
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub |
Interfejs API tf.data umożliwia tworzenie złożonych potoków wejściowych z prostych elementów wielokrotnego użytku. Na przykład potok dla modelu obrazu może agregować dane z plików w rozproszonym systemie plików, stosować losowe zakłócenia do każdego obrazu i scalać losowo wybrane obrazy w partię w celu uczenia. Potok dla modelu tekstowego może obejmować wyodrębnianie symboli z nieprzetworzonych danych tekstowych, konwertowanie ich na osadzanie identyfikatorów w tabeli przeglądowej i grupowanie sekwencji o różnych długościach. API tf.data umożliwia obsługę dużych ilości danych, odczytywanie z różnych formatów danych oraz wykonywanie złożonych transformacji.
Interfejs API tf.data wprowadza abstrakcję tf.data.Dataset , która reprezentuje sekwencję elementów, w której każdy element składa się z co najmniej jednego składnika. Na przykład w potoku obrazu element może być pojedynczym przykładem szkolenia z parą składników tensora reprezentujących obraz i jego etykietę.
Istnieją dwa różne sposoby tworzenia zestawu danych:
Źródło danych konstruuje zestaw
Datasetz danych przechowywanych w pamięci lub w co najmniej jednym pliku.Transformacja danych konstruuje zestaw danych z co najmniej jednego obiektu
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Mechanika podstawowa
Aby utworzyć potok wejściowy, musisz zacząć od źródła danych . Na przykład, aby skonstruować zestaw Dataset z danych w pamięci, można użyć tf.data.Dataset.from_tensors() lub tf.data.Dataset.from_tensor_slices() . Alternatywnie, jeśli dane wejściowe są przechowywane w pliku w zalecanym formacie TFRecord, możesz użyć tf.data.TFRecordDataset() .
Gdy masz już obiekt Dataset , możesz przekształcić go w nowy Dataset , łącząc wywołania metod w obiekcie tf.data.Dataset . Na przykład można zastosować przekształcenia na element, takie jak Dataset.map() i przekształcenia wieloelementowe, takie jak Dataset.batch() . Zobacz dokumentację dotyczącą tf.data.Dataset , aby uzyskać pełną listę przekształceń.
Obiekt Dataset jest iterowalny w Pythonie. Dzięki temu możliwe jest konsumowanie jego elementów za pomocą pętli for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
Lub jawnie tworząc iterator Pythona za pomocą iter i zużywając jego elementy za pomocą next :
it = iter(dataset)
print(next(it).numpy())
8
Alternatywnie elementy zestawu danych można zużywać przy użyciu transformacji reduce , która zmniejsza wszystkie elementy w celu uzyskania jednego wyniku. Poniższy przykład ilustruje sposób użycia przekształcenia reduce do obliczenia sumy zestawu danych liczb całkowitych.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Struktura zbioru danych
Zestaw danych tworzy sekwencję elementów , gdzie każdy element jest taką samą (zagnieżdżoną) strukturą komponentów . Poszczególne składniki struktury mogą być dowolnego typu reprezentowanego przez tf.TypeSpec , w tym tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray lub tf.data.Dataset .
Konstrukcje Pythona, których można użyć do wyrażenia (zagnieżdżonej) struktury elementów, obejmują tuple , dict , NamedTuple i OrderedDict . W szczególności list nie jest prawidłową konstrukcją do wyrażania struktury elementów zestawu danych. Dzieje się tak, ponieważ wcześni użytkownicy tf.data uważali, że dane wejściowe list (np. przekazywane do tf.data.Dataset.from_tensors ) są automatycznie pakowane jako tensory, a dane wyjściowe list (np. zwracane wartości funkcji zdefiniowanych przez użytkownika) są przekształcane w tuple . W konsekwencji, jeśli chcesz, aby dane wejściowe list były traktowane jako struktura, musisz je przekonwertować na tuple , a jeśli chcesz, aby dane wyjściowe list były pojedynczym komponentem, musisz jawnie je spakować za pomocą tf.stack .
Właściwość Dataset.element_spec umożliwia sprawdzenie typu każdego składnika elementu. Właściwość zwraca zagnieżdżoną strukturę obiektów tf.TypeSpec pasującą do struktury elementu, który może być pojedynczym składnikiem, krotką składników lub zagnieżdżoną krotką składników. Na przykład:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Transformacje Dataset obsługują zestawy danych o dowolnej strukturze. Podczas korzystania z Dataset.map() i Dataset.filter() , które stosują funkcję do każdego elementu, struktura elementu określa argumenty funkcji:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Odczytywanie danych wejściowych
Zużywanie tablic NumPy
Zobacz Ładowanie tablic NumPy , aby uzyskać więcej przykładów.
