
| |
|
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
Overview
이 Colab에서는 동기식 분산 컴퓨팅을 지원하며 TensorFlow의 확장 버전인 DTensor를 소개합니다.
DTensor는 개발자가 내부에서 장치 전반의 배포를 관리하면서 글로벌적으로 텐서에서 작동하는 애플리케이션을 구성할 수 있도록 하는 글로벌 프로그래밍 모델을 제공합니다. DTensor는 분할 지시문에 따라 단일 프로그램 다중데이터(SPMD) 확장이라는 절차를 통해 프로그램과 텐서를 배포합니다
분할 지시문으로부터 애플리케이션을 분리함으로써 DTensor는 글로벌 의미 체계를 유지하면서도 단일 장치, 여러 장치 또는 여러 클라이언트에서 동일한 애플리케이션을 실행할 수 있습니다.
이 가이드에서는 분산 컴퓨팅을 위한 DTensor 개념과 DTensor가 TensorFlow와 통합되는 방식을 소개합니다. 모델 훈련에서 DTensor를 사용하는 데모를 확인하려면 DTensor를 사용한 분산 훈련 튜토리얼을 참조합니다.
설치하기
DTensor는 TensorFlow 2.9.0 릴리스의 일부이며 2022년 4월 9일부터 TensorFlow 나이틀리 빌드에도 포함되어 있습니다.
pip install --quiet --upgrade --pre tensorflow설치가 완료되면 tensorflow 및 tf.experimental.dtensor를 가져옵니다. 그런 다음 6개의 가상 CPU를 사용하도록 TensorFlow를 구성합니다.
이 예제에서는 vCPU를 사용하지만 DTensor는 CPU, GPU 또는 TPU 장치에서 동일한 방식으로 작동합니다.
import tensorflow as tf
from tensorflow.experimental import dtensor
print('TensorFlow version:', tf.__version__)
def configure_virtual_cpus(ncpu):
phy_devices = tf.config.list_physical_devices('CPU')
tf.config.set_logical_device_configuration(phy_devices[0], [
tf.config.LogicalDeviceConfiguration(),
] * ncpu)
configure_virtual_cpus(6)
DEVICES = [f'CPU:{i}' for i in range(6)]
tf.config.list_logical_devices('CPU')
2022-12-14 21:20:31.843068: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:20:31.843170: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:20:31.843179: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. TensorFlow version: 2.11.0 [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:CPU:1', device_type='CPU'), LogicalDevice(name='/device:CPU:2', device_type='CPU'), LogicalDevice(name='/device:CPU:3', device_type='CPU'), LogicalDevice(name='/device:CPU:4', device_type='CPU'), LogicalDevice(name='/device:CPU:5', device_type='CPU')]
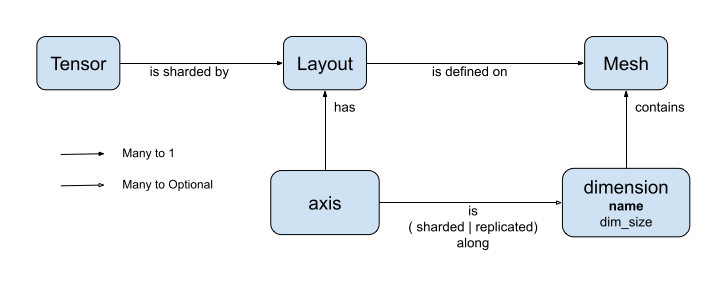
DTensor의 분산 텐서 모델
DTensor는 dtensor.Mesh 및 dtensor.Layout이라는 두 가지 개념을 소개합니다. 이는 토폴로지와 관련된 장치에서 텐서의 분할을 모델링하는 추상화입니다.
Mesh는 컴퓨팅용 장치 목록을 정의합니다.Layout은Mesh의 텐서 차원을 분할하는 방식을 정의합니다.
메시(Mesh)
Mesh는 장치 세트의 논리적 데카르트 토폴로지를 나타냅니다. 데카르트 그리드의 각 차원은 메시 차원이라고 하며 이름으로 참조합니다. 동일한 Mesh 내 메시 차원의 이름은 고유해야 합니다.
메시 차원의 이름은 각 축을 따라 tf.Tensor의 분할 동작을 설명할 수 있도록 Layout을 통해 참조됩니다. 이는 나중에 Layout 섹션에서 자세히 설명합니다.
Mesh는 장치의 다차원 배열로 생각할 수도 있습니다.
1차원 Mesh에서는 모든 장치가 단일 메시 차원으로 목록을 형성합니다. 다음 예제에서는 6개 장치를 사용하는 'x' 메시 차원에 따라 dtensor.create_mesh를 사용하여 메시를 생성합니다.
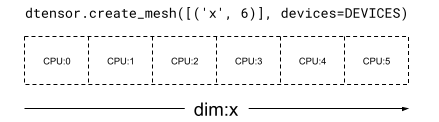
mesh_1d = dtensor.create_mesh([('x', 6)], devices=DEVICES)
print(mesh_1d)
<Mesh object with dims=[('x', 6)], device_type="CPU", num_local_devices=6), size=6>
Mesh는 다차원일 수도 있습니다. 다음 예제에서 6개의 CPU 장치는 3x2 메시를 형성합니다. 여기에서 'x' 메시 차원은 3개 장치의 크기를 가지며 'y'{ /code3} 메시 차원은 2개 장치의 크기를 갖습니다.
