
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই নির্দেশিকাটি TensorFlow বেসিকগুলির একটি দ্রুত ওভারভিউ প্রদান করে। এই ডকটির প্রতিটি বিভাগ একটি বৃহত্তর বিষয়ের একটি ওভারভিউ - আপনি প্রতিটি বিভাগের শেষে সম্পূর্ণ গাইডের লিঙ্ক খুঁজে পেতে পারেন।
TensorFlow হল মেশিন লার্নিং এর জন্য এন্ড-টু-এন্ড প্ল্যাটফর্ম। এটি নিম্নলিখিত সমর্থন করে:
- বহুমাত্রিক-অ্যারে ভিত্তিক সাংখ্যিক গণনা ( NumPy এর অনুরূপ।)
- GPU এবং বিতরণ প্রক্রিয়াকরণ
- স্বয়ংক্রিয় পার্থক্য
- মডেল নির্মাণ, প্রশিক্ষণ, এবং রপ্তানি
- এবং আরো
টেনসর
TensorFlow বহুমাত্রিক অ্যারে বা tf.Tensor অবজেক্ট হিসাবে tf.Tensor উপর কাজ করে। এখানে একটি দ্বি-মাত্রিক টেনসর রয়েছে:
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
tf.Tensor( [[1. 2. 3.] [4. 5. 6.]], shape=(2, 3), dtype=float32) (2, 3) <dtype: 'float32'>
একটি tf.Tensor এর সবচেয়ে গুরুত্বপূর্ণ বৈশিষ্ট্য হল এর shape এবং dtype :
-
Tensor.shape: আপনাকে তার প্রতিটি অক্ষ বরাবর টেনসরের আকার বলে। -
Tensor.dtype: আপনাকে টেনসরের সমস্ত উপাদানের ধরন বলে।
টেনসরফ্লো টেনসরগুলিতে স্ট্যান্ডার্ড গাণিতিক ক্রিয়াকলাপ প্রয়োগ করে, সেইসাথে মেশিন শেখার জন্য বিশেষায়িত অনেকগুলি অপারেশন।
উদাহরণ স্বরূপ:
x + x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 8., 10., 12.]], dtype=float32)>
5 * x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 5., 10., 15.],
[20., 25., 30.]], dtype=float32)>
x @ tf.transpose(x)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
tf.concat([x, x, x], axis=0)
<tf.Tensor: shape=(6, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
tf.nn.softmax(x, axis=-1)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.09003057, 0.24472848, 0.6652409 ],
[0.09003057, 0.24472848, 0.6652409 ]], dtype=float32)>
tf.reduce_sum(x)
<tf.Tensor: shape=(), dtype=float32, numpy=21.0>
CPU-তে বড় গণনা চালানো ধীর হতে পারে। সঠিকভাবে কনফিগার করা হলে, TensorFlow খুব দ্রুত অপারেশন চালানোর জন্য GPU-এর মতো এক্সিলারেটর হার্ডওয়্যার ব্যবহার করতে পারে।
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
