
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह मार्गदर्शिका TensorFlow की बुनियादी बातों का त्वरित अवलोकन प्रदान करती है। इस दस्तावेज़ का प्रत्येक अनुभाग एक बड़े विषय का अवलोकन है—आप प्रत्येक अनुभाग के अंत में संपूर्ण मार्गदर्शिकाओं के लिंक पा सकते हैं।
TensorFlow मशीन लर्निंग के लिए एंड-टू-एंड प्लेटफॉर्म है। यह निम्नलिखित का समर्थन करता है:
- बहुआयामी-सरणी आधारित संख्यात्मक गणना ( NumPy के समान।)
- GPU और वितरित प्रसंस्करण
- स्वचालित भेदभाव
- मॉडल निर्माण, प्रशिक्षण और निर्यात
- और अधिक
टेंसर
TensorFlow बहुआयामी सरणियों या tf.Tensor वस्तुओं के रूप में प्रदर्शित टेंसर पर काम करता है। यहाँ एक द्वि-आयामी टेंसर है:
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
tf.Tensor( [[1. 2. 3.] [4. 5. 6.]], shape=(2, 3), dtype=float32) (2, 3) <dtype: 'float32'>
एक tf.Tensor की सबसे महत्वपूर्ण विशेषताएँ इसकी shape और dtype हैं:
-
Tensor.shape: आपको इसके प्रत्येक अक्ष के साथ टेंसर का आकार बताता है। -
Tensor.dtype: आपको टेंसर में सभी तत्वों का प्रकार बताता है।
TensorFlow टेंसर पर मानक गणितीय संचालन को लागू करता है, साथ ही मशीन सीखने के लिए विशेषीकृत कई ऑपरेशन भी करता है।
उदाहरण के लिए:
x + x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 8., 10., 12.]], dtype=float32)>
5 * x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 5., 10., 15.],
[20., 25., 30.]], dtype=float32)>
x @ tf.transpose(x)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
tf.concat([x, x, x], axis=0)
<tf.Tensor: shape=(6, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
10 l10n-tf.nn.softmax(x, axis=-1)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.09003057, 0.24472848, 0.6652409 ],
[0.09003057, 0.24472848, 0.6652409 ]], dtype=float32)>
tf.reduce_sum(x)
<tf.Tensor: shape=(), dtype=float32, numpy=21.0>
सीपीयू पर बड़ी गणना चलाना धीमा हो सकता है। जब ठीक से कॉन्फ़िगर किया जाता है, तो TensorFlow संचालन को बहुत तेज़ी से निष्पादित करने के लिए GPU जैसे त्वरक हार्डवेयर का उपयोग कर सकता है।
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
TensorFlow **IS** using the GPU
विवरण के लिए टेंसर गाइड देखें।
चर
सामान्य tf.Tensor ऑब्जेक्ट अपरिवर्तनीय हैं। TensorFlow में मॉडल वेट (या अन्य परिवर्तनशील अवस्था) को स्टोर करने के लिए tf.Variable का उपयोग करें।
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>
var.assign_add([1, 1, 1])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([2., 3., 4.], dtype=float32)>
विवरण के लिए चर मार्गदर्शिका देखें।
स्वचालित भेदभाव
ग्रेडिएंट डिसेंट और संबंधित एल्गोरिदम आधुनिक मशीन लर्निंग की आधारशिला हैं।
इसे सक्षम करने के लिए, TensorFlow स्वचालित विभेदन (ऑटोडिफ़) को लागू करता है, जो ग्रेडिएंट की गणना करने के लिए कैलकुलस का उपयोग करता है। आम तौर पर आप इसका उपयोग किसी मॉडल की त्रुटि या उसके वजन के संबंध में हानि के ढाल की गणना के लिए करेंगे।
