
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
|
セットアップ
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
2022-12-14 21:42:27.685244: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:42:27.685342: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:42:27.685351: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
はじめに
このガイドでは、トレーニングと検証に組み込みAPI(model.fit()、model.evaluate()、model.predict() など)を使用する場合のトレーニング、評価、予測(推論)モデルについて説明します。
独自のトレーニングステップ関数を指定しながら fit() を利用する場合は、「fit() の処理をカスタマイズする」ガイドをご覧ください。
独自のトレーニングと評価ループを新規に作成する場合は、「トレーニングループの新規作成」をご覧ください。
一般的にモデルのトレーニングと評価は、組み込みループを使用するか独自のループを作成するかに関係なく、すべての Keras モデル(Sequential モデル、Functional API を使用して構築されたモデル、モデルのサブクラス化により新規作成されたモデル)で同じように機能します。
このガイドは、分散型トレーニングについては説明されていません。この説明はマルチ GPU と分散型トレーニングに関するガイドをご覧ください。
API の概要:最初のエンドツーエンドの例
モデルの組み込みトレーニングループにデータを渡すときは、NumPy 配列(データが小さく、メモリに収まる場合)または tf.data Dataset オブジェクトを使用する必要があります。 以下の例では、オプティマイザ、損失、およびメトリクスの使用方法を示すために、MNIST データセットを NumPy 配列として使用します。
次のモデルを見てみましょう(ここでは、Functional API を使用して構築していますが、Sequential モデルまたはサブクラス化モデルも使用可能です)。
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
一般的なエンドツーエンドのワークフローは以下のとおりです。
- トレーニング
- 元のトレーニングデータから生成されたホールドアウトセットの検証
- テストデータの評価
この例では MNIST データを使用します。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Preprocess the data (these are NumPy arrays)
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
トレーニングの構成(オプティマイザ、損失、メトリクス)を指定します。
model.compile(
optimizer=keras.optimizers.RMSprop(), # Optimizer
# Loss function to minimize
loss=keras.losses.SparseCategoricalCrossentropy(),
# List of metrics to monitor
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
fit() を呼び出します。これは、データを batch_size サイズの「バッチ」にスライスし、指定された数の epochs 間にデータセット全体を繰り返しイテレートすることでモデルをトレーニングします。
print("Fit model on training data")
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=2,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(x_val, y_val),
)
Fit model on training data Epoch 1/2 782/782 [==============================] - 4s 3ms/step - loss: 0.3639 - sparse_categorical_accuracy: 0.8973 - val_loss: 0.1885 - val_sparse_categorical_accuracy: 0.9446 Epoch 2/2 782/782 [==============================] - 2s 2ms/step - loss: 0.1708 - sparse_categorical_accuracy: 0.9490 - val_loss: 0.1303 - val_sparse_categorical_accuracy: 0.9621
返された history オブジェクトは、トレーニング間の損失値とメトリクス値の記録を保持します。
history.history
{'loss': [0.36385416984558105, 0.17080071568489075],
'sparse_categorical_accuracy': [0.8973000049591064, 0.94896000623703],
'val_loss': [0.18849268555641174, 0.13027681410312653],
'val_sparse_categorical_accuracy': [0.944599986076355, 0.9621000289916992]}
evaluate() を介してテストデータでモデルを評価します。
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test acc:", results)
# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(x_test[:3])
print("predictions shape:", predictions.shape)
79/79 [==============================] - 0s 2ms/step - loss: 0.1316 - sparse_categorical_accuracy: 0.9607 test loss, test acc: [0.13158978521823883, 0.9606999754905701] Generate predictions for 3 samples 1/1 [==============================] - 0s 71ms/step predictions shape: (3, 10)
では、このワークフローの各部分を詳しく見ていきましょう。
compile() メソッド: 損失、メトリクス、およびオプティマイザを指定する
fit() を使用してモデルをトレーニングするには、損失関数、オプティマイザ、および必要に応じて監視するメトリクスを指定する必要があります。
これらを compile() メソッドの引数としてモデルに渡します。
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
metrics 引数はリストである必要があります。モデルは任意の数のメトリクスを持つことができます。
モデルに複数の出力がある場合、出力ごとに異なる損失とメトリクスを指定でき、モデルの総損失に対する各出力の貢献を修正できます。詳細については、「 データを多入力多出力モデルに渡す」セクションをご覧ください。
デフォルト設定に満足している場合、多くの場合、オプティマイザ、損失、およびメトリクスは、ショートカットとして文字列識別子を介して指定できます。
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
後で再利用できるよう、モデルの定義とコンパイルの手順を関数に入れましょう。このガイドでは、さまざまな例でこの関数を何度か呼び出しています。
def get_uncompiled_model():
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, activation="softmax", name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
def get_compiled_model():
model = get_uncompiled_model()
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
return model
提供されている多数の組み込みオプティマイザ、損失、およびメトリクス