Jeśli wszystkie dane wejściowe mieszczą się w pamięci, najprostszym sposobem utworzenia z nich Dataset jest przekonwertowanie ich na obiekty tf.Tensor i użycie Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Zużywanie generatorów Pythona
Innym powszechnym źródłem danych, które można łatwo pozyskać jako tf.data.Dataset , jest generator Pythona.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Konstruktor Dataset.from_generator konwertuje generator Pythona na w pełni funkcjonalny tf.data.Dataset .
Konstruktor przyjmuje wywoływalne jako dane wejściowe, a nie iterator. Pozwala to na ponowne uruchomienie generatora po osiągnięciu końca. Pobiera opcjonalny argument args , który jest przekazywany jako argumenty wywoływanej.
Argument output_types jest wymagany, ponieważ tf.data buduje wewnętrznie tf.Graph , a krawędzie grafów wymagają tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
Argument output_shapes nie jest wymagany, ale jest wysoce zalecany, ponieważ wiele operacji TensorFlow nie obsługuje tensorów o nieznanej randze. Jeśli długość określonej osi jest nieznana lub zmienna, ustaw ją jako None w output_shapes .
Należy również zauważyć, że output_shapes i output_types tym samym regułom zagnieżdżania, co inne metody zestawu danych.
Oto przykładowy generator, który demonstruje oba aspekty, zwraca krotki tablic, gdzie druga tablica jest wektorem o nieznanej długości.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
Pierwsze dane wyjściowe to int32 , a drugie to float32 .
Pierwsza pozycja to skalar, kształt () , a druga to wektor o nieznanej długości, kształt (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Teraz może być używany jak zwykły tf.data.Dataset . Należy pamiętać, że podczas grupowania zestawu danych o zmiennym kształcie należy użyć Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Aby uzyskać bardziej realistyczny przykład, spróbuj zawinąć preprocessing.image.ImageDataGenerator jako tf.data.Dataset .
Najpierw pobierz dane:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
Utwórz image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Zużywanie danych TFRecord
Zobacz Ładowanie TFRecords dla pełnego przykładu.
Interfejs API tf.data obsługuje różne formaty plików, dzięki czemu można przetwarzać duże zestawy danych, które nie mieszczą się w pamięci. Na przykład format pliku TFRecord jest prostym, zorientowanym na rekordy formatem binarnym, którego wiele aplikacji TensorFlow używa do trenowania danych. Klasa tf.data.TFRecordDataset umożliwia strumieniowe przesyłanie zawartości jednego lub większej liczby plików TFRecord jako części potoku wejściowego.
Oto przykład wykorzystujący plik testowy z francuskich znaków nazw ulic (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
Argumentem filenames inicjatora TFRecordDataset może być ciąg, lista ciągów lub tf.Tensor ciągów. Dlatego jeśli masz dwa zestawy plików do celów uczenia i walidacji, możesz utworzyć metodę fabryczną, która generuje zestaw danych, przyjmując nazwy plików jako argument wejściowy:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Wiele projektów TensorFlow używa serializowanych rekordów tf.train.Example w swoich plikach TFRecord. Należy je rozszyfrować, zanim będzie można je sprawdzić:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Zużywanie danych tekstowych
Zobacz Wczytywanie tekstu , aby zapoznać się z przykładem.
Wiele zestawów danych jest dystrybuowanych jako jeden lub więcej plików tekstowych. tf.data.TextLineDataset zapewnia łatwy sposób wyodrębniania wierszy z co najmniej jednego pliku tekstowego. Biorąc pod uwagę co najmniej jedną nazwę pliku, TextLineDataset wygeneruje jeden element o wartości ciągu w każdym wierszu tych plików.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Oto kilka pierwszych linijek pierwszego pliku:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Aby zmienić wiersze między plikami, użyj Dataset.interleave . Ułatwia to wspólne mieszanie plików. Oto pierwszy, drugi i trzeci wiersz z każdego tłumaczenia:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
Domyślnie TextLineDataset zwraca każdy wiersz każdego pliku, co może być niepożądane, na przykład, jeśli plik zaczyna się od wiersza nagłówka lub zawiera komentarze. Te wiersze można usunąć za pomocą Dataset.skip() lub Dataset.filter() . Tutaj pomijasz pierwszą linię, a następnie filtrujesz, aby znaleźć tylko ocalałych.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Zużywam dane CSV
Zobacz Ładowanie plików CSV i Ładowanie ramek danych Pandas, aby uzyskać więcej przykładów.