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
<tf.Tensor: shape=(), dtype=float32, numpy=-2.0>
x = 1.0 पर, y = f(x) = (1**2 + 2*1 - 5) = -2 ।
y का अवकलज y' = f'(x) = (2*x + 2) = 4 है। TensorFlow स्वचालित रूप से इसकी गणना कर सकता है:
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>प्लेसहोल्डर26
यह सरलीकृत उदाहरण केवल एक स्केलर ( x ) के संबंध में व्युत्पन्न लेता है, लेकिन TensorFlow किसी भी संख्या में गैर-स्केलर टेंसर के संबंध में एक साथ ग्रेडिएंट की गणना कर सकता है।
विवरण के लिए ऑटोडिफ गाइड देखें।
रेखांकन और tf.function
जबकि आप TensorFlow का उपयोग किसी भी Python लाइब्रेरी की तरह अंतःक्रियात्मक रूप से कर सकते हैं, TensorFlow इसके लिए उपकरण भी प्रदान करता है:
- प्रदर्शन अनुकूलन : प्रशिक्षण और अनुमान में तेजी लाने के लिए।
- निर्यात : ताकि प्रशिक्षण पूरा होने पर आप अपने मॉडल को सहेज सकें।
इसके लिए आवश्यक है कि आप अपने शुद्ध-टेन्सरफ्लो कोड को पायथन से अलग करने के लिए tf.function का उपयोग करें।
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
पहली बार जब आप tf.function चलाते हैं, हालांकि यह पायथन में निष्पादित होता है, यह फ़ंक्शन के भीतर किए गए TensorFlow संगणनाओं का प्रतिनिधित्व करने वाला एक पूर्ण, अनुकूलित ग्राफ़ कैप्चर करता है।
x = tf.constant([1, 2, 3])
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=int32, numpy=6>
बाद की कॉल पर TensorFlow केवल अनुकूलित ग्राफ़ निष्पादित करता है, किसी भी गैर-TensorFlow चरणों को छोड़ देता है। नीचे, ध्यान दें कि my_func ट्रेसिंग प्रिंट नहीं करता है क्योंकि print एक पायथन फ़ंक्शन है, न कि TensorFlow फ़ंक्शन।
x = tf.constant([10, 9, 8])
my_func(x)
<tf.Tensor: shape=(), dtype=int32, numpy=27>
भिन्न हस्ताक्षर ( shape और dtype ) के साथ इनपुट के लिए एक ग्राफ पुन: प्रयोज्य नहीं हो सकता है, इसलिए इसके बजाय एक नया ग्राफ उत्पन्न होता है:
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=float32, numpy=27.3>प्लेसहोल्डर33
ये कैप्चर किए गए ग्राफ़ दो लाभ प्रदान करते हैं:
- कई मामलों में वे निष्पादन में एक महत्वपूर्ण गति प्रदान करते हैं (हालांकि यह मामूली उदाहरण नहीं है)।
- सर्वर या मोबाइल डिवाइस जैसे अन्य सिस्टम पर चलाने के लिए आप
tf.saved_modelका उपयोग करके इन ग्राफ़ को निर्यात कर सकते हैं, इसके लिए किसी पायथन इंस्टॉलेशन की आवश्यकता नहीं है।
अधिक विवरण के लिए ग्राफ़ का परिचय देखें।
मॉड्यूल, परतें और मॉडल
tf.Module आपके tf.Variable ऑब्जेक्ट्स और उन पर काम करने वाले tf.function ऑब्जेक्ट्स को प्रबंधित करने के लिए एक वर्ग है। दो महत्वपूर्ण विशेषताओं का समर्थन करने के लिए tf.Module वर्ग आवश्यक है:
- आप