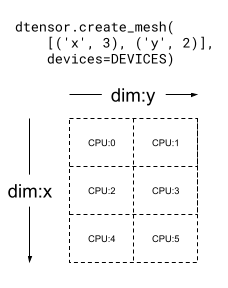
mesh_2d = dtensor.create_mesh([('x', 3), ('y', 2)], devices=DEVICES)
print(mesh_2d)
<Mesh object with dims=[('x', 3), ('y', 2)], device_type="CPU", num_local_devices=6), size=6>
레이아웃(Layout)
Layout은 텐서가 Mesh에서 분산 또는 분할되는 방식을 지정합니다.
참고: Mesh와 Layout 사이의 혼란을 피하기 위해 이 가이드에서 차원(dimension)이라는 용어는 항상 Mesh와 연결하여 사용하고 축(axis)라는 용어는 Tensor 및 Layout과 함께 사용합니다.
Layout의 순위는 Layout이 적용된 Tensor의 순위와 같아야 합니다. Tensor의 각 축에 대해 Layout은 텐서를 분할할 메시 차원을 지정하거나 축을 '분할하지 않음'으로 지정할 수 있습니다. 텐서는 분할되지 않은 모든 메시 차원에 복제됩니다.
Layout의 순위와 Mesh의 차원 수는 일치하지 않아도 됩니다. Layout의 unsharded 축은 메시 차원과 연결할 필요가 없으며 unsharded 메시 차원은 layout 축과 연결할 필요가 없습니다.
이전 섹션에서 생성한 Mesh에 대한 Layout의 몇 가지 예제를 분석해 보겠습니다.
[("x", 6)]와 같은 1차원 메시(이전 섹션의 mesh_1d)에서 Layout(["unsharded", "unsharded"], mesh_1d)는 6개의 장치에 복제된 2순위 텐서의 레이아웃입니다. 
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh_1d)
동일한 텐서를 사용하고 Layout(['unsharded', 'x']) 레이아웃을 메시하면 6개의 장치에서 텐서의 두 번째 축이 분할될 수 있습니다.
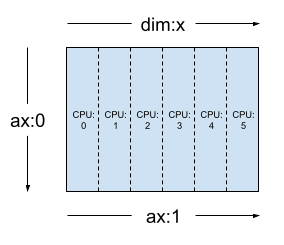
layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh_1d)
[("x", 3), ("y", 2)](이전 섹션의 mesh_2d)와 같은 2차원의 3x2 메시가 주어질 경우 { code2}Layout(["y", "x"], mesh_2d)는 첫 번째 축이 메시 차원 "y"에 걸쳐 샤딩되는 2순위 Tensor의 레이아웃이며 두 번째 축은 메시 차원 "x"에 걸쳐 샤딩됩니다.
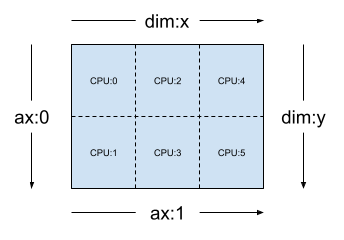
layout = dtensor.Layout(['y', 'x'], mesh_2d)
동일한 mesh_2d의 경우 레이아웃 Layout(["x", dtensor.UNSHARDED], mesh_2d)은 2순위 Tensor이며, 이는 "y"에 복제되고 첫 번째 축이 메시 차원 x에서 분할됩니다.
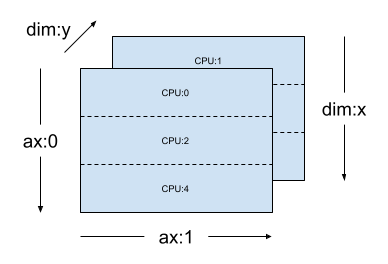
layout = dtensor.Layout(["x", dtensor.UNSHARDED], mesh_2d)
단일 클라이언트 및 멀티 클라이언트 애플리케이션
DTensor는 단일 클라이언트 및 멀티 클라이언트 애플리케이션을 모두 지원합니다. Colab Python 커널은 단일 Python 프로세스가 있는 단일 클라이언트 DTensor 애플리케이션의 예입니다.
멀티 클라이언트 DTensor 애플리케이션에서 멀티 Python 프로세스는 하나의 애플리케이션처럼 공동으로 작업을 수행합니다. 멀티 클라이언트 DTensor 애플리케이션에서 Mesh의 데카르트 그리드는 현재 클라이언트에 로컬로 연결되어 있는지 아니면 다른 클라이언트에 원격으로 연결되어 있는지에 관계 없이 여러 장치에 걸쳐 있을 수 있습니다. Mesh에서 사용하는 모든 장치 세트는 글로벌 장치 목록이라고 부릅니다.