Format pliku CSV to popularny format przechowywania danych tabelarycznych w postaci zwykłego tekstu.
Na przykład:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Jeśli twoje dane mieszczą się w pamięci, ta sama metoda Dataset.from_tensor_slices działa na słownikach, umożliwiając łatwe importowanie tych danych:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Bardziej skalowalnym podejściem jest ładowanie z dysku w razie potrzeby.
Moduł tf.data udostępnia metody wyodrębniania rekordów z jednego lub więcej plików CSV zgodnych z RFC 4180 .
experimental.make_csv_dataset funkcja.make_csv_dataset to interfejs wysokiego poziomu do odczytywania zestawów plików csv. Obsługuje wnioskowanie o typie kolumn i wiele innych funkcji, takich jak grupowanie i tasowanie, aby ułatwić użycie.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Możesz użyć argumentu select_columns , jeśli potrzebujesz tylko podzbioru kolumn.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
Istnieje również klasa experimental.CsvDataset niższego poziomu. CsvDataset, która zapewnia bardziej szczegółową kontrolę. Nie obsługuje wnioskowania o typie kolumny. Zamiast tego musisz określić typ każdej kolumny.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Jeśli niektóre kolumny są puste, ten niskopoziomowy interfejs umożliwia podanie wartości domyślnych zamiast typów kolumn.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
Domyślnie CsvDataset zwraca każdą kolumnę w każdym wierszu pliku, co może nie być pożądane, na przykład jeśli plik zaczyna się od wiersza nagłówka, który należy zignorować, lub jeśli niektóre kolumny nie są wymagane w danych wejściowych. Te wiersze i pola można usunąć odpowiednio za pomocą argumentów header i select_cols .
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Zużywanie zestawów plików
Istnieje wiele zbiorów danych dystrybuowanych jako zestaw plików, gdzie każdy plik jest przykładem.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
Katalog główny zawiera katalog dla każdej klasy:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
Pliki w każdym katalogu klas są przykładami:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Odczytaj dane za pomocą funkcji tf.io.read_file i wyodrębnij etykietę ze ścieżki, zwracając pary (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Grupowanie elementów zbioru danych
Proste dozowanie
Najprostsza forma grupowania stosów n kolejnych elementów zestawu danych w jeden element. Dataset.batch() robi dokładnie to, z takimi samymi ograniczeniami, jak operator tf.stack() , zastosowany do każdego komponentu elementów: tj. dla każdego komponentu i wszystkie elementy muszą mieć tensor o dokładnie tym samym kształcie.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Podczas gdy tf.data próbuje propagować informacje o kształcie, domyślne ustawienia Dataset.batch skutkują nieznanym rozmiarem partii, ponieważ ostatnia partia może nie być pełna. Zwróć uwagę na None w kształcie:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Użyj argumentu drop_remainder , aby zignorować ostatnią partię i uzyskać pełną propagację kształtu:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Tensory dozujące z wyściółką
Powyższy przepis działa dla tensorów, które mają ten sam rozmiar. Jednak wiele modeli (np. modele sekwencyjne) pracuje z danymi wejściowymi, które mogą mieć różną wielkość (np. sekwencje o różnych długościach). Aby obsłużyć ten przypadek, transformacja Dataset.padded_batch umożliwia wsadowe tensory o różnych kształtach, określając jeden lub więcej wymiarów, w których mogą być uzupełniane.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
Transformacja Dataset.padded_batch umożliwia ustawienie innego wypełnienia dla każdego wymiaru każdego składnika i może mieć zmienną długość (oznaczoną przez None w powyższym przykładzie) lub stałą długość. Możliwe jest również nadpisanie wartości dopełnienia, która domyślnie wynosi 0.
Przepływy pracy szkoleniowe
Przetwarzanie wielu epok
Interfejs API tf.data oferuje dwa główne sposoby przetwarzania wielu epok tych samych danych.
Najprostszym sposobem na iterację zestawu danych w wielu epokach jest użycie transformacji Dataset.repeat() . Najpierw utwórz zbiór danych tytanicznych danych:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
Zastosowanie transformacji Dataset.repeat() bez argumentów spowoduje powtarzanie danych wejściowych w nieskończoność.