一般的に、Keras API には必要とされているものが含まれているため、一般的に、独自の損失、メトリクス、またはオプティマイザを新規作成する必要はありません。
オプティマイザ:
SGD()(モメンタムの有無に関係なく)RMSprop()Adam()- など
損失:
MeanSquaredError()KLDivergence()CosineSimilarity()- など
メトリクス:
AUC()Precision()Recall()- など
カスタム損失
カスタム損失を作成する必要がある場合、Keras には作成する方法が 2 つあります。
最初の方法は、入力 y_true と y_pred を受け入れる関数を作成する方法です。次の例は、実データと予測の間の平均二乗誤差を計算する損失関数を示しています。
def custom_mean_squared_error(y_true, y_pred):
return tf.math.reduce_mean(tf.square(y_true - y_pred))
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)
# We need to one-hot encode the labels to use MSE
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
782/782 [==============================] - 3s 2ms/step - loss: 0.0165 <keras.callbacks.History at 0x7f87d019d8e0>
y_trueおよびy_pred以外のパラメータを取る損失関数が必要な場合は、tf.keras.losses.Loss クラスをサブクラス化して、次の 2 つのメソッドを実装できます。
__init__(self): 損失関数の呼び出し中に渡すパラメータを受け入れるcall(self, y_true, y_pred): ターゲット(y_true)とモデル予測(y_pred)を使用してモデルの損失を計算する
平均二乗誤差を使用する際に、0.5 より離れた予測値にペナルティを与えるとします(カテゴリターゲットはワンホットエンコードされ、0 と 1 の間の値を取ると想定します)。これにより、モデルの信頼性が調整され、過剰適合を防ぐのに役立ちます(ただし、実際に試してみるまで、その効果はわかりません!)。
以下のように記述します。
class CustomMSE(keras.losses.Loss):
def __init__(self, regularization_factor=0.1, name="custom_mse"):
super().__init__(name=name)
self.regularization_factor = regularization_factor
def call(self, y_true, y_pred):
mse = tf.math.reduce_mean(tf.square(y_true - y_pred))
reg = tf.math.reduce_mean(tf.square(0.5 - y_pred))
return mse + reg * self.regularization_factor
model = get_uncompiled_model()
model.compile(optimizer=keras.optimizers.Adam(), loss=CustomMSE())
y_train_one_hot = tf.one_hot(y_train, depth=10)
model.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)
782/782 [==============================] - 3s 2ms/step - loss: 0.0387 <keras.callbacks.History at 0x7f87e96db3a0>
カスタムメトリック
API に含まれていないメトリックが必要な場合は、tf.keras.metrics.Metricクラスをサブクラス化することにより、カスタムメトリックを簡単に作成できます。
__init__(self)- メトリックの状態変数を作成します。update_state(self, y_true, y_pred, sample_weight=None)- ターゲット (y_true) とモデル予測 (y_pred) を使用し状態変数を更新します。result(self)- 状態変数を使用して最終結果を計算します。reset_state(self)- メトリックの状態を再初期化します。
多くの場合、結果の計算に非常に負荷がかかり、定期的にしか実行されないため、状態の更新(update_state())と結果の計算(result())は別々に保持されます。
以下は、CategoricalTruePositivesメトリックを実装する方法を示す簡単な例です。これは、特定のクラスに属するものとして正しく分類されたサンプル数を数えます。
class CategoricalTruePositives(keras.metrics.Metric):
def __init__(self, name="categorical_true_positives", **kwargs):
super(CategoricalTruePositives, self).__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name="ctp", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))
values = tf.cast(y_true, "int32") == tf.cast(y_pred, "int32")
values = tf.cast(values, "float32")
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, "float32")
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
def reset_state(self):
# The state of the metric will be reset at the start of each epoch.
self.true_positives.assign(0.0)
model = get_uncompiled_model()
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[CategoricalTruePositives()],
)
model.fit(x_train, y_train, batch_size=64, epochs=3)
Epoch 1/3 782/782 [==============================] - 2s 2ms/step - loss: 0.3412 - categorical_true_positives: 45135.0000 Epoch 2/3 782/782 [==============================] - 2s 2ms/step - loss: 0.1684 - categorical_true_positives: 47499.0000 Epoch 3/3 782/782 [==============================] - 2s 2ms/step - loss: 0.1245 - categorical_true_positives: 48095.0000 <keras.callbacks.History at 0x7f87e96db8e0>
標準のシグネチャに適合しない損失と測定基準の処理
大多数の損失とメトリクスは、y_trueおよびy_predから計算できます。この場合、y_predはモデルの出力です。例外として、正則化損失ではレイヤーのアクティブ化のみが必要で(この場合はターゲットはありません)、このアクティブ化はモデルの出力ではない場合があります。
このような場合は、カスタムレイヤーの呼び出しメソッド内から self.add_loss(loss_value) を呼び出すことができます。この方法で追加された損失は、トレーニング時に「メイン」の損失(compile() に渡されたもの)に追加されます。以下は、アクティビティの正規化を追加する簡単な例です(アクティビティの正規化はすべての Keras レイヤーに組み込まれています。このレイヤーは具体的な例を示すためのものです)。
class ActivityRegularizationLayer(layers.Layer):
def call(self, inputs):
self.add_loss(tf.reduce_sum(inputs) * 0.1)
return inputs # Pass-through layer.