멀티 클라이언트 DTensor 애플리케이션에서 Mesh의 생성은 참여하는 모든 클라이언트에 대해 글로벌 장치 목록과 동일하며, Mesh의 생성은 글로벌 장벽 역할을 합니다.
Mesh를 생성하는 동안 각 클라이언트는 예상 글로벌 장치 목록과 함께 로컬 기기 목록을 제공합니다. DTensor는 두 목록이 일치하는지 확인합니다. 멀티 클라이언트 메시 생성 및 글로벌 장치 목록에 대한 자세한 내용은 dtensor.create_mesh 및 dtensor.create_distributed_mesh에 대한 API 문서를 참조합니다.
단일 클라이언트는 1개의 클라이언트가 있는 멀티 클라이언트의 특수한 경우로 생각할 수 있습니다. 단일 클라이언트 애플리케이션에서 글로벌 장치 목록은 로컬 장치 목록과 동일합니다.
분할 텐서로서의 DTensor
이제 DTensor를 사용하여 코딩을 시작하겠습니다. 도우미 함수인 dtensor_from_array는 tf.Tensor처럼 보이는 항목으로부터 DTensor를 생성하는 방법을 보여줍니다. 이 함수는 2개의 단계를 수행합니다.
- 메시의 모든 장치에 텐서를 복제합니다.
- 인수에서 요청한 레이아웃에 따라 사본을 분할합니다.
def dtensor_from_array(arr, layout, shape=None, dtype=None):
"""Convert a DTensor from something that looks like an array or Tensor.
This function is convenient for quick doodling DTensors from a known,
unsharded data object in a single-client environment. This is not the
most efficient way of creating a DTensor, but it will do for this
tutorial.
"""
if shape is not None or dtype is not None:
arr = tf.constant(arr, shape=shape, dtype=dtype)
# replicate the input to the mesh
a = dtensor.copy_to_mesh(arr,
layout=dtensor.Layout.replicated(layout.mesh, rank=layout.rank))
# shard the copy to the desirable layout
return dtensor.relayout(a, layout=layout)
DTensor의 해부학
DTensor는 {code 0}tf.Tensor 개체이지만 분할 동작을 정의하는 {code 1}Layout 주석으로 확대됩니다. DTensor는 다음으로 구성되어 있습니다.
- 텐서의 글로벌 모양 및 dtype을 포함하는 글로벌 텐서 메타데이터입니다.
Tensor가 속한Mesh를 정의하고Tensor가Mesh에 분할되는 방식인Layout입니다.- 구성 요소 텐서 목록으로
Mesh의 로컬 장치당 하나의 항목만 있습니다.
dtensor from_array를 사용하여 첫 번째 DTensor인 my_first_dtensor를 생성하고 해당 콘텐츠를 검사할 수 있습니다.
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED], mesh)
my_first_dtensor = dtensor_from_array([0, 1], layout)
# Examine the dtensor content
print(my_first_dtensor)
print("global shape:", my_first_dtensor.shape)
print("dtype:", my_first_dtensor.dtype)
tf.Tensor([0 1], layout="sharding_specs:unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(2,), dtype=int32) global shape: (2,) dtype: <dtype: 'int32'>
레이아웃과 fetch_layout
DTensor의 레이아웃은 tf.Tensor의 일반 속성이 아닙니다. 대신 DTensor는 DTensor의 레이아웃에 액세스할 수 있는 dtensor.fetch_layout 함수를 제공합니다.
print(dtensor.fetch_layout(my_first_dtensor))
assert layout == dtensor.fetch_layout(my_first_dtensor)
Layout(sharding_specs=['unsharded'], mesh=<Mesh object with dims=[('x', 6)], device_type="CPU", num_local_devices=6), size=6>)
구성 요소 텐서, pack과 unpack
DTensor는 구성 요소 텐서 목록으로 구성되어 있습니다. Mesh에 있는 장치의 구성 요소 텐서는 이 장치에 저장된 글로벌 DTensor의 일부를 나타내는 Tensor 객체입니다.
DTensor는 dtensor.unpack을 통해 구성 요소 텐서로 압축을 해제할 수 있습니다. dtensor.unpack을 사용하여 DTensor의 구성 요소를 검사하고 구성 요소가 Mesh의 모든 장치에 있는지 확인할 수 있습니다.
글로벌 보기에서 구성 요소 텐서의 위치는 서로 중첩될 수 있습니다. 예를 들어 완전히 복제된 레이아웃의 경우 모든 구성 요소는 글로벌 텐서와 동일한 복제본입니다.
for component_tensor in dtensor.unpack(my_first_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([0 1], shape=(2,), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([0 1], shape=(2,), dtype=int32)
표시된 대로 my_first_dtensor는 6개의 장치 모두에 복제된 [0, 1]의 텐서입니다.
dtensor.unpack의 역연산은 dtensor.pack입니다. 구성 요소 텐서는 DTensor로 다시 압축할 수 있습니다.