Transformacja Dataset.repeat łączy swoje argumenty bez sygnalizowania końca jednej epoki i początku następnej. Z tego powodu Dataset.batch zastosowany po Dataset.repeat da partie, które wykraczają poza granice epoki:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
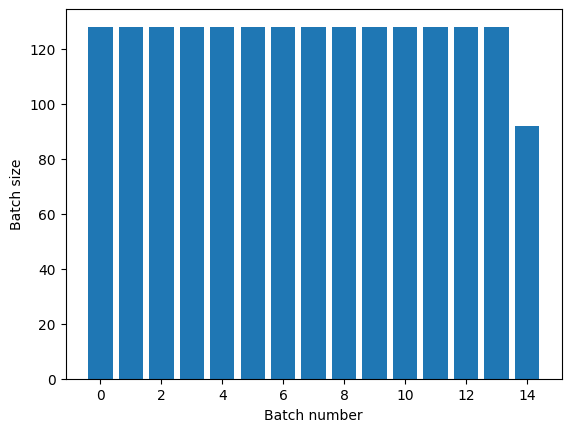
Jeśli potrzebujesz wyraźnej separacji epok, umieść Dataset.batch przed powtórzeniem:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
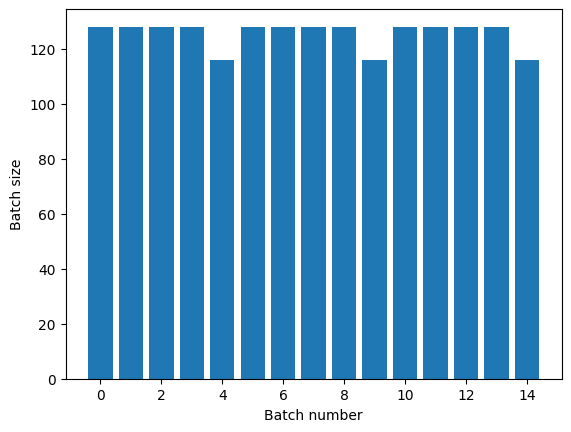
Jeśli chcesz wykonać niestandardowe obliczenia (np. zbierać statystyki) na końcu każdej epoki, najprościej jest ponownie uruchomić iterację zestawu danych w każdej epoce:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Losowe tasowanie danych wejściowych
Dataset.shuffle() utrzymuje bufor o stałym rozmiarze i jednolicie wybiera następny element losowo z tego bufora.
Dodaj indeks do zbioru danych, aby zobaczyć efekt:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Ponieważ buffer_size wynosi 100, a wielkość partii to 20, pierwsza partia nie zawiera elementów o indeksie powyżej 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Podobnie jak w przypadku Dataset.batch , kolejność względem Dataset.repeat ma znaczenie.
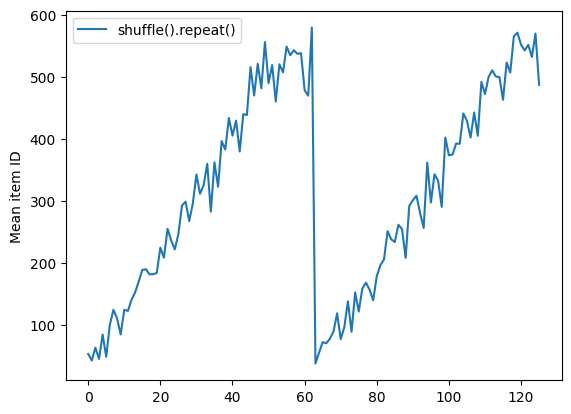
Dataset.shuffle nie sygnalizuje końca epoki, dopóki bufor shuffle nie jest pusty. Tak więc tasowanie umieszczone przed powtórzeniem pokaże każdy element jednej epoki przed przejściem do następnej:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
Ale powtórzenie przed przetasowaniem miesza granice epoki:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
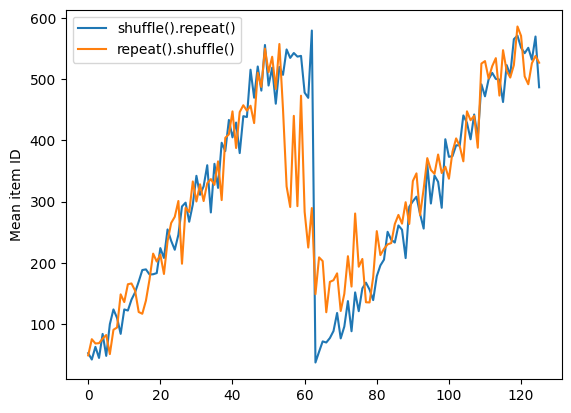
Wstępne przetwarzanie danych
Dataset.map(f) tworzy nowy zestaw danych, stosując daną funkcję f do każdego elementu wejściowego zestawu danych. Opiera się na funkcji map() , która jest powszechnie stosowana do list (i innych struktur) w funkcjonalnych językach programowania. Funkcja f pobiera obiekty tf.Tensor , które reprezentują pojedynczy element w danych wejściowych, i zwraca obiekty tf.Tensor , które będą reprezentować pojedynczy element w nowym zestawie danych. Jego implementacja wykorzystuje standardowe operacje TensorFlow do przekształcenia jednego elementu w inny.
