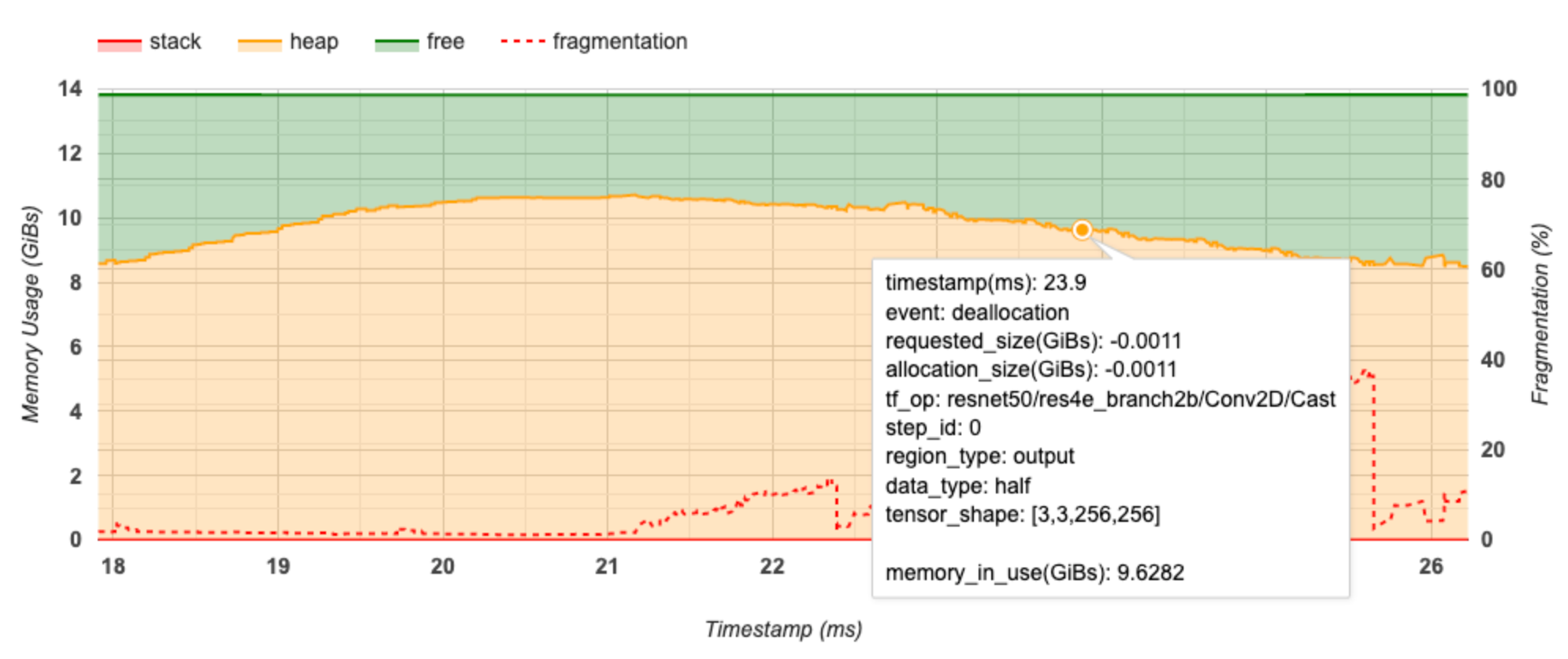
La fenêtre contextuelle affiche les informations suivantes :
- timestamp(ms) : L'emplacement de l'événement sélectionné sur la timeline.
- event : Le type d'événement (allocation ou désallocation).
- request_size(GiBs) : La quantité de mémoire demandée. Ce sera un nombre négatif pour les événements de désallocation.
- allocation_size(GiBs) : La quantité réelle de mémoire allouée. Ce sera un nombre négatif pour les événements de désallocation.
- tf_op : l'opération TensorFlow qui demande l'allocation/désallocation.
- step_id : l'étape de formation au cours de laquelle cet événement s'est produit.
- region_type : le type d'entité de données auquel cette mémoire allouée est destinée. Les valeurs possibles sont
temppour les temporaires,outputpour les activations et les gradients, etpersist/dynamicpour les poids et les constantes. - data_type : Le type d'élément tensoriel (par exemple, uint8 pour un entier non signé de 8 bits).
- tensor_shape : La forme du tenseur alloué/désalloué.
- memory_in_use(GiBs) : La mémoire totale utilisée à ce stade.
Tableau de répartition de la mémoire
Ce tableau montre les allocations de mémoire actives au point d'utilisation maximale de la mémoire dans l'intervalle de profilage.