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
# Insert activity regularization as a layer
x = ActivityRegularizationLayer()(x)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
# The displayed loss will be much higher than before
# due to the regularization component.
model.fit(x_train, y_train, batch_size=64, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 2.5220 <keras.callbacks.History at 0x7f875c260190>
add_metric() を使用して、メトリクス値のロギングに対して同じく実行できます。
class MetricLoggingLayer(layers.Layer):
def call(self, inputs):
# The `aggregation` argument defines
# how to aggregate the per-batch values
# over each epoch:
# in this case we simply average them.
self.add_metric(
keras.backend.std(inputs), name="std_of_activation", aggregation="mean"
)
return inputs # Pass-through layer.
inputs = keras.Input(shape=(784,), name="digits")
x = layers.Dense(64, activation="relu", name="dense_1")(inputs)
# Insert std logging as a layer.
x = MetricLoggingLayer()(x)
x = layers.Dense(64, activation="relu", name="dense_2")(x)
outputs = layers.Dense(10, name="predictions")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
model.fit(x_train, y_train, batch_size=64, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 0.3359 - std_of_activation: 0.9249 <keras.callbacks.History at 0x7f87d00f6c40>
Functional API では、model.add_loss(loss_tensor) または model.add_metric(metric_tensor, name, aggregation) を呼び出せます。
簡単な例を下記に示します。
inputs = keras.Input(shape=(784,), name="digits")
x1 = layers.Dense(64, activation="relu", name="dense_1")(inputs)
x2 = layers.Dense(64, activation="relu", name="dense_2")(x1)
outputs = layers.Dense(10, name="predictions")(x2)
model = keras.Model(inputs=inputs, outputs=outputs)
model.add_loss(tf.reduce_sum(x1) * 0.1)
model.add_metric(keras.backend.std(x1), name="std_of_activation", aggregation="mean")
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
model.fit(x_train, y_train, batch_size=64, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 2.4983 - std_of_activation: 0.0019 <keras.callbacks.History at 0x7f8754746eb0>
add_loss() を介して損失を渡すと、モデルにはすでに最小化する損失があるため、損失関数なしで compile() を呼び出すことが可能になります。
次の LogisticEndpoint レイヤーでは、入力としてターゲットとロジットを取り、add_loss() を介してクロスエントロピー損失を追跡します。また、add_metric() を介して分類の精度を追跡します。
class LogisticEndpoint(keras.layers.Layer):
def __init__(self, name=None):
super(LogisticEndpoint, self).__init__(name=name)
self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)
self.accuracy_fn = keras.metrics.BinaryAccuracy()
def call(self, targets, logits, sample_weights=None):
# Compute the training-time loss value and add it
# to the layer using `self.add_loss()`.
loss = self.loss_fn(targets, logits, sample_weights)
self.add_loss(loss)
# Log accuracy as a metric and add it
# to the layer using `self.add_metric()`.
acc = self.accuracy_fn(targets, logits, sample_weights)
self.add_metric(acc, name="accuracy")
# Return the inference-time prediction tensor (for `.predict()`).
return tf.nn.softmax(logits)
次のように、loss 引数なしでコンパイルされた 2 つの入力(入力データとターゲット)を持つモデルで使用できます。
import numpy as np
inputs = keras.Input(shape=(3,), name="inputs")
targets = keras.Input(shape=(10,), name="targets")
logits = keras.layers.Dense(10)(inputs)
predictions = LogisticEndpoint(name="predictions")(logits, targets)
model = keras.Model(inputs=[inputs, targets], outputs=predictions)
model.compile(optimizer="adam") # No loss argument!
data = {
"inputs": np.random.random((3, 3)),
"targets": np.random.random((3, 10)),
}
model.fit(data)
1/1 [==============================] - 1s 500ms/step - loss: 1.0560 - binary_accuracy: 0.0000e+00 <keras.callbacks.History at 0x7f87545bdd60>
多入力モデルのトレーニングの詳細については、「多入力多出力モデルにデータを渡す」をご覧ください。
自動的にホールドアウトセットを別にする
最初に紹介したエンドツーエンドの例では、各エポックの終わりに検証損失と検証メトリクスを評価するために、NumPy 配列のタプル (x_val, y_val) をモデルに渡すために validation_data 引数を使用しました。
もう一つのオプションとして、validation_split 引数を使うと、検証用に自動的にトレーニングデータの一部を予約しておくことができます。 引数値は検証用に予約されるデータの割合を表すため、0 より高く 1 より低い数字に設定する必要があります。たとえば、validation_split=0.2 は「検証用にデータの 20% を使用する」ことを意味し、validation_split=0.6 は「検証用にデータの 60% を使用する」ことを意味します。
シャッフルの前に、fit() の呼び出しが受け取った配列の最後の x% サンプルを取って検証が計算されます。
NumPy データでトレーニングする場合は、validation_split のみを使用できることに注意してください。
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=64, validation_split=0.2, epochs=1)
625/625 [==============================] - 2s 3ms/step - loss: 0.3790 - sparse_categorical_accuracy: 0.8919 - val_loss: 0.2434 - val_sparse_categorical_accuracy: 0.9258 <keras.callbacks.History at 0x7f87d02acd30>
tf.data データセットからのトレーニングと評価
前の段落では、損失、メトリクスおよびオプティマイザをどのように扱うかを見ました。そしてデータが Numpy 配列として渡されるとき、fit() で validation_data と validation_split 引数をどのように使用するかを見ました。
次に、データが tf.data.Dataset オブジェクトの形式で渡される場合を見てみましょう。
tf.data API は高速でスケーラブルな方法でデータを読み込んで前処理するための TensorFlow 2.0 の一連のユティリティです。
Datasets の作成についての詳細は、tf.data ドキュメントをご覧ください。
Dataset のインスタンスは、fit()、evaluate()、predict() メソッドに直接的に渡すことができます。
model = get_compiled_model()
