
| | |  عرض المصدر على جيثب عرض المصدر على جيثب |
تمكّنك واجهة برمجة تطبيقات tf.data من إنشاء خطوط إدخال معقدة من قطع بسيطة قابلة لإعادة الاستخدام. على سبيل المثال ، قد يقوم خط الأنابيب الخاص بنموذج الصورة بتجميع البيانات من الملفات في نظام الملفات الموزعة ، وتطبيق اضطرابات عشوائية على كل صورة ، ودمج الصور المختارة عشوائيًا في دفعة للتدريب. قد يتضمن خط الأنابيب لنموذج نصي استخراج الرموز من بيانات النص الخام ، وتحويلها إلى تضمين معرفات في جدول بحث ، وتجميع التسلسلات ذات الأطوال المختلفة معًا. تتيح واجهة برمجة تطبيقات tf.data إمكانية معالجة كميات كبيرة من البيانات ، وقراءتها من تنسيقات بيانات مختلفة ، وإجراء تحويلات معقدة.
تقدم tf.data API تجريد tf.data.Dataset الذي يمثل سلسلة من العناصر ، حيث يتكون كل عنصر من مكون واحد أو أكثر. على سبيل المثال ، في خط أنابيب الصورة ، قد يكون العنصر مثالاً تدريبياً منفردًا ، مع زوج من مكونات الموتر التي تمثل الصورة والتسمية الخاصة بها.
توجد طريقتان متميزتان لإنشاء مجموعة بيانات:
ينشئ مصدر البيانات
Datasetمن البيانات المخزنة في الذاكرة أو في ملف واحد أو أكثر.يُنشئ تحويل البيانات مجموعة بيانات من واحد أو أكثر من كائنات
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
ميكانيكا أساسية
لإنشاء مسار إدخال ، يجب أن تبدأ بمصدر بيانات. على سبيل المثال ، لإنشاء مجموعة بيانات من البيانات الموجودة في الذاكرة ، يمكنك استخدام Dataset tf.data.Dataset.from_tensors() أو tf.data.Dataset.from_tensor_slices() . بدلاً من ذلك ، إذا كانت بيانات الإدخال مخزنة في ملف بتنسيق TFRecord الموصى به ، فيمكنك استخدام tf.data.TFRecordDataset() .
بمجرد أن يكون لديك كائن Dataset ، يمكنك تحويله إلى Dataset جديد عن طريق تسلسل استدعاءات الأسلوب على كائن tf.data.Dataset . على سبيل المثال ، يمكنك تطبيق تحويلات لكل عنصر مثل Dataset.map() والتحويلات متعددة العناصر مثل Dataset.batch() . راجع وثائق tf.data.Dataset للحصول على قائمة كاملة بالتحولات.
كائن Dataset هو Python قابل للتكرار. هذا يجعل من الممكن استهلاك عناصرها باستخدام حلقة for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
أو عن طريق إنشاء مكرر Python بشكل صريح باستخدام iter واستهلاك عناصره باستخدام next :
it = iter(dataset)
print(next(it).numpy())
8
بدلاً من ذلك ، يمكن استهلاك عناصر مجموعة البيانات باستخدام reduce التحويل ، مما يقلل من جميع العناصر لإنتاج نتيجة واحدة. يوضح المثال التالي كيفية استخدام reduce التحويل لحساب مجموع مجموعة بيانات من الأعداد الصحيحة.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
هيكل مجموعة البيانات
تنتج مجموعة البيانات سلسلة من العناصر ، حيث يكون كل عنصر هو نفس البنية (المتداخلة) للمكونات . يمكن أن تكون المكونات الفردية للهيكل من أي نوع يمكن تمثيله بواسطة tf.TypeSpec ، بما في ذلك tf.Tensor أو tf.sparse.SparseTensor أو tf.RaggedTensor أو tf.TensorArray أو tf.data.Dataset .
تتضمن تكوينات Python التي يمكن استخدامها للتعبير عن البنية (المتداخلة) للعناصر ، tuple و NamedTuple و dict و OrderedDict . على وجه الخصوص ، لا تعد list تكوينًا صالحًا للتعبير عن بنية عناصر مجموعة البيانات. هذا لأن مستخدمي tf.data الأوائل شعروا بقوة بمدخلات list (على سبيل المثال التي تم تمريرها إلى tf.data.Dataset.from_tensors ) التي يتم تعبئتها تلقائيًا كموترات ومخرجات list (على سبيل المثال ، قيم إرجاع وظائف محددة بواسطة المستخدم) يتم إجبارها في tuple . نتيجة لذلك ، إذا كنت ترغب في معاملة مدخلات list كبنية ، فأنت بحاجة إلى تحويلها إلى tuple وإذا كنت ترغب في أن يكون إخراج list مكونًا واحدًا ، فأنت بحاجة إلى حزمه بشكل صريح باستخدام tf.stack .