구성 요소는 반환된 DTensor의 순위 및 dtype과 동일한 순위 및 dtype을 가져야 합니다. 그러나 dtensor.unpack의 입력인 구성 요소 텐서의 장치 배치에 대한 엄격한 요구사항은 없습니다. 함수는 구성 요소 텐서를 해당 장치에 자동으로 복사합니다.
packed_dtensor = dtensor.pack(
[[0, 1], [0, 1], [0, 1],
[0, 1], [0, 1], [0, 1]],
layout=layout
)
print(packed_dtensor)
tf.Tensor([0 1], layout="sharding_specs:unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(2,), dtype=int32)
메시에 DTensor 분할하기
지금까지 dim-1 Mesh에 완전히 복제된 1순위 DTensor인 my_first_dtensor로 작업을 진행했습니다.
다음에서는 dim-2 Mesh에 분할된DTensor를 생성하고 검사합니다. 다음 예제에서는 6개의 CPU 장치에서 3x2 Mesh를 사용하여 이 작업을 수행합니다. 여기서 메시 차원 'x'의 크기는 3개 장치이고 메시 차원'y'의 크기는 2개 장치입니다.
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
Dim-2 메시에 완전히 분할된 2순위 텐서
3x2 2순위 DTensor를 생성하여 'x' 메시 차원을 따라 첫 번째 축을 분할하고 'y' 메시 차원을 따라 두 번째 축을 분할합니다.
- 텐서 모양은 분할된 모든 축을 따라 메시 차원과 같기 때문에 각 장치는 DTensor의 단일 요소를 수신합니다.
- 구성 요소 텐서의 순위는 항상 글로벌 모양의 순위와 동일합니다. DTensor는 구성 요소 텐서와 글로벌 DTensor 사이의 관계를 찾을 수 있도록 정보를 보존하는 간단한 방식으로 이 규칙을 적용합니다.
fully_sharded_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout(["x", "y"], mesh))
for raw_component in dtensor.unpack(fully_sharded_dtensor):
print("Device:", raw_component.device, ",", raw_component)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([[0]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([[1]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([[2]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([[3]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([[4]], shape=(1, 1), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([[5]], shape=(1, 1), dtype=int32)
Dim-2 메시에 완전히 복제된 2순위 텐서
비교를 위해 동일한 dim-2 메시에 완전히 복제된 3x2 2순위 DTensor를 생성합니다.
- DTensor가 완전히 복제되기 때문에 각 장치는 3x2 DTensor의 전체 복제본을 수신합니다.
- 구성 요소 텐서의 순위는 글로벌 모양의 순위와 동일합니다. 이 내용은 중요하지 않습니다. 이 경우 구성 요소 텐서의 모양이 글로벌 모양과 동일하기 때문입니다.
fully_replicated_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh))
# Or, layout=tensor.Layout.fully_replicated(mesh, rank=2)
for component_tensor in dtensor.unpack(fully_replicated_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor( [[0 1] [2 3] [4 5]], shape=(3, 2), dtype=int32)
Dim-2 메시의 하이브리드 2순위 텐서
완전한 분할과 완전한 복제 사이에 있는 무언가는 어떤가요?
DTensor를 사용하면 Layout이 하이브리드가 될 수 있습니다. 일부 축을 따라 분할되지만 다른 축을 따라 복제됩니다.
예를 들어 동일한 3x2 2순위 DTensor를 다음과 같은 방식으로 분할할 수 있습니다.
'x'메시 차원을 따라 분할된 첫 번째 축입니다.'y'메시 차원을 따라 복제된 두 번째 축입니다.
이 분할 구성표를 작성하려면 두 번째 축의 분할 사양을 'y'에서 dtensor.UNSHARDED로 교체하고 두 번째 축을 따라 복제할 의도를 나타내면 됩니다. 레이아웃 객체는 Layout(['x', dtensor.UNSHARDED], mesh)처럼 보일 것입니다.
hybrid_sharded_dtensor = dtensor_from_array(
tf.reshape(tf.range(6), (3, 2)),
layout=dtensor.Layout(['x', dtensor.UNSHARDED], mesh))
for component_tensor in dtensor.unpack(hybrid_sharded_dtensor):
print("Device:", component_tensor.device, ",", component_tensor)
Device: /job:localhost/replica:0/task:0/device:CPU:0 , tf.Tensor([[0 1]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:1 , tf.Tensor([[0 1]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:2 , tf.Tensor([[2 3]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:3 , tf.Tensor([[2 3]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:4 , tf.Tensor([[4 5]], shape=(1, 2), dtype=int32) Device: /job:localhost/replica:0/task:0/device:CPU:5 , tf.Tensor([[4 5]], shape=(1, 2), dtype=int32)
생성된 D텐서의 구성 요소 텐서를 검사하고 구성표에 따라 실제로 분할되었는지 확인할 수 있습니다. 표로 상황을 설명하는 것이 도움이 될 수 있습니다.