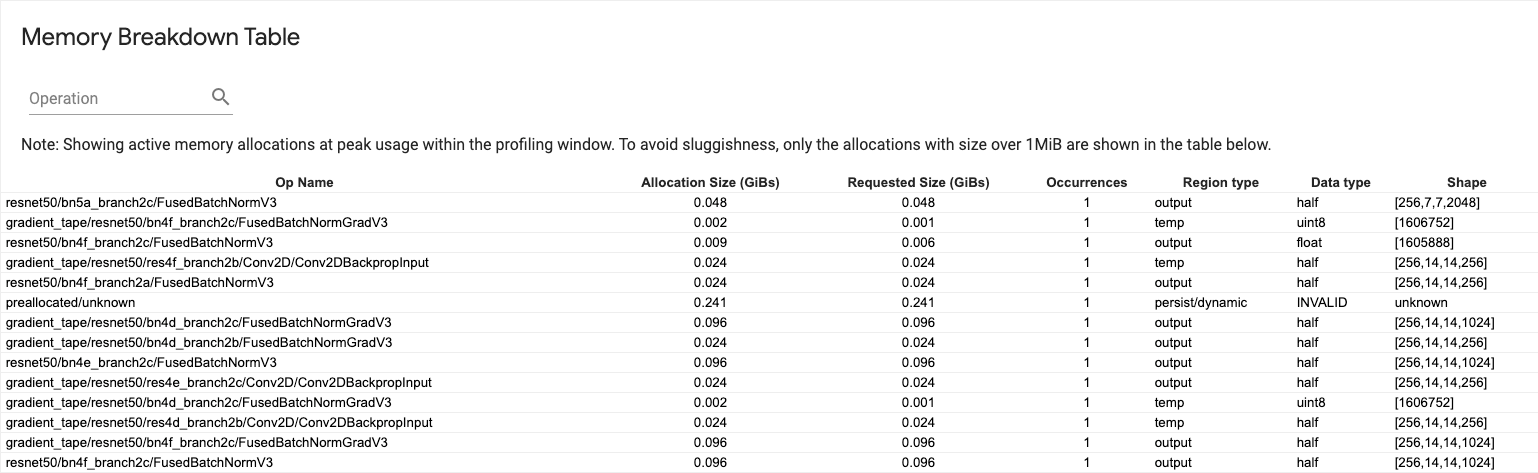
Il y a une ligne pour chaque opération TensorFlow et chaque ligne comporte les colonnes suivantes :
- Nom de l'opération : le nom de l'opération TensorFlow.
- Taille d'allocation (Gio) : quantité totale de mémoire allouée à cette opération.
- Taille demandée (Gio) : quantité totale de mémoire demandée pour cette opération.
- Occurrences : Le nombre d'allocations pour cette op.
- Type de région : type d'entité de données auquel cette mémoire allouée est destinée. Les valeurs possibles sont
temppour les temporaires,outputpour les activations et les gradients, etpersist/dynamicpour les poids et les constantes. - Type de données : Le type d'élément tensoriel.
- Shape : La forme des tenseurs alloués.
Visionneuse de pods
L'outil Pod Viewer affiche la répartition d'une étape de formation pour tous les travailleurs.