# First, let's create a training Dataset instance.
# For the sake of our example, we'll use the same MNIST data as before.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)
# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3)
# You can also evaluate or predict on a dataset.
print("Evaluate")
result = model.evaluate(test_dataset)
dict(zip(model.metrics_names, result))
Epoch 1/3
782/782 [==============================] - 2s 2ms/step - loss: 0.3397 - sparse_categorical_accuracy: 0.9037
Epoch 2/3
782/782 [==============================] - 2s 2ms/step - loss: 0.1626 - sparse_categorical_accuracy: 0.9515
Epoch 3/3
782/782 [==============================] - 2s 2ms/step - loss: 0.1173 - sparse_categorical_accuracy: 0.9647
Evaluate
157/157 [==============================] - 0s 2ms/step - loss: 0.1195 - sparse_categorical_accuracy: 0.9621
{'loss': 0.11952614784240723,
'sparse_categorical_accuracy': 0.9621000289916992}
データセットは各エポックの最後にリセットされるため、次のエポックで再利用できます。
このデータセットから特定の数のバッチでのみトレーニングを実行する場合は、steps_per_epoch引数を渡します。これは、次のエポックに進む前に、このデータセットを使用してモデルが実行するトレーニングステップの数を指定します。
この場合、データセットは各エポックの終わりにリセットされず、次のバッチを取得し続けます。最終的にデータセットのデータは使い果たされます(無限ループのデータセットでない限り)。
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Only use the 100 batches per epoch (that's 64 * 100 samples)
model.fit(train_dataset, epochs=3, steps_per_epoch=100)
Epoch 1/3 100/100 [==============================] - 1s 2ms/step - loss: 0.7993 - sparse_categorical_accuracy: 0.7953 Epoch 2/3 100/100 [==============================] - 0s 2ms/step - loss: 0.3691 - sparse_categorical_accuracy: 0.8959 Epoch 3/3 100/100 [==============================] - 0s 2ms/step - loss: 0.3126 - sparse_categorical_accuracy: 0.9084 <keras.callbacks.History at 0x7f875451d580>
検証データセットを使用する
Dataset インスタンスを fit() の validation_data 引数として渡すことができます。
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(train_dataset, epochs=1, validation_data=val_dataset)
782/782 [==============================] - 3s 3ms/step - loss: 0.3333 - sparse_categorical_accuracy: 0.9045 - val_loss: 0.1858 - val_sparse_categorical_accuracy: 0.9448 <keras.callbacks.History at 0x7f875432f9a0>
各エポックの終わりに、モデルは検証データセットを反復処理し、検証損失と検証メトリクスを計算します。
このデータセットから特定の数のバッチでのみ検証を実行する場合は、validation_steps 引数を渡すことができます。これは、検証を中断して次のエポックに進む前に、モデルが検証データセットで実行する必要がある検証ステップの数を指定します。
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(
train_dataset,
epochs=1,
# Only run validation using the first 10 batches of the dataset
# using the `validation_steps` argument
validation_data=val_dataset,
validation_steps=10,
)
782/782 [==============================] - 3s 2ms/step - loss: 0.3495 - sparse_categorical_accuracy: 0.9019 - val_loss: 0.2964 - val_sparse_categorical_accuracy: 0.9203 <keras.callbacks.History at 0x7f875451d760>
検証データセットは使用するたびにリセットされることに注意してください(エポックごとに常に同じサンプルが評価されます)。
validation_split 引数(トレーニングデータからホールドアウトセットを生成)は、Dataset オブジェクトからトレーニングする場合はサポートされません。この機能には、データセットのサンプルにインデックスを付ける機能が必要ですが、一般的に Dataset API では不可能です。
サポートされるほかの入力形式
NumPy 配列、eager tensors、TensorFlow Datasets のほか、Pandas データフレームやデータとラベルのバッチを生成する Python ジェネレータを使用して Keras モデルをトレーニングできます。
特に、keras.utils.Sequence クラスは、Python データジェネレータを構築するためのシンプルなインターフェースを提供します。 これらはマルチプロセッシングに対応し、シャッフルすることができます。
一般的に、以下を使用することをお勧めします。
- NumPy 入力データ - データが小さく、メモリに収まる場合
Datasetオブジェクト - 大規模なデータセットがあり、分散トレーニングを行う必要がある場合Sequenceオブジェクト - 大規模なデータセットがあり、TensorFlow では実行できない多くのカスタム Python 側の処理を行う必要がある場合(たとえば、データの読み込みや前処理が外部ライブラリに依存している場合)。
keras.utils.Sequence オブジェクトを入力として使用する
keras.utils.Sequence は、以下の 2 つの重要な特性を持つ Python ジェネレータを取得するためにサブクラス化できるユーティリティです。
- マルチプロセッシングでうまく機能する
- シャッフル可能(
shuffle=Trueをfit()に渡す場合など)