TensorFlow **IS** using the GPU
বিস্তারিত জানার জন্য টেনসর নির্দেশিকা পড়ুন।
ভেরিয়েবল
সাধারণ tf. tf.Tensor বস্তু অপরিবর্তনীয়। টেনসরফ্লোতে মডেলের ওজন (বা অন্য পরিবর্তনযোগ্য অবস্থা) সংরক্ষণ করতে একটি tf.Variable ব্যবহার করুন।
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>
var.assign_add([1, 1, 1])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([2., 3., 4.], dtype=float32)>
বিস্তারিত জানার জন্য ভেরিয়েবল গাইড পড়ুন।
স্বয়ংক্রিয় পার্থক্য
গ্রেডিয়েন্ট ডিসেন্ট এবং সম্পর্কিত অ্যালগরিদম হল আধুনিক মেশিন লার্নিং এর মূল ভিত্তি।
এটি সক্ষম করার জন্য, TensorFlow স্বয়ংক্রিয় পার্থক্য (অটোডিফ) প্রয়োগ করে, যা গ্রেডিয়েন্ট গণনা করতে ক্যালকুলাস ব্যবহার করে। সাধারণত আপনি এটির ওজনের ক্ষেত্রে মডেলের ত্রুটি বা ক্ষতির গ্রেডিয়েন্ট গণনা করতে এটি ব্যবহার করবেন।
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
<tf.Tensor: shape=(), dtype=float32, numpy=-2.0>
x = 1.0 এ , y = f(x) = (1**2 + 3 - 5) = -2 ।
y এর ডেরিভেটিভ হল y y' = f'(x) = (2*x + 2) = 4 । TensorFlow এটি স্বয়ংক্রিয়ভাবে গণনা করতে পারে:
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
এই সরলীকৃত উদাহরণটি শুধুমাত্র একটি একক স্কেলার ( x ) এর সাপেক্ষে ডেরিভেটিভ গ্রহণ করে, কিন্তু TensorFlow একই সাথে যেকোনো সংখ্যক নন-স্কেলার টেনসরের সাপেক্ষে গ্রেডিয়েন্ট গণনা করতে পারে।
বিস্তারিত জানার জন্য অটোডিফ গাইড পড়ুন।
গ্রাফ এবং tf.ফাংশন
আপনি যে কোনো পাইথন লাইব্রেরির মতো ইন্টারেক্টিভভাবে TensorFlow ব্যবহার করতে পারেন, TensorFlow এর জন্য টুলও প্রদান করে:
- কর্মক্ষমতা অপ্টিমাইজেশান : প্রশিক্ষণ এবং অনুমান গতি বাড়ানোর জন্য।
- রপ্তানি করুন: যাতে প্রশিক্ষণ শেষ হলে আপনি আপনার মডেলটি সংরক্ষণ করতে পারেন।
এর জন্য আপনাকে পাইথন থেকে আপনার বিশুদ্ধ-টেনসরফ্লো কোড আলাদা করতে tf.function ব্যবহার করতে হবে।
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
প্রথমবার আপনি tf.function , যদিও এটি Python-এ কার্যকর হয়, এটি একটি সম্পূর্ণ, অপ্টিমাইজ করা গ্রাফ ক্যাপচার করে যা ফাংশনের মধ্যে করা TensorFlow গণনাকে উপস্থাপন করে।
x = tf.constant([1, 2, 3])