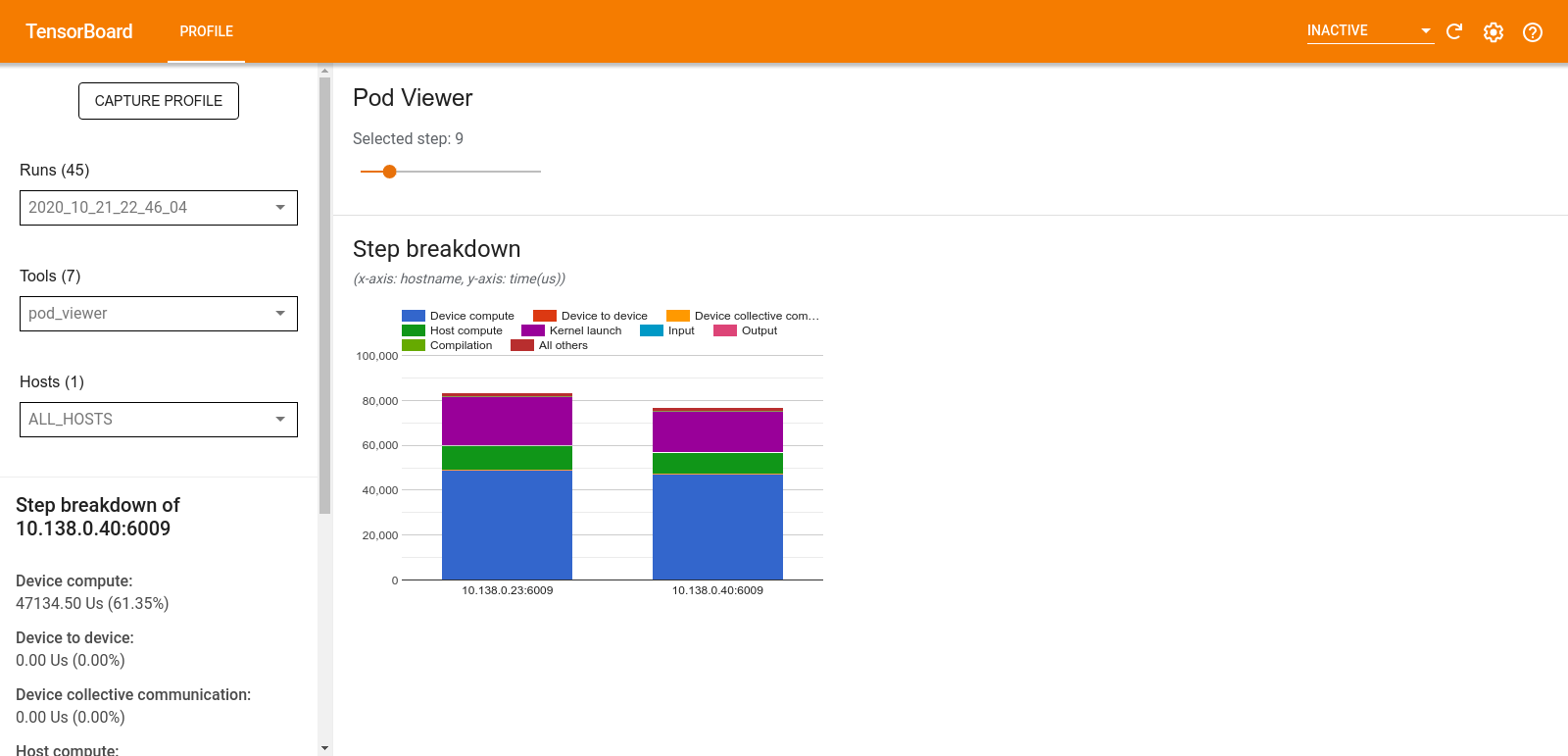
- Le volet supérieur comporte un curseur permettant de sélectionner le numéro d'étape.
- Le volet inférieur affiche un histogramme empilé. Il s'agit d'une vue de haut niveau des catégories de temps décomposées, placées les unes au-dessus des autres. Chaque colonne empilée représente un travailleur unique.
- Lorsque vous survolez une colonne empilée, la carte de gauche affiche plus de détails sur la répartition des étapes.
analyse des goulots d'étranglement tf.data
L'outil d'analyse des goulots d'étranglement tf.data détecte automatiquement les goulots d'étranglement dans les pipelines d'entrée tf.data de votre programme et fournit des recommandations sur la façon de les résoudre. Il fonctionne avec n'importe quel programme utilisant tf.data quelle que soit la plateforme (CPU/GPU/TPU). Son analyse et ses recommandations s'appuient sur ce guide .
Il détecte un goulot d'étranglement en suivant ces étapes :
- Trouvez l'hôte le plus lié aux entrées.
- Recherchez l'exécution la plus lente d'un pipeline d'entrée
tf.data. - Reconstruisez le graphique du pipeline d'entrée à partir de la trace du profileur.
- Recherchez le chemin critique dans le graphique du pipeline d'entrée.
- Identifiez la transformation la plus lente sur le chemin critique comme un goulot d’étranglement.
L'interface utilisateur est divisée en trois sections : Résumé de l'analyse des performances , Résumé de tous les pipelines d'entrée et Graphique du pipeline d'entrée .
Résumé de l'analyse des performances

Cette section fournit le résumé de l’analyse. Il signale les pipelines d'entrée tf.data lents détectés dans le profil. Cette section montre également l'hôte le plus lié aux entrées et son pipeline d'entrée le plus lent avec la latence maximale. Plus important encore, il identifie quelle partie du pipeline d’entrée constitue le goulot d’étranglement et comment y remédier. Les informations sur les goulots d'étranglement sont fournies avec le type d'itérateur et son nom long.
Comment lire le nom long de l'itérateur tf.data
Un nom long est au format Iterator::<Dataset_1>::...::<Dataset_n> . Dans le nom long, <Dataset_n> correspond au type d'itérateur et les autres ensembles de données dans le nom long représentent les transformations en aval.