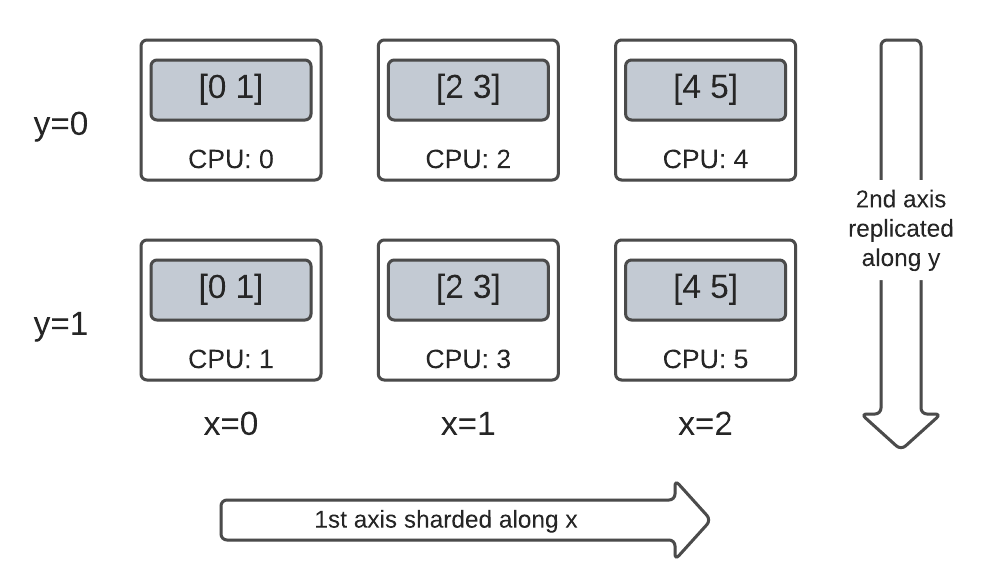
Tensor.numpy() 및 분할된 DTensor
분할된 DTensor에서 .numpy() 메서드를 호출하면 오류가 발생한다는 점에 유의해야 합니다. 이러한 오류는 여러 컴퓨팅 장치에서 여러 컴퓨팅 장치로부터 호스트 CPU 장치로 반환된 numpy 배열을 지원하며 의도하지 않은 데이터 수집이 수행되는 것을 방지하기 위함입니다.
print(fully_replicated_dtensor.numpy())
try:
fully_sharded_dtensor.numpy()
except tf.errors.UnimplementedError:
print("got an error as expected for fully_sharded_dtensor")
try:
hybrid_sharded_dtensor.numpy()
except tf.errors.UnimplementedError:
print("got an error as expected for hybrid_sharded_dtensor")
[[0 1] [2 3] [4 5]] got an error as expected for fully_sharded_dtensor got an error as expected for hybrid_sharded_dtensor
DTensor의 TensorFlow API
DTensor는 프로그램에서 텐서를 언제든지 대체하기 위해 노력합니다. TensorFlow Python API는 연산 라이브러리 함수인 tf.function, tf.GradientTape와 같은 tf.Tensor를 사용하며 또한 DTensor와도 작동합니다.
이를 수행하기 위해 DTensor는 각 TensorFlow 그래프에 대해 SPMD 확장이라 부르는 절차에서 동일한 SPMD 그래프를 생성하고 실행합니다. DTensor SPMD 확장의 몇 가지 중요한 단계는 다음과 같습니다.
- TensorFlow 그래프에서 DTensor의 분할
Layout전파 - 글로벌 DTensor의 TensorFlow 연산을 구성 요소 텐서의 동일한 TensorFlow 연산으로 다시 작성하고 필요한 경우 집합 및 통신 연산을 삽입
- 백엔드 중립 TensorFlow 연산을 백엔드 특정 TensorFlow 연산으로 낮춤
최종 결과는 DTensor가 텐서의 드롭인 교체품이라는 것입니다.
참고: DTensor는 여전히 실험적인 API이므로 DTensor 프로그래밍 모델의 범위와 한계를 탐구하고 확장하게 됩니다.
두 가지 방법을 사용하여 DTensor 실행을 트리거할 수 있습니다.
tf.matmul(a, b)와 같은 Python 함수의 피연산자로서의 DTensor는a,b또는 둘 다 DTensor인 경우 DTensor를 통해 실행됩니다.dtensor.call_with_layout(tf.ones, layout, shape=(3, 2))와 같이 Python 함수의 결과가 DTensor가 되도록 요청하면 tf.ones의 출력이layout에 따라 분할되도록 요청했기 때문에 DTensor를 통해 실행됩니다.
피연산자로서의 DTensor
많은 TensorFlow API 함수는 tf.Tensor를 피연산자로 사용하고 그 결과로 tf.Tensor를 반환합니다. 이러한 함수의 경우 DTensor를 피연산자로 전달하여 DTensor를 통해 함수를 실행하려는 의도를 표현할 수 있습니다. 이 섹션에서는 tf.matmul(a, b)을 예제로 사용합니다.
완전히 복제된 입력과 출력
이 경우 DTensor가 완전히 복제됩니다. Mesh의 각 장치에서,
- 피연산자
a의 구성 요소 텐서는[[1, 2, 3], [4, 5, 6]](2x3)입니다. - 피연산자
b의 구성 요소 텐서는[[6, 5], [4, 3], [2, 1]](3x2)입니다. - 계산은
(2x3, 3x2) -> 2x2의 단일MatMul로 구성됩니다. - 결과
c의 구성 요소 텐서는[[20, 14], [56,41]](2x2)입니다.