Sequenceは以下の 2 つのメソッドを実装する必要があります。
__getitem____len__
__getitem__ メソッドは完全なバッチを返します。エポック間でデータセットを変更する場合は、on_epoch_end を実装できます。
簡単な例を次に示します。
from skimage.io import imread
from skimage.transform import resize
import numpy as np
# Here, `filenames` is list of path to the images
# and `labels` are the associated labels.
class CIFAR10Sequence(Sequence):
def __init__(self, filenames, labels, batch_size):
self.filenames, self.labels = filenames, labels
self.batch_size = batch_size
def __len__(self):
return int(np.ceil(len(self.filenames) / float(self.batch_size)))
def __getitem__(self, idx):
batch_x = self.filenames[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_y = self.labels[idx * self.batch_size:(idx + 1) * self.batch_size]
return np.array([
resize(imread(filename), (200, 200))
for filename in batch_x]), np.array(batch_y)
sequence = CIFAR10Sequence(filenames, labels, batch_size)
model.fit(sequence, epochs=10)
サンプルの重み付けとクラスの重み付けを使用する
デフォルト設定ではサンプルの重みはデータセット内の頻度によって決定されますが、サンプルの頻度に関係なくデータに重みを付けるには、以下の 2 つの方法があります。
- クラスの重み
- サンプルの重み
クラスの重み
クラスに対する重みは、ディクショナリを class_weight 引数に渡し、Model.fit()に渡すことで設定されます。このディクショナリは、クラスインデックスを、このクラスに属するサンプルに使用する重みにマッピングします。
これは、リサンプリングせずにクラスのバランスを取るために使用できます。または、特定のクラスをより重要視するモデルをトレーニングするために使用できます。
たとえば、クラス「0」がデータでクラス「1」として表されるものの半分である場合、Model.fit(..., class_weight={0: 1., 1: 0.5}) とすることができます。
以下は NumPy の例です。クラス#5(MNIST データセットの数字「5」)の正しい分類をより重要視するために、クラスの重みまたはサンプルの重みを使用しています。
import numpy as np
class_weight = {
0: 1.0,
1: 1.0,
2: 1.0,
3: 1.0,
4: 1.0,
# Set weight "2" for class "5",
# making this class 2x more important
5: 2.0,
6: 1.0,
7: 1.0,
8: 1.0,
9: 1.0,
}
print("Fit with class weight")
model = get_compiled_model()
model.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epochs=1)
Fit with class weight 782/782 [==============================] - 3s 2ms/step - loss: 0.3683 - sparse_categorical_accuracy: 0.9026 <keras.callbacks.History at 0x7f87540a4eb0>
サンプルの重み
細かく制御する場合、または分類子を構築しない場合は、「サンプルの重み」を使用できます。
- NumPy データからトレーニングする場合:
sample_weight引数をModel.fit()に渡します。 tf.dataまたはその他のイテレータからトレーニングする場合:(input_batch, label_batch, sample_weight_batch)タプルを介します。
「サンプルの重み」配列は、バッチ内の各サンプルが総損失を計算する際に必要な重みを指定する数値の配列です。 これは、不均衡な分類の問題(頻繁に使用されないクラスにより大きな重みを与えるため)でよく使用されます。
使用される重みが 1 と 0 の場合、配列は損失関数のマスクとして使用できます(損失全体に対する特定のサンプルの貢献を完全に破棄します)。
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
print("Fit with sample weight")
model = get_compiled_model()
model.fit(x_train, y_train, sample_weight=sample_weight, batch_size=64, epochs=1)
Fit with sample weight 782/782 [==============================] - 3s 2ms/step - loss: 0.3703 - sparse_categorical_accuracy: 0.9045 <keras.callbacks.History at 0x7f87281034c0>
以下は、一致する Dataset の例です。
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.0
# Create a Dataset that includes sample weights
# (3rd element in the return tuple).
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train, sample_weight))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model = get_compiled_model()
model.fit(train_dataset, epochs=1)
782/782 [==============================] - 2s 2ms/step - loss: 0.3709 - sparse_categorical_accuracy: 0.9019 <keras.callbacks.History at 0x7f86e07615b0>
多入力多出力モデルにデータを渡す
前の例では、1つの入力(テンソルの形状 (764,))と1つの出力(形状の予測テンソル (10,))を持つモデルを見ました。では、複数の入力や出力を持つモデルではどうでしょう。
次のモデルを考えてみましょう。形状 (32, 32, 3) の画像入力(<code data-md-type="codespan">(height, width, channels))、形状 (None, 10) の時系列入力((timesteps, features))があります。モデルは、これらの入力の組み合わせから 2 つの出力(「スコア」(形状(1,))および 5 つのクラスにわたる確率分布(形状(5,))を計算します。
image_input = keras.Input(shape=(32, 32, 3), name="img_input")
timeseries_input = keras.Input(shape=(None, 10), name="ts_input")
x1 = layers.Conv2D(3, 3)(image_input)
x1 = layers.GlobalMaxPooling2D()(x1)
x2 = layers.Conv1D(3, 3)(timeseries_input)
x2 = layers.GlobalMaxPooling1D()(x2)
x = layers.concatenate([x1, x2])
score_output = layers.Dense(1, name="score_output")(x)