Par exemple, considérons l'ensemble de données de pipeline d'entrée suivant :
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Les noms longs des itérateurs de l'ensemble de données ci-dessus seront :
| Type d'itérateur | Nom long |
|---|---|
| Gamme | Itérateur :: Batch :: Répétition :: Carte :: Plage |
| Carte | Itérateur :: Batch :: Répéter :: Carte |
| Répéter | Itérateur :: Batch :: Répéter |
| Lot | Itérateur :: Lot |
Résumé de tous les pipelines d'entrée
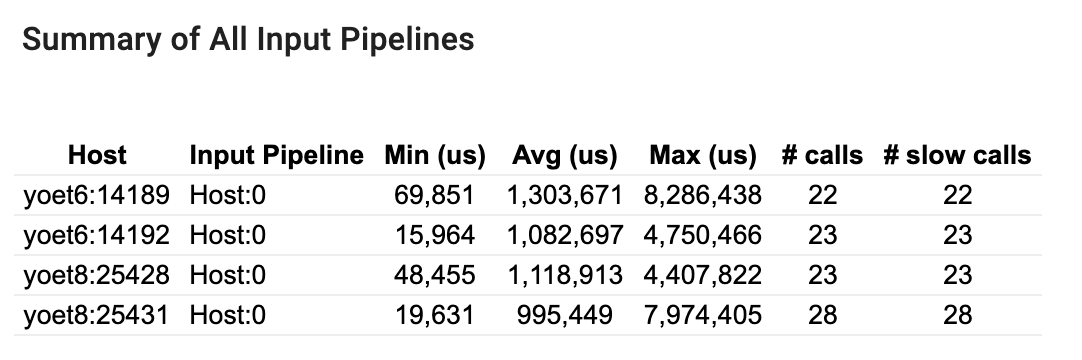
Cette section fournit le résumé de tous les pipelines d’entrée sur tous les hôtes. Il existe généralement un seul pipeline d’entrée. Lors de l'utilisation de la stratégie de distribution, il existe un pipeline d'entrée hôte exécutant le code tf.data du programme et plusieurs pipelines d'entrée de périphérique récupérant les données du pipeline d'entrée hôte et les transférant vers les périphériques.
Pour chaque pipeline d'entrée, il affiche les statistiques de son temps d'exécution. Un appel est considéré comme lent s’il dure plus de 50 μs.
Graphique du pipeline d'entrée

Cette section montre le graphique du pipeline d'entrée avec les informations de temps d'exécution. Vous pouvez utiliser « Hôte » et « Pipeline d'entrée » pour choisir l'hôte et le pipeline d'entrée à voir. Les exécutions du pipeline d'entrée sont triées selon le temps d'exécution par ordre décroissant que vous pouvez choisir à l'aide de la liste déroulante Rang .
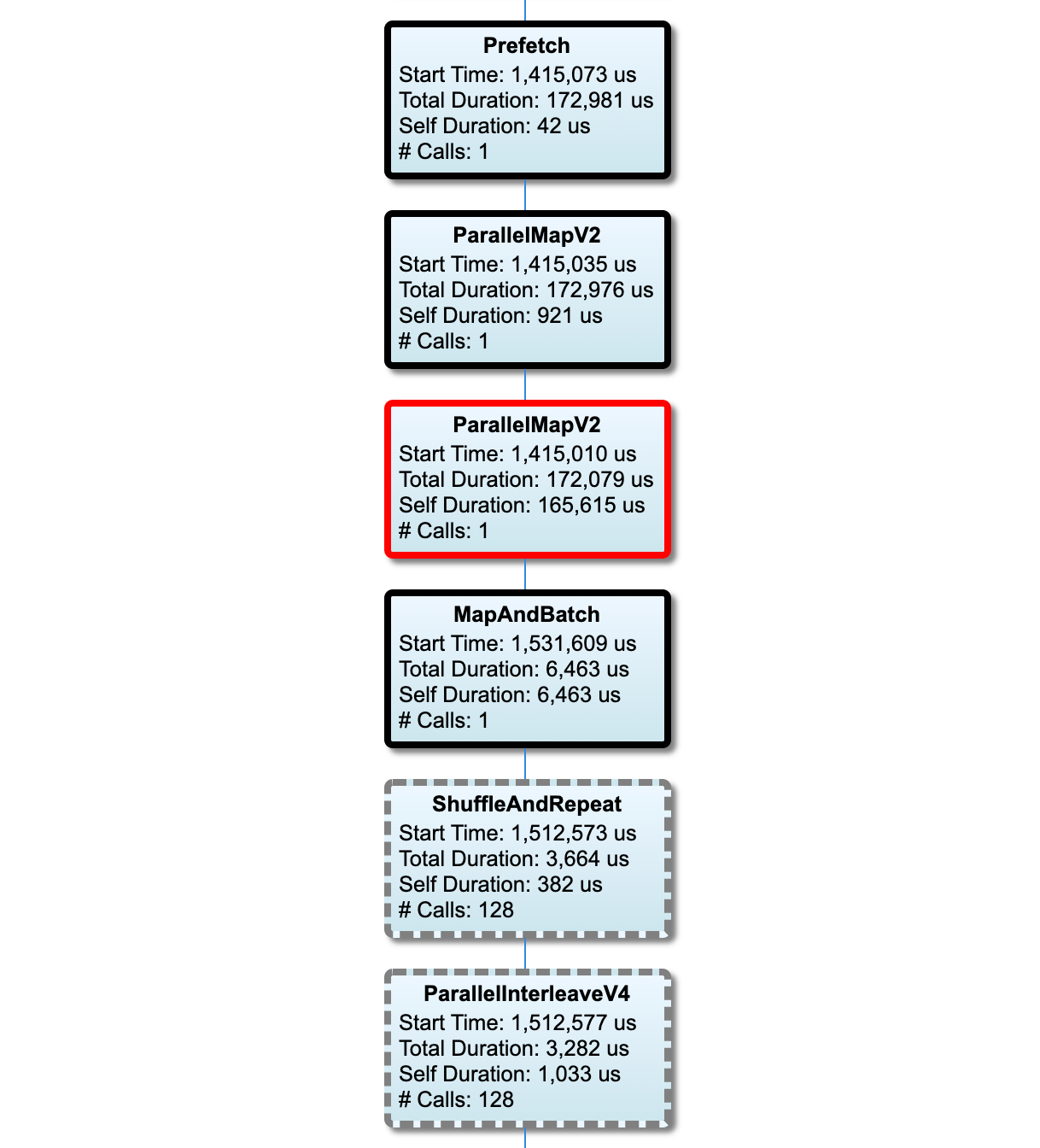
Les nœuds du chemin critique ont des contours gras. Le nœud du goulot d’étranglement, qui est le nœud avec le temps propre le plus long sur le chemin critique, a un contour rouge. Les autres nœuds non critiques ont des contours en pointillés gris.
Dans chaque nœud, Start Time indique l’heure de début de l’exécution. Le même nœud peut être exécuté plusieurs fois, par exemple s'il existe une opération Batch dans le pipeline d'entrée. S'il est exécuté plusieurs fois, il s'agit de l'heure de début de la première exécution.