W tej sekcji omówiono typowe przykłady użycia Dataset.map() .
Dekodowanie danych obrazu i zmiana ich rozmiaru
Podczas uczenia sieci neuronowej na danych obrazu ze świata rzeczywistego często konieczne jest przekonwertowanie obrazów o różnych rozmiarach do wspólnego rozmiaru, aby można je było pogrupować w ustalony rozmiar.
Odbuduj zbiór danych nazw plików kwiatów:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Napisz funkcję, która manipuluje elementami zestawu danych.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Sprawdź, czy to działa.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Zamapuj go na zbiór danych.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Stosowanie dowolnej logiki Pythona
Ze względu na wydajność używaj operacji TensorFlow do wstępnego przetwarzania danych, gdy tylko jest to możliwe. Jednak czasami przydatne jest wywoływanie zewnętrznych bibliotek Pythona podczas analizowania danych wejściowych. Możesz użyć operacji tf.py_function() Dataset.map() w transformacji Dataset.map().
Na przykład, jeśli chcesz zastosować losowy obrót, moduł tf.image ma tylko tf.image.rot90 , co nie jest zbyt przydatne do powiększania obrazu.
Aby zademonstrować tf.py_function , spróbuj zamiast tego użyć funkcji scipy.ndimage.rotate :
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Aby użyć tej funkcji z Dataset.map , obowiązują te same zastrzeżenia, co w przypadku Dataset.from_generator , musisz opisać zwracane kształty i typy podczas stosowania funkcji:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


tf.Example wiadomości z bufora protokołu
Wiele potoków wejściowych wyodrębnia komunikaty bufora protokołu tf.train.Example z formatu TFRecord. Każdy rekord tf.train.Example zawiera co najmniej jedną „funkcję”, a potok wejściowy zwykle konwertuje te funkcje na tensory.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Możesz pracować z tf.train.Example protos poza tf.data.Dataset , aby zrozumieć dane:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Okienkowanie szeregów czasowych
Aby zapoznać się z przykładem od końca do końca szeregów czasowych, zobacz: Prognozowanie szeregów czasowych .
Dane szeregów czasowych są często organizowane z nienaruszoną osią czasu.
Użyj prostego Dataset.range , aby zademonstrować:
range_ds = tf.data.Dataset.range(100000)
Zazwyczaj modele oparte na tego rodzaju danych wymagają ciągłego wycinka czasu.
Najprostszym podejściem byłoby zgrupowanie danych:
Korzystanie batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
Lub, aby gęste przewidywania o jeden krok w przyszłość, możesz przesunąć cechy i etykiety o jeden krok względem siebie:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Aby przewidzieć całe okno zamiast stałego przesunięcia, możesz podzielić partie na dwie części:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Aby umożliwić nakładanie się funkcji jednej partii i etykiet innej, użyj Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
Korzystanie z window
Korzystanie z Dataset.batch działa, ale zdarzają się sytuacje, w których możesz potrzebować dokładniejszej kontroli. Metoda Dataset.window zapewnia pełną kontrolę, ale wymaga pewnej ostrożności: zwraca Dataset Datasets . Zobacz strukturę zbioru danych, aby uzyskać szczegółowe informacje.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
Metoda Dataset.flat_map może przyjąć zestaw danych zestawów danych i spłaszczyć go w pojedynczy zestaw danych:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
W prawie wszystkich przypadkach będziesz chciał .batch zestaw danych:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Teraz możesz zobaczyć, że argument shift kontroluje, o ile przesuwa się każde okno.