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=int32, numpy=6>
পরবর্তী কলগুলিতে TensorFlow শুধুমাত্র অপ্টিমাইজ করা গ্রাফটি সম্পাদন করে, যেকোন নন-টেনসরফ্লো ধাপগুলি এড়িয়ে যায়। নীচে, নোট করুন যে my_func ট্রেসিং প্রিন্ট করে না যেহেতু print একটি পাইথন ফাংশন, টেনসরফ্লো ফাংশন নয়।
x = tf.constant([10, 9, 8])
my_func(x)
<tf.Tensor: shape=(), dtype=int32, numpy=27>
একটি ভিন্ন স্বাক্ষর ( shape এবং dtype ) সহ ইনপুটগুলির জন্য একটি গ্রাফ পুনরায় ব্যবহারযোগ্য নাও হতে পারে, তাই পরিবর্তে একটি নতুন গ্রাফ তৈরি করা হয়েছে:
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=float32, numpy=27.3>
এই ক্যাপচার করা গ্রাফ দুটি সুবিধা প্রদান করে:
- অনেক ক্ষেত্রে তারা মৃত্যুদন্ড কার্যকর করার ক্ষেত্রে একটি উল্লেখযোগ্য গতি প্রদান করে (যদিও এই তুচ্ছ উদাহরণ নয়)।
- আপনি সার্ভার বা মোবাইল ডিভাইসের মতো অন্যান্য সিস্টেমে চালানোর জন্য
tf.saved_modelব্যবহার করে এই গ্রাফগুলি রপ্তানি করতে পারেন, পাইথন ইনস্টলেশনের প্রয়োজন নেই।
আরো বিস্তারিত জানার জন্য গ্রাফের ভূমিকা পড়ুন।
মডিউল, স্তর, এবং মডেল
tf.Module হল আপনার tf.Variable অবজেক্ট এবং tf.function অবজেক্টগুলি পরিচালনা করার জন্য একটি ক্লাস যা তাদের উপর কাজ করে। tf.Module ক্লাস দুটি উল্লেখযোগ্য বৈশিষ্ট্য সমর্থন করার জন্য প্রয়োজনীয়:
- আপনি
tf.train.Checkpointব্যবহার করে আপনার ভেরিয়েবলের মান সংরক্ষণ এবং পুনরুদ্ধার করতে পারেন। এটি প্রশিক্ষণের সময় দরকারী কারণ এটি একটি মডেলের অবস্থা সংরক্ষণ এবং পুনরুদ্ধার করতে দ্রুত। - আপনি
tf.saved_modelব্যবহার করেtf.Variableমান এবংtf.functionগ্রাফ আমদানি এবং রপ্তানি করতে পারেন। এটি আপনাকে পাইথন প্রোগ্রাম থেকে স্বাধীনভাবে আপনার মডেল চালানোর অনুমতি দেয় যা এটি তৈরি করেছে।
এখানে একটি সাধারণ tf.Module অবজেক্ট এক্সপোর্ট করার একটি সম্পূর্ণ উদাহরণ রয়েছে:
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Module সংরক্ষণ করুন:
save_path = './saved'
tf.saved_model.save(mod, save_path)
INFO:tensorflow:Assets written to: ./saved/assets 2021-12-08 17:13:16.021805: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