La durée totale est la durée totale de l'exécution. S'il est exécuté plusieurs fois, c'est la somme des temps de mur de toutes les exécutions.
Le temps personnel correspond au temps total sans le temps superposé avec ses nœuds enfants immédiats.
« # Appels » est le nombre de fois que le pipeline d'entrée est exécuté.
Collecter des données de performances
Le TensorFlow Profiler collecte les activités de l'hôte et les traces GPU de votre modèle TensorFlow. Vous pouvez configurer le profileur pour collecter des données de performances via le mode programmatique ou le mode d'échantillonnage.
API de profilage
Vous pouvez utiliser les API suivantes pour effectuer le profilage.
Mode programmatique utilisant le rappel TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Mode programmatique utilisant l'API de fonction
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Mode programmatique utilisant le gestionnaire de contexte
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Mode d'échantillonnage : effectuez un profilage à la demande à l'aide de
tf.profiler.experimental.server.startpour démarrer un serveur gRPC avec l'exécution de votre modèle TensorFlow. Après avoir démarré le serveur gRPC et exécuté votre modèle, vous pouvez capturer un profil via le bouton Capturer le profil dans le plugin de profil TensorBoard. Utilisez le script de la section Installer le profileur ci-dessus pour lancer une instance TensorBoard si elle n'est pas déjà en cours d'exécution.A titre d'exemple,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Un exemple de profilage de plusieurs travailleurs :
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
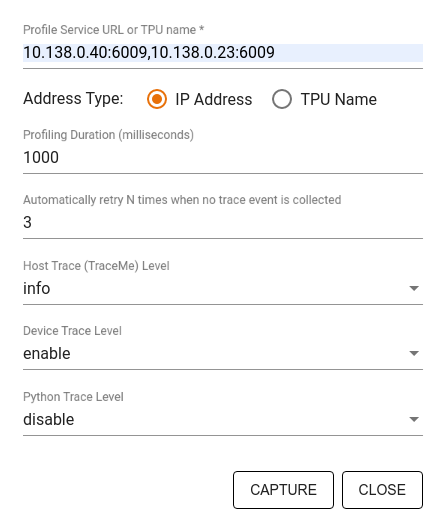
Utilisez la boîte de dialogue Profil de capture pour spécifier :
- Une liste délimitée par des virgules d'URL de service de profil ou de noms TPU.