تتيح لك الخاصية Dataset.element_spec فحص نوع كل مكون عنصر. تقوم الخاصية بإرجاع بنية متداخلة لكائنات tf.TypeSpec ، تطابق بنية العنصر ، والتي قد تكون مكونًا واحدًا ، أو مجموعة مكونات ، أو مجموعة متداخلة من المكونات. فمثلا:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
تدعم تحويلات Dataset البيانات مجموعات البيانات لأي بنية. عند استخدام Dataset.map() و Dataset.filter() ، التي تطبق دالة على كل عنصر ، تحدد بنية العنصر وسيطات الوظيفة:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
قراءة بيانات الإدخال
استهلاك مصفوفات NumPy
راجع تحميل مصفوفات NumPy لمزيد من الأمثلة.
إذا كانت جميع بيانات الإدخال الخاصة بك تتلاءم مع الذاكرة ، فإن أبسط طريقة لإنشاء مجموعة Dataset منها هي تحويلها إلى كائنات tf.Tensor واستخدام Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
استهلاك مولدات بايثون
مصدر بيانات شائع آخر يمكن استيعابه بسهولة كملف tf.data.Dataset هو مولد Python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
يحول مُنشئ Dataset.from_generator مُنشئ Python إلى مجموعة tf.data.Dataset كاملة الوظائف.
يأخذ المنشئ قابلاً للاستدعاء كمدخل وليس مكررًا. هذا يسمح له بإعادة تشغيل المولد عندما يصل إلى النهاية. يأخذ وسيطة args اختيارية ، والتي يتم تمريرها على أنها وسيطات قابلة للاستدعاء.
الوسيطة output_types مطلوبة لأن tf.data ينشئ tf.Graph داخليًا ، وتتطلب حواف الرسم البياني tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
وسيطة output_shapes ليست مطلوبة ولكن يوصى بها بشدة لأن العديد من عمليات TensorFlow لا تدعم موترات ذات رتبة غير معروفة. إذا كان طول محور معين غير معروف أو متغير ، فاضبطه على أنه None في output_shapes .
من المهم أيضًا ملاحظة أن output_shapes و output_types تتبع نفس قواعد التداخل مثل طرق مجموعة البيانات الأخرى.
هنا مثال مولد يوضح كلا الجانبين ، ويعيد مجموعات من المصفوفات ، حيث يكون المصفوفة الثانية متجهًا بطول غير معروف.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
الناتج الأول هو int32 والثاني هو float32 .
العنصر الأول هو مقياس ، شكل () ، والثاني متجه غير معروف الطول والشكل (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
الآن يمكن استخدامه مثل tf.data.Dataset عادي. لاحظ أنه عند تجميع مجموعة بيانات ذات شكل متغير ، تحتاج إلى استخدام Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
للحصول على مثال أكثر واقعية ، جرب تغليف preprocessing.image.ImageDataGenerator كملف tf.data.Dataset .
قم أولاً بتنزيل البيانات:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
استهلاك بيانات TFRecord
راجع تحميل سجلات TF للحصول على مثال شامل.
تدعم tf.data API مجموعة متنوعة من تنسيقات الملفات بحيث يمكنك معالجة مجموعات البيانات الكبيرة التي لا تتناسب مع الذاكرة. على سبيل المثال ، تنسيق ملف TFRecord هو تنسيق ثنائي بسيط موجه نحو التسجيل تستخدمه العديد من تطبيقات TensorFlow لبيانات التدريب. تمكّنك فئة tf.data.TFRecordDataset من التدفق عبر محتويات واحد أو أكثر من ملفات TFRecord كجزء من مسار الإدخال.
فيما يلي مثال باستخدام ملف الاختبار من إشارات اسم الشارع الفرنسية (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
يمكن أن تكون وسيطة filenames TFRecordDataset إما سلسلة أو قائمة سلاسل أو tf.Tensor من السلاسل. لذلك ، إذا كانت لديك مجموعتان من الملفات لأغراض التدريب والتحقق من الصحة ، فيمكنك إنشاء طريقة مصنع تُنتج مجموعة البيانات ، مع أخذ أسماء الملفات كوسيطة إدخال:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
تستخدم العديد من مشروعات TensorFlow سجلات tf.train.Example المتسلسلة في ملفات TFRecord الخاصة بهم. يجب فك تشفيرها قبل أن يتم فحصها:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
استهلاك البيانات النصية
انظر تحميل النص للحصول على مثال نهاية إلى نهاية.