class_output = layers.Dense(5, name="class_output")(x)
model = keras.Model(
inputs=[image_input, timeseries_input], outputs=[score_output, class_output]
)
ここで何が行われているか明確に分かるようにこのモデルをプロットしてみましょう(プロットに表示される形状は、サンプルごとの形状ではなく、バッチの形状であることに注意してください)。
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
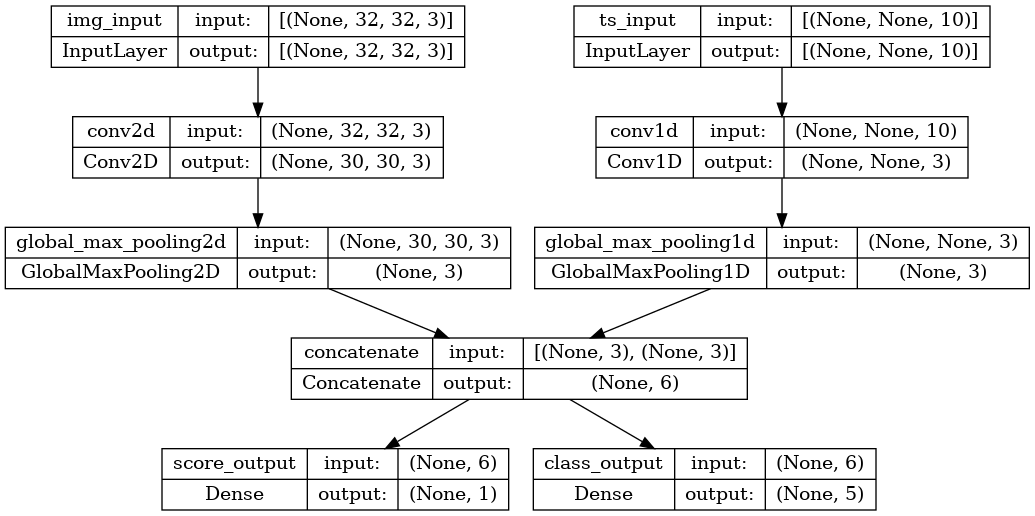
コンパイル時に損失関数をリストとして渡すことにより出力ごとに異なる損失を指定できます。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
モデルに単一の損失関数のみを渡した場合、同じ損失関数がすべての出力に適用されます(ここでは適切ではありません)。
メトリクスの場合も同様です。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
metrics=[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
[keras.metrics.CategoricalAccuracy()],
],
)
出力レイヤーに名前を付けたので、dict を介して出力ごとの損失とメトリクスを指定することもできます。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
)
3 つ以上の出力がある場合は、明示的な名前とディクショナリを使用することをお勧めします。
loss_weights 引数を使用すると、異なる出力固有の損失に異なる重みを与えることができます(この例でクラス損失の 2 倍の重要性を与えることにより、「スコア」損失を優先する場合など)。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"score_output": keras.losses.MeanSquaredError(),
"class_output": keras.losses.CategoricalCrossentropy(),
},
metrics={
"score_output": [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
"class_output": [keras.metrics.CategoricalAccuracy()],
},
loss_weights={"score_output": 2.0, "class_output": 1.0},
)
これらの出力が予測に使用するもので、トレーニングには使用されない場合、特定の出力の損失を計算しないことを選択することもできます。
# List loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[None, keras.losses.CategoricalCrossentropy()],
)
# Or dict loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={"class_output": keras.losses.CategoricalCrossentropy()},
)
fit() で多入力または多出力モデルにデータを渡すと、コンパイルで損失関数を指定するのと同じように機能します。NumPy 配列のリスト(損失関数を受け取った出力に 1:1 でマッピング)または出力の名前を NumPy 配列にマッピングする dict を渡すことができます。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],
)
# Generate dummy NumPy data
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
# Fit on lists
model.fit([img_data, ts_data], [score_targets, class_targets], batch_size=32, epochs=1)
# Alternatively, fit on dicts
model.fit(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
batch_size=32,
epochs=1,
)
4/4 [==============================] - 2s 9ms/step - loss: 17.7520 - score_output_loss: 0.1534 - class_output_loss: 17.5986 4/4 [==============================] - 0s 5ms/step - loss: 17.8890 - score_output_loss: 0.1902 - class_output_loss: 17.6988 <keras.callbacks.History at 0x7f88e4de63d0>
以下は Dataset のユースケースです。NumPy 配列と同様に、Dataset は dicts のタプルを返します。
train_dataset = tf.data.Dataset.from_tensor_slices(
(
{"img_input": img_data, "ts_input": ts_data},
{"score_output": score_targets, "class_output": class_targets},
)
)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=1)
2/2 [==============================] - 0s 19ms/step - loss: 18.1589 - score_output_loss: 0.1828 - class_output_loss: 17.9761 <keras.callbacks.History at 0x7f86e0744f10>
コールバックを使用する
Keras のコールバックは、トレーニング中の異なる時点(エポックの始め、バッチの終わり、エポックの終わりなど)で呼び出されるオブジェクトで、以下のような動作を実装するために使用できます。
- トレーニング中に(組み込みのエポックごとの検証だけでなく)さまざまな時点で検証を行う
- 定期的に、または特定の精度しきい値を超えたときにモデルにチェックポイントを設定する
- 学習が停滞したときにモデルの学習率を変更する
- 学習が停滞したときにトップレイヤーをファインチューニングする
- トレーニング終了時、または特定のパフォーマンスしきい値を超えたときにメールまたはインスタントメッセージ通知を送信する
- など
コールバックは、リストとして fit() の呼び出しに渡すことができます。
model = get_compiled_model()
callbacks = [
keras.callbacks.EarlyStopping(
# Stop training when `val_loss` is no longer improving
monitor="val_loss",
# "no longer improving" being defined as "no better than 1e-2 less"
min_delta=1e-2,
# "no longer improving" being further defined as "for at least 2 epochs"
patience=2,
verbose=1,
)
]
model.fit(
x_train,
y_train,
epochs=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2,
)