전체 부동 소수점 mul 연산의 수는 6 device * 4 result * 3 mul = 72입니다.
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=layout)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=layout)
c = tf.matmul(a, b) # runs 6 identical matmuls in parallel on 6 devices
# `c` is a DTensor replicated on all devices (same as `a` and `b`)
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
print("components:")
for component_tensor in dtensor.unpack(c):
print(component_tensor.device, component_tensor.numpy())
Sharding spec: ['unsharded', 'unsharded'] components: /job:localhost/replica:0/task:0/device:CPU:0 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:1 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:2 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:3 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:4 [[20 14] [56 41]] /job:localhost/replica:0/task:0/device:CPU:5 [[20 14] [56 41]]
축약된 축을 따라 피연산자 분할하기
피연산자 a 및 b를 분할하여 장치당 계산량을 줄일 수 있습니다. tf.matmul에서 많이 사용하는 분할 체계는 축약 축을 따라 피연산자를 분할하는 것입니다. 즉, 두 번째 축을 따라 a를, 그리고 첫 번째 축을 따라 b를 분할하는 것을 의미합니다.
이 체계에 따라 분할된 글로벌 행렬 곱셈은 동시에 실행되는 로컬 matmul에 의해 효율적으로 수행될 수 있으며 로컬 결과를 집계할 수 있도록 집단 축소가 이어서 수행됩니다. 이는 분산 행렬 점 곱셈을 구현하는 정식 방법이기도 합니다.
부동 소수점 mul 연산의 총 개수는 6 devices * 4 result * 1 = 24이며, 위의 완전히 복제된 경우인 (72)에 비해 3배 감소합니다. 3배 감소된 원인은 3개 장치의 크기를 사용하는 x 메시 차원을 따라 분할이 수행되기 때문입니다.
순차적으로 실행되는 연산의 수를 줄이는 것이 동기식 모델 병렬 처리가 훈련을 가속화하는 주요 메커니즘입니다.
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
a_layout = dtensor.Layout([dtensor.UNSHARDED, 'x'], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)
b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)
c = tf.matmul(a, b)
# `c` is a DTensor replicated on all devices (same as `a` and `b`)
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
Sharding spec: ['unsharded', 'unsharded']
추가 분할
입력에 대해 추가 분할을 수행할 수 있으며 입력값은 결과에 적절하게 이전됩니다. 예를 들어 첫 번째 축을 따라 피연산자 a의 추가 분할을 'y' 메시 차원에 적용할 수 있습니다. 추가 분할은 결과 c의 첫 번째 축으로 이전됩니다.
부동 소수점 mul 연산의 총 개수는 6 devices * 2 result * 1 = 12이며, 위의 경우 (24)에 비해 추가적으로 2배 감소합니다. 2배 감소된 원인은 2개 장치의 크기를 사용하는 y 메시 차원을 따라 분할이 수행되기 때문입니다.
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
a_layout = dtensor.Layout(['y', 'x'], mesh)
a = dtensor_from_array([[1, 2, 3], [4, 5, 6]], layout=a_layout)
b_layout = dtensor.Layout(['x', dtensor.UNSHARDED], mesh)
b = dtensor_from_array([[6, 5], [4, 3], [2, 1]], layout=b_layout)
c = tf.matmul(a, b)
# The sharding of `a` on the first axis is carried to `c'
print('Sharding spec:', dtensor.fetch_layout(c).sharding_specs)
print("components:")
for component_tensor in dtensor.unpack(c):
print(component_tensor.device, component_tensor.numpy())
Sharding spec: ['y', 'unsharded'] components: /job:localhost/replica:0/task:0/device:CPU:0 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:1 [[56 41]] /job:localhost/replica:0/task:0/device:CPU:2 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:3 [[56 41]] /job:localhost/replica:0/task:0/device:CPU:4 [[20 14]] /job:localhost/replica:0/task:0/device:CPU:5 [[56 41]]
출력으로서의 DTensor
피연산자를 사용하지 않지만 분할수 있는 텐서 결과를 반환하는 Python 함수는 어떨까요? 이러한 함수의 예는 다음과 같습니다.
DTensor는 이러한 Python 함수에 DTensor로 Python 함수를 실행하는 dtensor.call_with_layout을 즉시 제공하며, 반환된 텐서가 요청한 Layout이 있는 DTensor인지 확인합니다.
help(dtensor.call_with_layout)
Help on function call_with_layout in module tensorflow.dtensor.python.api:
call_with_layout(fn: Callable[..., Any], layout: Optional[tensorflow.dtensor.python.layout.Layout], *args, **kwargs) -> Any
Calls a function in the DTensor device scope if `layout` is not None.
If `layout` is not None, `fn` consumes DTensor(s) as input and produces a
DTensor as output; a DTensor is a tf.Tensor with layout-related attributes.
If `layout` is None, `fn` consumes and produces regular tf.Tensors.