- Une durée de profilage.
- Le niveau de suivi des appels de périphérique, d’hôte et de fonction Python.
- Combien de fois souhaitez-vous que le profileur réessaye de capturer des profils en cas d'échec au début.
Profilage de boucles de formation personnalisées
Pour profiler des boucles d'entraînement personnalisées dans votre code TensorFlow, instrumentez la boucle d'entraînement avec l'API tf.profiler.experimental.Trace pour marquer les limites des étapes pour le profileur.
L'argument name est utilisé comme préfixe pour les noms d'étape, l'argument de mot-clé step_num est ajouté aux noms d'étape et l'argument de mot-clé _r fait que cet événement de trace est traité comme un événement d'étape par le profileur.
A titre d'exemple,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Cela permettra l'analyse des performances basée sur les étapes du profileur et entraînera l'affichage des événements d'étape dans la visionneuse de trace.
Assurez-vous d'inclure l'itérateur de l'ensemble de données dans le contexte tf.profiler.experimental.Trace pour une analyse précise du pipeline d'entrée.
L'extrait de code ci-dessous est un anti-modèle :
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Cas d'utilisation du profilage
Le profileur couvre un certain nombre de cas d'utilisation selon quatre axes différents. Certaines combinaisons sont actuellement prises en charge et d'autres seront ajoutées à l'avenir. Certains des cas d'utilisation sont :
- Profilage local ou distant : il s'agit de deux manières courantes de configurer votre environnement de profilage. Dans le profilage local, l'API de profilage est appelée sur la même machine que votre modèle exécute, par exemple, un poste de travail local avec des GPU. Dans le profilage à distance, l'API de profilage est appelée sur une machine différente de celle sur laquelle votre modèle s'exécute, par exemple sur un Cloud TPU.
- Profilage de plusieurs travailleurs : vous pouvez profiler plusieurs machines lorsque vous utilisez les fonctionnalités de formation distribuée de TensorFlow.
- Plateforme matérielle : profiler les CPU, les GPU et les TPU.
Le tableau ci-dessous donne un aperçu rapide des cas d'utilisation pris en charge par TensorFlow mentionnés ci-dessus :
| API de profilage | Locale | Télécommande | Plusieurs travailleurs | Plateformes matérielles |
|---|---|---|---|---|
| Rappel TensorBoard Keras | Soutenu | Non pris en charge | Non pris en charge | Processeur, GPU |
API de démarrage/arrêt tf.profiler.experimental | Soutenu | Non pris en charge | Non pris en charge | Processeur, GPU |
API tf.profiler.experimental client.trace | Soutenu | Soutenu | Soutenu | Processeur, GPU, TPU |
| API du gestionnaire de contexte | Soutenu | Non pris en charge | Non pris en charge | Processeur, GPU |
Meilleures pratiques pour des performances optimales du modèle
Utilisez les recommandations suivantes, selon le cas, pour vos modèles TensorFlow afin d'obtenir des performances optimales.
En général, effectuez toutes les transformations sur l'appareil et assurez-vous d'utiliser la dernière version compatible des bibliothèques telles que cuDNN et Intel MKL pour votre plate-forme.
Optimiser le pipeline de données d'entrée
Utilisez les données de [#input_pipeline_analyzer] pour optimiser votre pipeline de saisie de données. Un pipeline d'entrée de données efficace peut considérablement améliorer la vitesse d'exécution de votre modèle en réduisant le temps d'inactivité des appareils. Essayez d'incorporer les meilleures pratiques détaillées dans le guide Meilleures performances avec l'API tf.data et ci-dessous pour rendre votre pipeline de saisie de données plus efficace.
En général, la parallélisation de toutes les opérations qui n'ont pas besoin d'être exécutées séquentiellement peut optimiser considérablement le pipeline d'entrée de données.
Dans de nombreux cas, il est utile de modifier l'ordre de certains appels ou d'ajuster les arguments de manière à ce qu'ils fonctionnent le mieux pour votre modèle. Lors de l'optimisation du pipeline de données d'entrée, évaluez uniquement le chargeur de données sans les étapes de formation et de rétropropagation pour quantifier l'effet des optimisations de manière indépendante.