Składając to razem, możesz napisać tę funkcję:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Następnie łatwo wyodrębnić etykiety, tak jak poprzednio:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
Ponowne próbkowanie
Podczas pracy z zestawem danych, który jest bardzo niezrównoważony klasowo, możesz chcieć przeprowadzić ponowne próbkowanie zestawu danych. tf.data udostępnia dwie metody, aby to zrobić. Dobrym przykładem tego rodzaju problemu jest zbiór danych dotyczących oszustw związanych z kartami kredytowymi.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Teraz sprawdź rozkład klas, jest mocno wypaczony:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Powszechnym podejściem do trenowania z niezrównoważonym zestawem danych jest jego zrównoważenie. tf.data zawiera kilka metod, które umożliwiają ten przepływ pracy:
Próbkowanie zbiorów danych
Jednym ze sposobów ponownego próbkowania zestawu danych jest użycie sample_from_datasets . Jest to bardziej przydatne, gdy masz osobny data.Dataset dla każdej klasy.
Tutaj wystarczy użyć filtra, aby wygenerować je z danych o oszustwach związanych z kartą kredytową:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Aby użyć tf.data.Dataset.sample_from_datasets , przekaż zestawy danych i wagę dla każdego z nich:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Teraz zbiór danych generuje przykłady każdej klasy z prawdopodobieństwem 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Ponowne próbkowanie odrzucenia
Jednym z problemów z powyższym podejściem Dataset.sample_from_datasets jest to, że wymaga ono oddzielnego tf.data.Dataset dla każdej klasy. Możesz użyć Dataset.filter do utworzenia tych dwóch zestawów danych, ale spowoduje to dwukrotne wczytanie wszystkich danych.
Metodę data.Dataset.rejection_resample można zastosować do zestawu danych, aby ponownie go zrównoważyć, ładując go tylko raz. Elementy zostaną usunięte ze zbioru danych, aby osiągnąć równowagę.
data.Dataset.rejection_resample przyjmuje argument class_func . Ta class_func jest stosowana do każdego elementu zestawu danych i służy do określenia, do której klasy należy przykład w celu równoważenia.
Celem jest tutaj zrównoważenie rozkładu etykiet, a elementy creditcard_ds są już parami (features, label) . Zatem class_func musi tylko zwrócić te etykiety:
def class_func(features, label):
return label
Metoda resamplingu dotyczy poszczególnych przykładów, więc w tym przypadku przed zastosowaniem tej metody należy unbatch zestaw danych.
Metoda wymaga rozkładu docelowego i opcjonalnie wstępnego oszacowania rozkładu jako danych wejściowych.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
Metoda rejection_resample zwraca (class, example) pary, w których class jest wynikiem funkcji class_func . W tym przypadku example był już parą (feature, label) , więc użyj map , aby usunąć dodatkową kopię etykiet:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Teraz zbiór danych generuje przykłady każdej klasy z prawdopodobieństwem 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Punkt kontrolny iteratora
Tensorflow obsługuje przyjmowanie punktów kontrolnych , dzięki czemu po ponownym uruchomieniu procesu treningowego może przywrócić ostatni punkt kontrolny, aby odzyskać większość postępów. Oprócz sprawdzania zmiennych modelu można również sprawdzać postęp iteratora zestawu danych. Może to być przydatne, jeśli masz duży zestaw danych i nie chcesz rozpoczynać zestawu danych od początku przy każdym ponownym uruchomieniu. Należy jednak zauważyć, że punkty kontrolne iteratora mogą być duże, ponieważ przekształcenia, takie jak shuffle i prefetch , wymagają elementów buforujących w iteratorze.
Aby uwzględnić iterator w punkcie kontrolnym, przekaż iterator do konstruktora tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Używanie tf.data z tf.keras
API tf.keras upraszcza wiele aspektów tworzenia i wykonywania modeli uczenia maszynowego. Jego interfejsy API .fit( .fit() i .evaluate( .evaluate() i .predict() obsługują zestawy danych jako dane wejściowe. Oto szybka konfiguracja zestawu danych i modelu:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Przekazywanie zestawu danych par (feature, label) to wszystko, co jest potrzebne dla Model.fit i Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Jeśli przekazujesz nieskończony zbiór danych, na przykład wywołując Dataset.repeat() , musisz tylko przekazać argument steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Do oceny możesz przekazać liczbę kroków oceny:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
W przypadku długich zbiorów danych ustaw liczbę kroków do oceny:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Etykiety nie są wymagane podczas wywoływania Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Ale etykiety są ignorowane, jeśli przekażesz zbiór danych, który je zawiera:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)