Args:
fn: A supported TF API function such as tf.zeros.
layout: Optional, the layout of the output DTensor.
*args: Arguments given to `fn`.
**kwargs: Keyword arguments given to `fn`.
Returns:
The return value of `fn` transformed to a DTensor if requested.
즉시 실행되는 Python 함수는 일반적으로 중요하지 않은 단일 TensorFlow 연산만 포함합니다.
dtensor.call_with_layout가 있는 멀티 TensorFlow 연산을 방출하는 Python 함수를 사용하려면 함수를 tf.function으로 변환해야 합니다. tf.function 호출은 단일 TensorFlow 연산입니다. tf.function이 호출되는 경우 DTensor는 중간 텐서가 구체화되기 전에 tf.function의 계산 그래프를 분석할 때 레이아웃 전파를 수행할 수 있습니다.
단일 TensorFlow 연산을 방출하는 API
함수가 단일 TensorFlow 연산을 방출하는 경우 dtensor.call_with_layout을 함수에 직접 적용할 수 있습니다.
help(tf.ones)
Help on function ones in module tensorflow.python.ops.array_ops:
ones(shape, dtype=tf.float32, name=None)
Creates a tensor with all elements set to one (1).
See also `tf.ones_like`, `tf.zeros`, `tf.fill`, `tf.eye`.
This operation returns a tensor of type `dtype` with shape `shape` and
all elements set to one.
>>> tf.ones([3, 4], tf.int32)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]], dtype=int32)>
Args:
shape: A `list` of integers, a `tuple` of integers, or
a 1-D `Tensor` of type `int32`.
dtype: Optional DType of an element in the resulting `Tensor`. Default is
`tf.float32`.
name: Optional string. A name for the operation.
Returns:
A `Tensor` with all elements set to one (1).
mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
ones = dtensor.call_with_layout(tf.ones, dtensor.Layout(['x', 'y'], mesh), shape=(6, 4))
print(ones)
tf.Tensor({"CPU:0": [[1 1]
[1 1]], "CPU:1": [[1 1]
[1 1]], "CPU:2": [[1 1]
[1 1]], "CPU:3": [[1 1]
[1 1]], "CPU:4": [[1 1]
[1 1]], "CPU:5": [[1 1]
[1 1]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
멀티 TensorFlow 연산을 방출하는 API
API가 멀티 TensorFlow 연산을 방출하는 경우 tf.function을 통해 함수를 단일 연산으로 변환합니다. tf.random.stateleess_normal이 그 예입니다.
help(tf.random.stateless_normal)
Help on function stateless_random_normal in module tensorflow.python.ops.stateless_random_ops:
stateless_random_normal(shape, seed, mean=0.0, stddev=1.0, dtype=tf.float32, name=None, alg='auto_select')
Outputs deterministic pseudorandom values from a normal distribution.
This is a stateless version of `tf.random.normal`: if run twice with the
same seeds and shapes, it will produce the same pseudorandom numbers. The
output is consistent across multiple runs on the same hardware (and between
CPU and GPU), but may change between versions of TensorFlow or on non-CPU/GPU
hardware.
Args:
shape: A 1-D integer Tensor or Python array. The shape of the output tensor.
seed: A shape [2] Tensor, the seed to the random number generator. Must have
dtype `int32` or `int64`. (When using XLA, only `int32` is allowed.)
mean: A 0-D Tensor or Python value of type `dtype`. The mean of the normal
distribution.
stddev: A 0-D Tensor or Python value of type `dtype`. The standard deviation
of the normal distribution.
dtype: The float type of the output: `float16`, `bfloat16`, `float32`,
`float64`. Defaults to `float32`.
name: A name for the operation (optional).
alg: The RNG algorithm used to generate the random numbers. See
`tf.random.stateless_uniform` for a detailed explanation.
Returns:
A tensor of the specified shape filled with random normal values.
ones = dtensor.call_with_layout(
tf.function(tf.random.stateless_normal),
dtensor.Layout(['x', 'y'], mesh),
shape=(6, 4),
seed=(1, 1))
print(ones)
tf.Tensor({"CPU:0": [[0.0368092842 1.76192284]
[1.22868407 -0.731756687]], "CPU:1": [[0.255247623 -0.13820985]
[-0.747412503 1.06443202]], "CPU:2": [[-0.395325899 -0.836183369]
[0.581941128 -0.2587713]], "CPU:3": [[0.476060659 0.406645179]
[-0.110623844 -1.49052978]], "CPU:4": [[0.645035267 1.36384416]
[2.18210244 -0.965060234]], "CPU:5": [[-1.70534277 1.32558191]
[0.972473264 0.972343624]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
단일 TensorFlow 연산을 방출하는 Python 함수를 tf.function으로 래핑할 수 있습니다. 유일한 주의 사항은 Python 함수에서 tf.function을 생성할 때 관련 비용과 복잡성을 신경써야 한다는 것입니다.
ones = dtensor.call_with_layout(
tf.function(tf.ones),
dtensor.Layout(['x', 'y'], mesh),
shape=(6, 4))
print(ones)
tf.Tensor({"CPU:0": [[1 1]
[1 1]], "CPU:1": [[1 1]
[1 1]], "CPU:2": [[1 1]
[1 1]], "CPU:3": [[1 1]
[1 1]], "CPU:4": [[1 1]
[1 1]], "CPU:5": [[1 1]
[1 1]]}, layout="sharding_specs:x,y, mesh:|x=3,y=2|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(6, 4), dtype=float32)
tf.Variable에서 tensor.Variable로
Tensorflow에서 tf.Variable은 변경 가능한 Tensor 값의 홀더입니다. DTensor를 사용할 경우 dtensor.DVariable에 의해 해당 변수 의미 체계가 제공됩니다.