يتم توزيع العديد من مجموعات البيانات كملف نصي واحد أو أكثر. توفر tf.data.TextLineDataset طريقة سهلة لاستخراج الأسطر من ملف نصي واحد أو أكثر. بالنظر إلى اسم ملف واحد أو أكثر ، TextLineDataset واحدًا ذا قيمة سلسلة لكل سطر من هذه الملفات.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
فيما يلي الأسطر القليلة الأولى من الملف الأول:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
لتبديل الأسطر بين الملفات ، استخدم Dataset.interleave . هذا يجعل من السهل خلط الملفات معًا. فيما يلي الأسطر الأولى والثانية والثالثة من كل ترجمة:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
بشكل افتراضي ، ينتج TextLineDataset كل سطر من كل ملف ، وهو ما قد لا يكون مرغوبًا فيه ، على سبيل المثال ، إذا كان الملف يبدأ بسطر رأس ، أو يحتوي على تعليقات. يمكن إزالة هذه الخطوط باستخدام Dataset.skip() أو Dataset.filter() . هنا ، يمكنك تخطي السطر الأول ، ثم التصفية للعثور على الناجين فقط.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
استهلاك بيانات CSV
انظر تحميل ملفات CSV وتحميل Pandas DataFrames لمزيد من الأمثلة.
تنسيق ملف CSV هو تنسيق شائع لتخزين البيانات الجدولية في نص عادي.
فمثلا:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
إذا كانت بياناتك تتلاءم مع الذاكرة ، فإن نفس طريقة Dataset.from_tensor_slices تعمل على القواميس ، مما يسمح باستيراد هذه البيانات بسهولة:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
هناك نهج أكثر قابلية للتوسع وهو التحميل من القرص حسب الضرورة.
توفر الوحدة النمطية tf.data طرقًا لاستخراج السجلات من واحد أو أكثر من ملفات CSV التي تتوافق مع RFC 4180 .
تعتبر الدالة experimental.make_csv_dataset .make_csv_dataset هي واجهة عالية المستوى لقراءة مجموعات من ملفات csv. وهو يدعم الاستدلال على نوع العمود والعديد من الميزات الأخرى ، مثل التجميع والخلط ، لجعل الاستخدام بسيطًا.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
يمكنك استخدام وسيطة select_columns إذا كنت تحتاج فقط إلى مجموعة فرعية من الأعمدة.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
هناك أيضًا فئة experimental.CsvDataset منخفضة المستوى .CsvDataset توفر تحكمًا أفضل في الحبيبات. لا يدعم الاستدلال بنوع العمود. بدلاً من ذلك ، يجب تحديد نوع كل عمود.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
إذا كانت بعض الأعمدة فارغة ، تسمح لك هذه الواجهة ذات المستوى المنخفض بتوفير القيم الافتراضية بدلاً من أنواع الأعمدة.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
بشكل افتراضي ، ينتج عن CsvDataset كل عمود من كل سطر من الملف ، وهو ما قد لا يكون مرغوبًا فيه ، على سبيل المثال إذا كان الملف يبدأ بسطر رأس يجب تجاهله ، أو إذا كانت بعض الأعمدة غير مطلوبة في الإدخال. يمكن إزالة هذه الأسطر والحقول باستخدام وسيطتي header و select_cols على التوالي.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
تستهلك مجموعات من الملفات
هناك العديد من مجموعات البيانات الموزعة كمجموعة من الملفات ، حيث يمثل كل ملف مثالاً.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
يحتوي الدليل الجذر على دليل لكل فئة:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
الملفات الموجودة في كل دليل فئة هي أمثلة:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
اقرأ البيانات باستخدام الدالة tf.io.read_file الملصق من المسار ، مع إرجاع أزواج (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
تجميع عناصر مجموعة البيانات
تجميع بسيط
أبسط شكل من أشكال تجميع n العناصر المتتالية لمجموعة البيانات في عنصر واحد. يقوم تحويل Dataset.batch() بهذا بالضبط ، مع نفس قيود عامل التشغيل tf.stack() ، المطبق على كل مكون من العناصر: على سبيل المثال ، لكل مكون i ، يجب أن يكون لجميع العناصر موتر من نفس الشكل بالضبط.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
بينما يحاول tf.data نشر معلومات الشكل ، ينتج عن الإعدادات الافتراضية لـ Dataset.batch حجم دُفعة غير معروف لأن الدُفعة الأخيرة قد لا تكون ممتلئة. لاحظ عدم None في الشكل:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
استخدم وسيطة drop_remainder لتجاهل تلك الدفعة الأخيرة ، والحصول على نشر الشكل الكامل:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
موترات الخلط مع الحشو
تعمل الوصفة أعلاه مع الموترات التي لها نفس الحجم. ومع ذلك ، فإن العديد من النماذج (مثل نماذج التسلسل) تعمل مع بيانات الإدخال التي يمكن أن يكون لها أحجام مختلفة (مثل تسلسلات ذات أطوال مختلفة). للتعامل مع هذه الحالة ، يمكّنك تحويل Dataset.padded_batch من تجميع الموترات ذات الشكل المختلف عن طريق تحديد واحد أو أكثر من الأبعاد التي قد تكون مبطنة فيها.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
يسمح لك تحويل Dataset.padded_batch بتعيين حشوة مختلفة لكل بُعد من كل مكون ، وقد يكون متغير الطول (يُشار إليه None في المثال أعلاه) أو بطول ثابت. من الممكن أيضًا تجاوز قيمة المساحة المتروكة ، والتي يتم تعيينها افتراضيًا على 0.