Essayez d'exécuter votre modèle avec des données synthétiques pour vérifier si le pipeline d'entrée constitue un goulot d'étranglement en termes de performances.
Utilisez
tf.data.Dataset.shardpour la formation multi-GPU. Assurez-vous de partitionner très tôt dans la boucle d’entrée pour éviter toute réduction du débit. Lorsque vous travaillez avec TFRecords, assurez-vous de partager la liste des TFRecords et non le contenu des TFRecords.Parallélisez plusieurs opérations en définissant dynamiquement la valeur de
num_parallel_callsà l'aide detf.data.AUTOTUNE.Envisagez de limiter l'utilisation de
tf.data.Dataset.from_generatorcar il est plus lent que les opérations TensorFlow pures.Envisagez de limiter l'utilisation de
tf.py_functioncar il ne peut pas être sérialisé et n'est pas pris en charge pour s'exécuter dans TensorFlow distribué.Utilisez
tf.data.Optionspour contrôler les optimisations statiques du pipeline d'entrée.
Lisez également le guide d'analyse des performances tf.data pour plus de conseils sur l'optimisation de votre pipeline d'entrée.
Optimiser l'augmentation des données
Lorsque vous travaillez avec des données d'image, rendez l'augmentation de vos données plus efficace en convertissant différents types de données après avoir appliqué des transformations spatiales, telles que le retournement, le recadrage, la rotation, etc.
Utilisez NVIDIA® DALI
Dans certains cas, par exemple lorsque vous disposez d'un système avec un rapport GPU/CPU élevé, toutes les optimisations ci-dessus peuvent ne pas suffire à éliminer les goulots d'étranglement dans le chargeur de données dus aux limitations des cycles du processeur.
Si vous utilisez des GPU NVIDIA® pour des applications de vision par ordinateur et d'apprentissage profond audio, envisagez d'utiliser la bibliothèque de chargement de données ( DALI ) pour accélérer le pipeline de données.
Consultez la documentation NVIDIA® DALI : Opérations pour obtenir la liste des opérations DALI prises en charge.
Utiliser le threading et l'exécution parallèle
Exécutez des opérations sur plusieurs threads de processeur avec l'API tf.config.threading pour les exécuter plus rapidement.
TensorFlow définit automatiquement le nombre de threads de parallélisme par défaut. Le pool de threads disponible pour exécuter les opérations TensorFlow dépend du nombre de threads CPU disponibles.
Contrôlez l'accélération parallèle maximale pour une seule opération à l'aide de tf.config.threading.set_intra_op_parallelism_threads . Notez que si vous exécutez plusieurs opérations en parallèle, elles partageront toutes le pool de threads disponible.
Si vous disposez d'opérations indépendantes non bloquantes (opérations sans chemin dirigé entre elles sur le graphique), utilisez tf.config.threading.set_inter_op_parallelism_threads pour les exécuter simultanément à l'aide du pool de threads disponible.
Divers
Lorsque vous travaillez avec des modèles plus petits sur des GPU NVIDIA®, vous pouvez définir tf.compat.v1.ConfigProto.force_gpu_compatible=True pour forcer l'allocation de tous les tenseurs de processeur avec la mémoire épinglée CUDA afin d'améliorer considérablement les performances du modèle. Toutefois, soyez prudent lorsque vous utilisez cette option pour des modèles inconnus/très volumineux, car cela pourrait avoir un impact négatif sur les performances de l'hôte (CPU).
Améliorer les performances de l'appareil
Suivez les bonnes pratiques détaillées ici et dans le guide d'optimisation des performances GPU pour optimiser les performances du modèle TensorFlow sur l'appareil.
Si vous utilisez des GPU NVIDIA, enregistrez l'utilisation du GPU et de la mémoire dans un fichier CSV en exécutant :
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Configurer la disposition des données
Lorsque vous travaillez avec des données contenant des informations sur les canaux (comme des images), optimisez le format de présentation des données pour préférer les canaux en dernier (NHWC plutôt que NCHW).
Les formats de données du dernier canal améliorent l'utilisation de Tensor Core et offrent des améliorations significatives des performances, en particulier dans les modèles convolutifs lorsqu'ils sont associés à AMP. Les présentations de données NCHW peuvent toujours être exploitées par Tensor Cores, mais introduisent une surcharge supplémentaire en raison des opérations de transposition automatique.
Vous pouvez optimiser la disposition des données pour préférer les dispositions NHWC en définissant data_format="channels_last" pour des couches telles que tf.keras.layers.Conv2D , tf.keras.layers.Conv3D et tf.keras.layers.RandomRotation .