DTensor 변수에 새로운 유형의 Variable이 도입된 이유는 D변수(DVariables)에 레이아웃이 초기 값에서 변경할 수 없다는 추가 요구 사항이 있기 때문입니다.
mesh = dtensor.create_mesh([("x", 6)], devices=DEVICES)
layout = dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], mesh)
v = dtensor.DVariable(
initial_value=dtensor.call_with_layout(
tf.function(tf.random.stateless_normal),
layout=layout,
shape=tf.TensorShape([64, 32]),
seed=[1, 1],
dtype=tf.float32))
print(v.handle)
assert layout == dtensor.fetch_layout(v)
tf.Tensor({"CPU:0": <ResourceHandle(name="Resource-5-at-0x7ff3bc003070", device="/job:localhost/replica:0/task:0/device:CPU:0", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, "CPU:1": <ResourceHandle(name="Resource-1-at-0x7ff3fc001ca0", device="/job:localhost/replica:0/task:0/device:CPU:1", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, "CPU:2": <ResourceHandle(name="Resource-0-at-0x7ff3bc001f60", device="/job:localhost/replica:0/task:0/device:CPU:2", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, "CPU:3": <ResourceHandle(name="Resource-3-at-0x7fef8c04cc10", device="/job:localhost/replica:0/task:0/device:CPU:3", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, "CPU:4": <ResourceHandle(name="Resource-4-at-0x7ff3c00024c0", device="/job:localhost/replica:0/task:0/device:CPU:4", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>, "CPU:5": <ResourceHandle(name="Resource-2-at-0x7ff3f80019a0", device="/job:localhost/replica:0/task:0/device:CPU:5", container="Anonymous", type="tensorflow::Var", dtype and shapes : "[ DType enum: 1, Shape: [64,32] ]")>}, layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(), dtype=resource)
layout 일치에 대한 요구사항을 제외하고 DVariable은 tf.Variable과 동일하게 작동합니다. 예를 들어, DTensor에 D변수(DVariable)를 추가할 수 있습니다.
a = dtensor.call_with_layout(tf.ones, layout=layout, shape=(64, 32))
b = v + a # add DVariable and DTensor
print(b)
tf.Tensor([[2.66521645 2.36637592 1.77863169 ... -1.18624139 2.26035929 0.664066315] [0.511952519 0.655031443 0.122243524 ... 0.0424078107 1.67057109 0.912334144] [0.769825 1.42743981 3.13473773 ... 1.16159868 0.628931046 0.733521938] ... [0.388001859 2.72882509 2.92771554 ... 1.17472672 1.72462416 1.5047121] [-0.252545118 0.761886716 1.72119033 ... 0.775034547 2.8065362 1.00457215] [1.23498726 0.584536672 1.15659761 ... 0.955793858 1.11440909 0.18848455]], layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(64, 32), dtype=float32)
또한 D변수에 DTensor를 할당할 수도 있습니다.
v.assign(a) # assign a DTensor to a DVariable
print(a)
tf.Tensor([[1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] ... [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1]], layout="sharding_specs:unsharded,unsharded, mesh:|x=6|0,1,2,3,4,5|0,1,2,3,4,5|/job:localhost/replica:0/task:0/device:CPU:0,/job:localhost/replica:0/task:0/device:CPU:1,/job:localhost/replica:0/task:0/device:CPU:2,/job:localhost/replica:0/task:0/device:CPU:3,/job:localhost/replica:0/task:0/device:CPU:4,/job:localhost/replica:0/task:0/device:CPU:5", shape=(64, 32), dtype=float32)
호환되지 않는 레이아웃이 있는 DTensor를 할당하여 DVariable의 레이아웃을 변경하려고 하면 오류가 발생합니다.
# variable's layout is immutable.
another_mesh = dtensor.create_mesh([("x", 3), ("y", 2)], devices=DEVICES)
b = dtensor.call_with_layout(tf.ones,
layout=dtensor.Layout([dtensor.UNSHARDED, dtensor.UNSHARDED], another_mesh),
shape=(64, 32))
try:
v.assign(b)
except:
print("exception raised")
exception raised
다음 단계
이 Colab에서는 분산 컴퓨팅에 대한 TensorFlow의 확장 개념인 DTensor에 대해 배웠습니다. 튜토리얼에서 이 개념을 사용하려면 DTensor를 사용한 분산 훈련을 참고하세요.