ফলে সংরক্ষিত মডেলটি যে কোডটি তৈরি করেছে তার থেকে স্বাধীন। আপনি পাইথন, অন্যান্য ভাষার বাইন্ডিং বা টেনসরফ্লো সার্ভিং থেকে একটি সংরক্ষিত মডেল লোড করতে পারেন। আপনি এটিকে টেনসরফ্লো লাইট বা টেনসরফ্লো জেএস -এর সাথে চালানোর জন্য রূপান্তর করতে পারেন।
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
tf.keras.layers.Layer এবং tf.keras.Model ক্লাসগুলি tf.Module এর উপর তৈরি করে যা মডেল তৈরি, প্রশিক্ষণ এবং সংরক্ষণের জন্য অতিরিক্ত কার্যকারিতা এবং সুবিধার পদ্ধতি প্রদান করে। এর মধ্যে কয়েকটি পরবর্তী বিভাগে প্রদর্শিত হয়।
বিস্তারিত জানার জন্য মডিউলের ভূমিকা পড়ুন।
প্রশিক্ষণ loops
এখন একটি মৌলিক মডেল তৈরি করতে এবং এটিকে স্ক্র্যাচ থেকে প্রশিক্ষিত করতে এই সব একসাথে রাখুন।
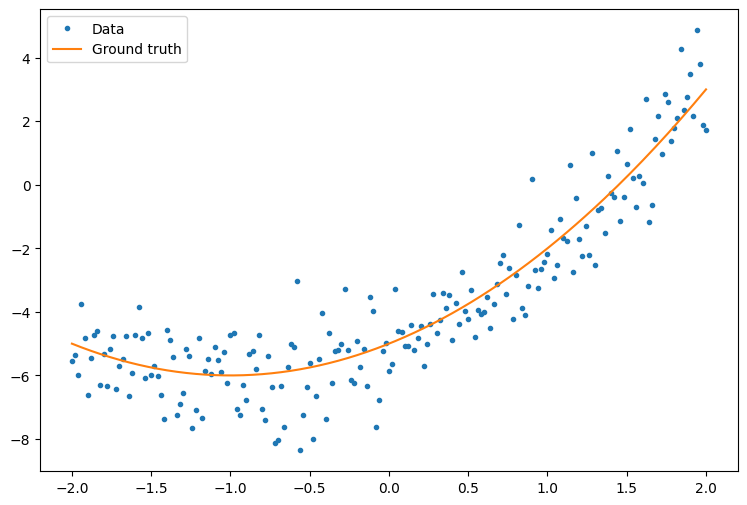
প্রথমত, কিছু উদাহরণ ডেটা তৈরি করুন। এটি বিন্দুগুলির একটি মেঘ তৈরি করে যা আলগাভাবে একটি চতুর্মুখী বক্ররেখা অনুসরণ করে:
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
একটি মডেল তৈরি করুন:
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();

একটি মৌলিক প্রশিক্ষণ লুপ লিখুন:
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
Mean squared error: 19.473 Mean squared error: 1.140 Mean squared error: 1.130 Mean squared error: 1.124 Mean squared error: 1.121 Mean squared error: 1.120 Mean squared error: 1.119 Mean squared error: 1.118 Mean squared error: 1.118 Mean squared error: 1.117
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
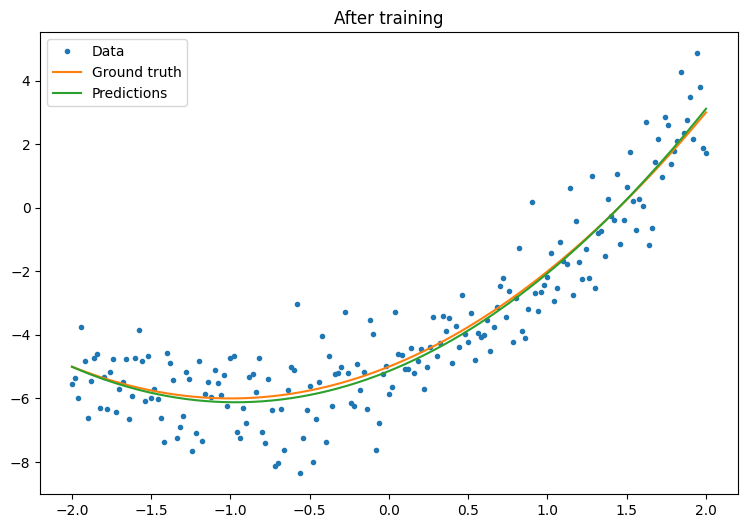
এটি কাজ করছে, কিন্তু মনে রাখবেন যে সাধারণ প্রশিক্ষণ ইউটিলিটিগুলির বাস্তবায়ন tf.keras মডিউলে উপলব্ধ। তাই আপনার নিজের লেখার আগে সেগুলি ব্যবহার করার কথা বিবেচনা করুন। শুরু করার জন্য, Model.compile এবং Model.fit পদ্ধতিগুলি আপনার জন্য একটি প্রশিক্ষণ লুপ প্রয়োগ করে:
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
INFO:tensorflow:Assets written to: ./my_model/assets
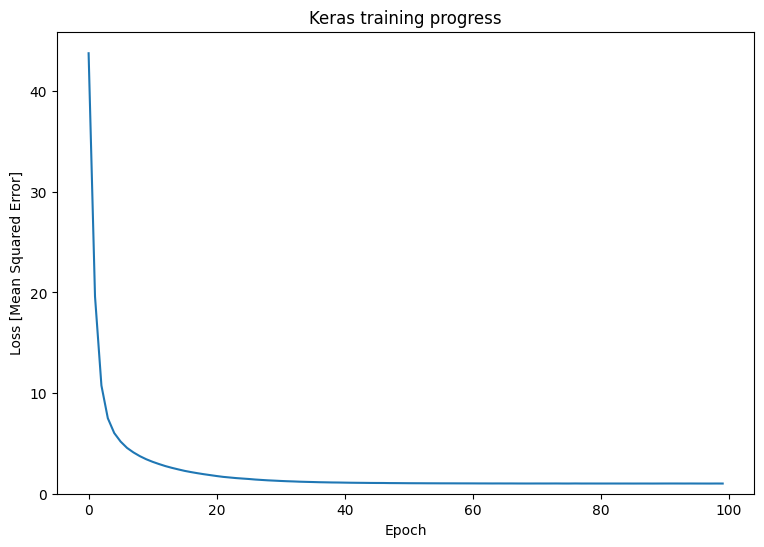
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
আরো বিস্তারিত জানার জন্য বেসিক ট্রেনিং লুপ এবং কেরাস গাইড পড়ুন।