تدريبات سير العمل
معالجة عهود متعددة
تقدم tf.data API طريقتين رئيسيتين لمعالجة عدة فترات من نفس البيانات.
إن أبسط طريقة للتكرار عبر مجموعة بيانات في فترات متعددة هي استخدام تحويل Dataset.repeat() . أولاً ، أنشئ مجموعة بيانات من البيانات العملاقة:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
سيؤدي تطبيق تحويل Dataset.repeat() بدون وسيطات إلى تكرار الإدخال إلى أجل غير مسمى.
Dataset.repeat التحويل المتكرر لمجموعة البيانات حججها دون الإشارة إلى نهاية حقبة واحدة وبداية الحقبة التالية. لهذا السبب ، فإن تطبيق Dataset.batch تطبيقه بعد Dataset.repeat سوف ينتج عنه دفعات تمتد عبر حدود الحقبة:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
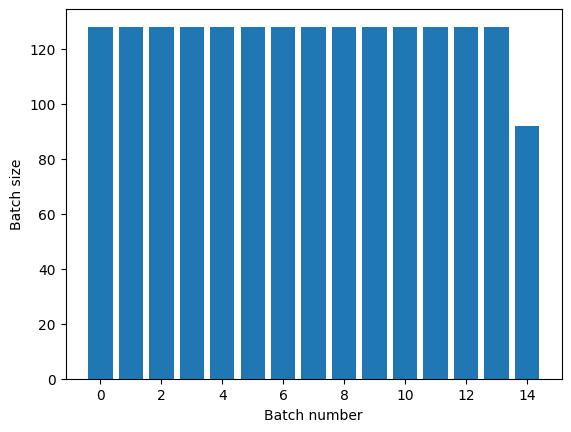
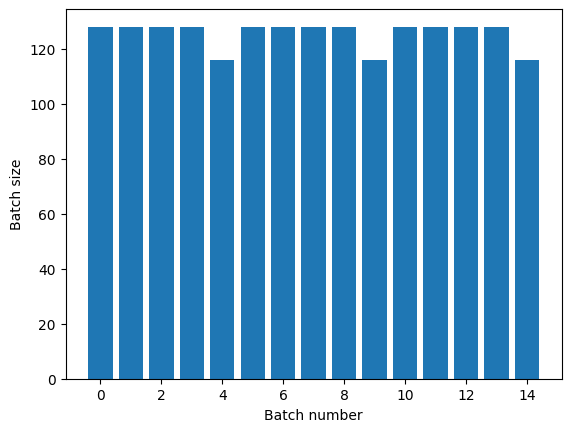
إذا كنت بحاجة إلى فصل واضح للحقبة ، فضع Dataset.batch قبل التكرار:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
إذا كنت ترغب في إجراء عملية حسابية مخصصة (على سبيل المثال لجمع الإحصائيات) في نهاية كل حقبة ، فمن الأسهل إعادة تشغيل تكرار مجموعة البيانات في كل فترة:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
خلط بيانات الإدخال عشوائيًا
يحافظ تحويل Dataset.shuffle() على مخزن مؤقت بحجم ثابت ويختار العنصر التالي بشكل موحد عشوائيًا من هذا المخزن المؤقت.
أضف فهرسًا إلى مجموعة البيانات حتى تتمكن من رؤية التأثير:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
نظرًا لأن buffer_size هو 100 ، وحجم الدُفعة هو 20 ، فإن الدفعة الأولى لا تحتوي على عناصر بمؤشر يزيد عن 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
كما هو الحال مع Dataset.batch ، فإن الترتيب المتعلق بـ Dataset.repeat مهم.