Epoch 1/20 625/625 [==============================] - 3s 3ms/step - loss: 0.3721 - sparse_categorical_accuracy: 0.8933 - val_loss: 0.2397 - val_sparse_categorical_accuracy: 0.9269 Epoch 2/20 625/625 [==============================] - 2s 2ms/step - loss: 0.1773 - sparse_categorical_accuracy: 0.9468 - val_loss: 0.1920 - val_sparse_categorical_accuracy: 0.9428 Epoch 3/20 625/625 [==============================] - 2s 2ms/step - loss: 0.1290 - sparse_categorical_accuracy: 0.9617 - val_loss: 0.1583 - val_sparse_categorical_accuracy: 0.9512 Epoch 4/20 625/625 [==============================] - 2s 2ms/step - loss: 0.1009 - sparse_categorical_accuracy: 0.9701 - val_loss: 0.1497 - val_sparse_categorical_accuracy: 0.9561 Epoch 5/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0833 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.1447 - val_sparse_categorical_accuracy: 0.9590 Epoch 6/20 625/625 [==============================] - 2s 3ms/step - loss: 0.0686 - sparse_categorical_accuracy: 0.9790 - val_loss: 0.1383 - val_sparse_categorical_accuracy: 0.9609 Epoch 7/20 625/625 [==============================] - 2s 2ms/step - loss: 0.0588 - sparse_categorical_accuracy: 0.9821 - val_loss: 0.1437 - val_sparse_categorical_accuracy: 0.9604 Epoch 7: early stopping <keras.callbacks.History at 0x7f88e4c9b820>
利用できる多数の組み込みコールバック
Keras には、次のような組み込みコールバックが多数用意されています。
ModelCheckpoint: モデルを定期的に保存するEarlyStopping: トレーニングによって検証指標が改善されなくなったら、トレーニングを停止するTensorBoard: TensorBoard で視覚化できるモデルログを定期的に記述する(詳細については、「視覚化」セクションを参照)。CSVLogger: 損失およびメトリクスデータを CSV ファイルにストリーミングする- など
完全なリストについてはコールバックのドキュメントをご覧ください。
コールバックを記述する
ベースクラス keras.callbacks.Callback を拡張することにより、カスタムコールバックを作成できます。コールバックは、クラスプロパティ self.model を通じて関連するモデルにアクセスできます。
詳細については、カスタムコールバックの作成に関する完全ガイドを参照してください。
以下は、トレーニング時にバッチごとの損失値のリストを保存する簡単な例です。
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.per_batch_losses = []
def on_batch_end(self, batch, logs):
self.per_batch_losses.append(logs.get("loss"))
モデルにチェックポイントを設定する
比較的大きなデータセットでモデルをトレーニングする場合、モデルのチェックポイントを頻繁に保存することが重要です。
これを達成するには ModelCheckpoint コールバックを使用するのが最も簡単です。
model = get_compiled_model()
callbacks = [
keras.callbacks.ModelCheckpoint(
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
# The saved model name will include the current epoch.
filepath="mymodel_{epoch}",
save_best_only=True, # Only save a model if `val_loss` has improved.
monitor="val_loss",
verbose=1,
)
]
model.fit(
x_train, y_train, epochs=2, batch_size=64, callbacks=callbacks, validation_split=0.2
)
Epoch 1/2 623/625 [============================>.] - ETA: 0s - loss: 0.3613 - sparse_categorical_accuracy: 0.8983 Epoch 1: val_loss improved from inf to 0.21801, saving model to mymodel_1 INFO:tensorflow:Assets written to: mymodel_1/assets 625/625 [==============================] - 3s 4ms/step - loss: 0.3613 - sparse_categorical_accuracy: 0.8983 - val_loss: 0.2180 - val_sparse_categorical_accuracy: 0.9356 Epoch 2/2 602/625 [===========================>..] - ETA: 0s - loss: 0.1685 - sparse_categorical_accuracy: 0.9505 Epoch 2: val_loss improved from 0.21801 to 0.17181, saving model to mymodel_2 INFO:tensorflow:Assets written to: mymodel_2/assets 625/625 [==============================] - 2s 3ms/step - loss: 0.1675 - sparse_categorical_accuracy: 0.9507 - val_loss: 0.1718 - val_sparse_categorical_accuracy: 0.9494 <keras.callbacks.History at 0x7f8754504610>
ModelCheckpoint コールバックを使用するとフォールトトレランスを実装できます。フォールトトレランスはトレーニングがランダムに中断された場合に、モデルの最後に保存された状態からトレーニングを再開する機能です。 以下は基本的な例です。
import os
# Prepare a directory to store all the checkpoints.
checkpoint_dir = "./ckpt"
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
def make_or_restore_model():
# Either restore the latest model, or create a fresh one
# if there is no checkpoint available.
checkpoints = [checkpoint_dir + "/" + name for name in os.listdir(checkpoint_dir)]
if checkpoints:
latest_checkpoint = max(checkpoints, key=os.path.getctime)
print("Restoring from", latest_checkpoint)
return keras.models.load_model(latest_checkpoint)
print("Creating a new model")
return get_compiled_model()
model = make_or_restore_model()