Utilisez tf.keras.backend.set_image_data_format pour définir le format de présentation des données par défaut pour l'API backend Keras.
Maximisez le cache L2
Lorsque vous travaillez avec des GPU NVIDIA®, exécutez l'extrait de code ci-dessous avant la boucle d'entraînement pour maximiser la granularité de récupération L2 à 128 octets.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Configurer l'utilisation du thread GPU
Le mode de thread GPU décide de la manière dont les threads GPU sont utilisés.
Définissez le mode thread sur gpu_private pour vous assurer que le prétraitement ne vole pas tous les threads GPU. Cela réduira le retard de lancement du noyau pendant la formation. Vous pouvez également définir le nombre de threads par GPU. Définissez ces valeurs à l'aide de variables d'environnement.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Configurer les options de mémoire GPU
En général, augmentez la taille du lot et évoluez le modèle pour mieux utiliser les GPU et augmenter le débit. Notez que l'augmentation de la taille du lot modifiera la précision du modèle, de sorte que le modèle doit être mis à l'échelle en réglant les hyperparamètres comme le taux d'apprentissage pour répondre à la précision cible.
En outre, utilisez tf.config.experimental.set_memory_growth pour permettre à la mémoire de GPU de croître pour éviter que toute la mémoire disponible ne soit pleinement allouée aux OP qui ne nécessitent qu'une fraction de la mémoire. Cela permet à d'autres processus qui consomment la mémoire GPU à exécuter sur le même appareil.
Pour en savoir plus, consultez les conseils limitants sur la croissance de la mémoire du GPU dans le guide GPU pour en savoir plus.
Divers
Augmentez la taille de mini-lots d'entraînement (nombre d'échantillons de formation utilisés par appareil dans une itération de la boucle d'entraînement) à la quantité maximale qui s'adapte sans erreur de mémoire (OOM) sur le GPU. L'augmentation de la taille du lot a un impact sur la précision du modèle, alors assurez-vous de mettre à l'échelle le modèle en réglant les hyperparamètres pour répondre à la précision cible.
Désactiver les erreurs de rapport OOM pendant l'allocation du tenseur dans le code de production. Set
report_tensor_allocations_upon_oom=Falsedanstf.compat.v1.RunOptions.Pour les modèles avec des couches de convolution, supprimez l'ajout de biais si vous utilisez une normalisation par lots. La normalisation par lots déplace les valeurs par leur moyenne et cela supprime la nécessité d'avoir un terme de biais constant.
Utilisez des statistiques TF pour savoir à quel point les OPS à disque efficaces fonctionnent efficacement.
Utilisez
tf.functionpour effectuer des calculs et éventuellement, activez lejit_compile=TrueFlag (tf.function(jit_compile=True). Pour en savoir plus, allez utiliser xla tf.function .Minimiser les opérations de Python hôte entre les étapes et réduire les rappels. Calculez les mesures toutes les quelques pas au lieu de chaque étape.
Gardez l'appareil calculer les unités occupées.
Envoyez des données à plusieurs appareils en parallèle.
Envisagez d'utiliser des représentations numériques 16 bits , telles que
fp16- le format de point flottant à demi-précision spécifié par IEEE - ou le format BFLOAT16 à virgule flottante cérébrale.
Ressources supplémentaires
- Le TensorFlow Profiler: Profil Model Performance Tutoriel avec Keras et Tensorboard où vous pouvez appliquer les conseils dans ce guide.
- Le profilage des performances dans TensorFlow 2 Talk à partir du TensorFlow Dev Summit 2020.
- La démonstration du profil TensorFlow de TensorFlow Dev Summit 2020.
Limitations connues
Profilage de plusieurs GPU sur TensorFlow 2.2 et TensorFlow 2.3
TensorFlow 2.2 et 2.3 Prise en charge du profilage GPU multiple pour les systèmes hôtes uniques uniquement; Le profilage GPU multiple pour les systèmes multi-hôte n'est pas pris en charge. Pour profil les configurations de GPU multi-travailleurs, chaque travailleur doit être profilé indépendamment. De TensorFlow 2.4, plusieurs travailleurs peuvent être profilés à l'aide de l'API tf.profiler.experimental.client.trace .
La boîte à outils CUDA® 10.2 ou ultérieure est nécessaire pour profiler plusieurs GPU. Comme TensorFlow 2.2 et 2.3 Prise en charge des versions CUDA® Toolkit uniquement jusqu'à 10.1, vous devez créer des liens symboliques vers libcudart.so.10.1 et libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1