tf.train.Checkpointका उपयोग करके अपने चर के मूल्यों को सहेज और पुनर्स्थापित कर सकते हैं। यह प्रशिक्षण के दौरान उपयोगी है क्योंकि यह मॉडल की स्थिति को सहेजना और पुनर्स्थापित करना त्वरित है। - आप
tf.saved_modelका उपयोग करकेtf.Variableमान औरtf.functionग्राफ़ आयात और निर्यात कर सकते हैं। यह आपको अपने मॉडल को पायथन प्रोग्राम से स्वतंत्र रूप से चलाने की अनुमति देता है जिसने इसे बनाया है।
यहाँ एक साधारण tf.Module वस्तु निर्यात करने का एक पूरा उदाहरण है:
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Module सहेजें:
save_path = './saved'
tf.saved_model.save(mod, save_path)
INFO:tensorflow:Assets written to: ./saved/assets 2022-01-19 02:29:48.135588: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
परिणामी सहेजा गया मॉडल उस कोड से स्वतंत्र है जिसने इसे बनाया है। आप Python, अन्य भाषा बाइंडिंग, या TensorFlow Serving से एक SavedModel लोड कर सकते हैं। आप इसे TensorFlow Lite या TensorFlow JS के साथ चलाने के लिए रूपांतरित भी कर सकते हैं।
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
tf.keras.layers.Layer और tf.keras.Model कक्षाएं tf.Module पर निर्मित होती हैं जो मॉडल बनाने, प्रशिक्षण और सहेजने के लिए अतिरिक्त कार्यक्षमता और सुविधा विधियां प्रदान करती हैं। इनमें से कुछ को अगले भाग में प्रदर्शित किया गया है।
विवरण के लिए मॉड्यूल का परिचय देखें।
प्रशिक्षण लूप
अब एक बुनियादी मॉडल बनाने और इसे शुरू से प्रशिक्षित करने के लिए इन सभी को एक साथ रखें।
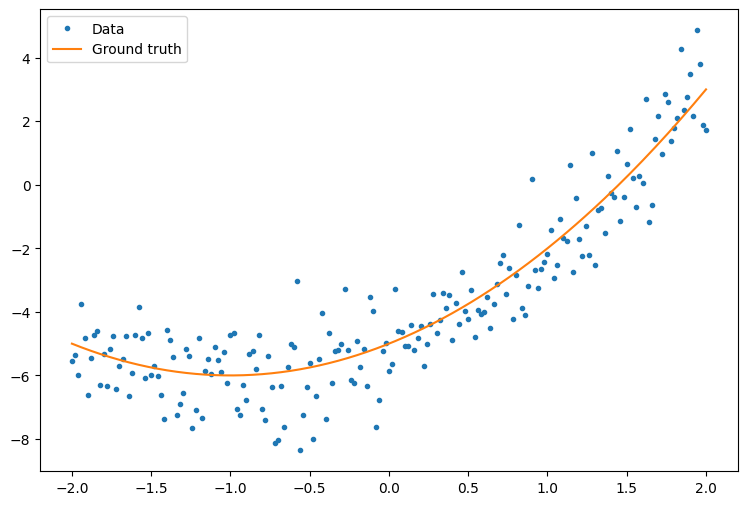
सबसे पहले, कुछ उदाहरण डेटा बनाएं। यह बिंदुओं का एक बादल उत्पन्न करता है जो शिथिल रूप से द्विघात वक्र का अनुसरण करता है:
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
एक मॉडल बनाएं:
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();

एक बुनियादी प्रशिक्षण लूप लिखें:
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
Mean squared error: 16.123 Mean squared error: 0.997 Mean squared error: 0.964 Mean squared error: 0.946 Mean squared error: 0.932 Mean squared error: 0.921 Mean squared error: 0.913 Mean squared error: 0.907 Mean squared error: 0.901 Mean squared error: 0.897
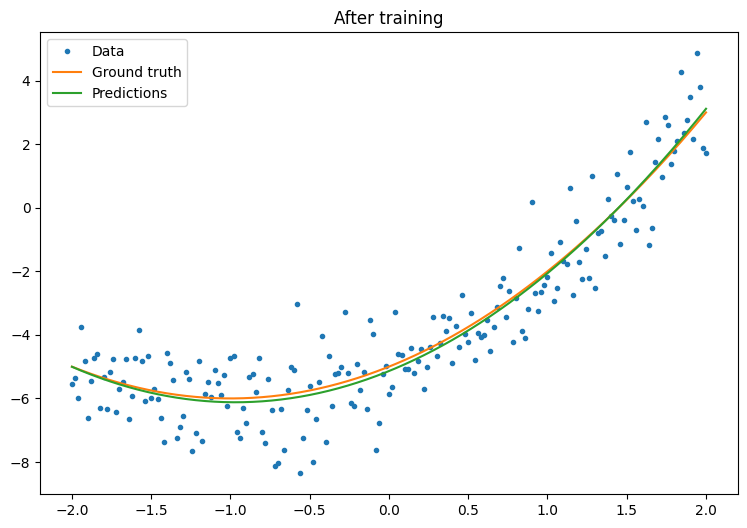
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
यह काम कर रहा है, लेकिन याद रखें कि सामान्य प्रशिक्षण उपयोगिताओं के कार्यान्वयन tf.keras मॉड्यूल में उपलब्ध हैं। इसलिए अपना खुद का लिखने से पहले उनका उपयोग करने पर विचार करें। शुरू करने के लिए, Model.compile और Model.fit विधियां आपके लिए एक प्रशिक्षण लूप लागू करती हैं:
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
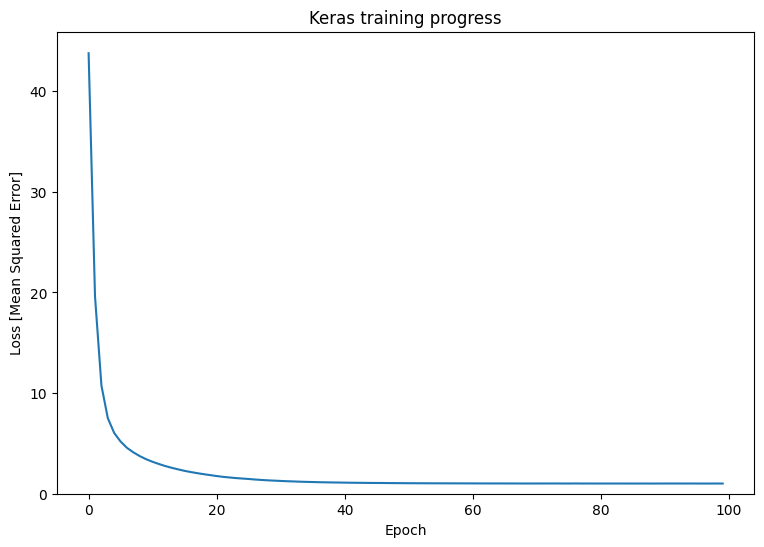
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
INFO:tensorflow:Assets written to: ./my_model/assets
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
अधिक जानकारी के लिए बेसिक ट्रेनिंग लूप और केरस गाइड देखें।