callbacks = [
# This callback saves a SavedModel every 100 batches.
# We include the training loss in the saved model name.
keras.callbacks.ModelCheckpoint(
filepath=checkpoint_dir + "/ckpt-loss={loss:.2f}", save_freq=100
)
]
model.fit(x_train, y_train, epochs=1, callbacks=callbacks)
Creating a new model 93/1563 [>.............................] - ETA: 3s - loss: 1.0051 - sparse_categorical_accuracy: 0.7275INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.97/assets 191/1563 [==>...........................] - ETA: 6s - loss: 0.7122 - sparse_categorical_accuracy: 0.8002INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.70/assets 292/1563 [====>.........................] - ETA: 6s - loss: 0.5911 - sparse_categorical_accuracy: 0.8332INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.58/assets 392/1563 [======>.......................] - ETA: 6s - loss: 0.5261 - sparse_categorical_accuracy: 0.8508INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.52/assets 493/1563 [========>.....................] - ETA: 6s - loss: 0.4797 - sparse_categorical_accuracy: 0.8638INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.48/assets 591/1563 [==========>...................] - ETA: 5s - loss: 0.4459 - sparse_categorical_accuracy: 0.8723INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.44/assets 692/1563 [============>.................] - ETA: 5s - loss: 0.4205 - sparse_categorical_accuracy: 0.8794INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.42/assets 791/1563 [==============>...............] - ETA: 4s - loss: 0.3981 - sparse_categorical_accuracy: 0.8861INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.40/assets 893/1563 [================>.............] - ETA: 4s - loss: 0.3781 - sparse_categorical_accuracy: 0.8916INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.38/assets 991/1563 [==================>...........] - ETA: 3s - loss: 0.3646 - sparse_categorical_accuracy: 0.8953INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.36/assets 1090/1563 [===================>..........] - ETA: 3s - loss: 0.3503 - sparse_categorical_accuracy: 0.8997INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.35/assets 1191/1563 [=====================>........] - ETA: 2s - loss: 0.3379 - sparse_categorical_accuracy: 0.9027INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.34/assets 1292/1563 [=======================>......] - ETA: 1s - loss: 0.3256 - sparse_categorical_accuracy: 0.9059INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.32/assets 1392/1563 [=========================>....] - ETA: 1s - loss: 0.3156 - sparse_categorical_accuracy: 0.9088INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.31/assets 1491/1563 [===========================>..] - ETA: 0s - loss: 0.3063 - sparse_categorical_accuracy: 0.9114INFO:tensorflow:Assets written to: ./ckpt/ckpt-loss=0.31/assets 1563/1563 [==============================] - 11s 6ms/step - loss: 0.3004 - sparse_categorical_accuracy: 0.9132 <keras.callbacks.History at 0x7f88e4a2af70>
また、モデルを保存および復元するための独自のコールバックを記述することもできます。
シリアル化と保存の完全なガイドについては、モデルの保存とシリアル化に関するガイドをご覧ください。
学習率スケジュールを使用する
ディープラーニングモデルをトレーニングする際は、一般的に、トレーニングが進むにつれて徐々に学習進度が減少するパターンが見られます。これは一般に「学習率の減衰」として知られています。
学習減衰スケジュールは、静的(その時点のエポックまたはその時点のバッチインデックスの関数として事前に指定)または動的(モデルの現在の動作、特に検証損失に対応)にすることができます。
オプティマイザにスケジュールを渡す
オプティマイザの learning_rate 引数としてスケジュールオブジェクトを渡すことで、静的学習率の減衰スケジュールを簡単に使用できます。
initial_learning_rate = 0.1
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, decay_steps=100000, decay_rate=0.96, staircase=True
)
optimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)
組み込みスケジュールには、ExponentialDecay、PiecewiseConstantDecay、PolynomialDecay、および InverseTimeDecay を利用できます。
コールバックを使用して動的学習率スケジュールを実装する
オプティマイザは検証メトリクスにアクセスできないため、これらのスケジュールオブジェクトでは動的学習率のスケジュール(検証の損失が改善されなくなったときに学習率を下げるなど)を実現できません。
ただし、コールバックは、検証メトリクスを含むすべてのメトリクスにアクセスできます。このパターンでは、コールバックを使用してオプティマイザのその時点の学習率を変更します。これはReduceLROnPlateau コールバックとして組み込まれています。
トレーニング時の損失とメトリクスを視覚化する
トレーニング時にモデルを監視する場合、TensorBoard を使用するのが最善の方法です。これは、ローカルで実行できるブラウザベースのアプリケーションで、以下の機能を提供します。
- トレーニングと評価のための損失とメトリクスのライブプロット
- レイヤーアクティベーションのヒストグラムの視覚化(オプション)
Embeddingレイヤーが学習した埋め込みスペースの 3D 視覚化(オプション)
TensorFlow を pip でインストールした場合は、コマンドラインから TensorBoard を起動できます。
tensorboard --logdir=/full_path_to_your_logs
TensorBoard コールバックを使用する
Keras モデルと fit() メソッドで TensorBoard を使用するには、TensorBoard コールバックを使用するのが最も簡単です。
最も単純なケースでは、コールバックがログを書き込む場所を指定するだけで完了します。
keras.callbacks.TensorBoard(
log_dir="/full_path_to_your_logs",
histogram_freq=0, # How often to log histogram visualizations
embeddings_freq=0, # How often to log embedding visualizations
update_freq="epoch",
) # How often to write logs (default: once per epoch)
<keras.callbacks.TensorBoard at 0x7f881fc75400>
詳細については、TensorBoardコールバックのドキュメントを参照してください。