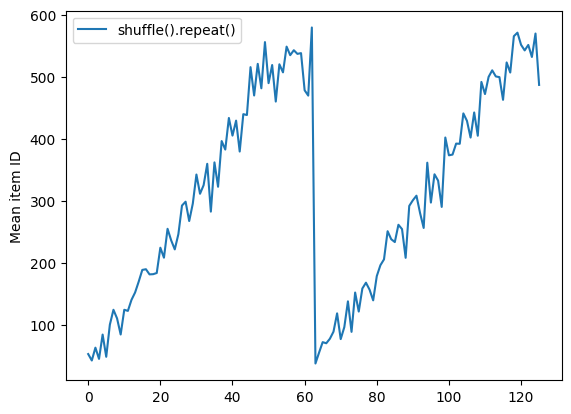
لا يشير Dataset.shuffle إلى نهاية حقبة حتى يصبح المخزن المؤقت عشوائيًا فارغًا. لذا فإن التبديل العشوائي الذي يتم وضعه قبل التكرار سيُظهر كل عنصر في حقبة واحدة قبل الانتقال إلى المرحلة التالية:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
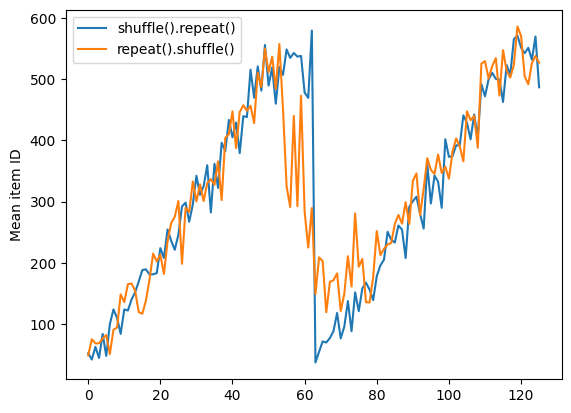
لكن التكرار قبل خلط ورق اللعب يمزج حدود العصر معًا:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
معالجة البيانات
ينتج عن تحويل Dataset.map(f) مجموعة بيانات جديدة من خلال تطبيق وظيفة معينة f على كل عنصر من عناصر مجموعة بيانات الإدخال. يعتمد على وظيفة map() التي يتم تطبيقها بشكل شائع على القوائم (وغيرها من الهياكل) في لغات البرمجة الوظيفية. تأخذ الوظيفة f كائنات tf.Tensor التي تمثل عنصرًا واحدًا في الإدخال ، وتعيد كائنات tf.Tensor التي ستمثل عنصرًا واحدًا في مجموعة البيانات الجديدة. يستخدم تنفيذه عمليات TensorFlow القياسية لتحويل عنصر إلى آخر.
يغطي هذا القسم أمثلة شائعة حول كيفية استخدام Dataset.map() .
فك بيانات الصورة وتغيير حجمها
عند تدريب شبكة عصبية على بيانات الصورة الواقعية ، غالبًا ما يكون من الضروري تحويل الصور ذات الأحجام المختلفة إلى حجم مشترك ، بحيث يمكن تجميعها في حجم ثابت.
إعادة إنشاء مجموعة بيانات أسماء ملفات الزهرة:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
اكتب دالة تعالج عناصر مجموعة البيانات.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
اختبار أنها تعمل.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

ضعها على مجموعة البيانات.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


تطبيق منطق بايثون التعسفي
لأسباب تتعلق بالأداء ، استخدم عمليات TensorFlow للمعالجة المسبقة لبياناتك كلما أمكن ذلك. ومع ذلك ، من المفيد أحيانًا استدعاء مكتبات Python الخارجية عند تحليل بيانات الإدخال. يمكنك استخدام العملية tf.py_function() Dataset.map() .
على سبيل المثال ، إذا كنت تريد تطبيق تدوير عشوائي ، فإن وحدة tf.image لها فقط tf.image.rot90 ، وهو أمر غير مفيد جدًا لتكبير الصورة.
لإثبات tf.py_function ، حاول استخدام الدالة scipy.ndimage.rotate بدلاً من ذلك:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

لاستخدام هذه الوظيفة مع Dataset.map ، تنطبق نفس التحذيرات كما هو الحال مع Dataset.from_generator ، تحتاج إلى وصف أشكال وأنواع الإرجاع عند تطبيق الوظيفة:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


تحليل رسائل المخزن المؤقت لبروتوكول tf.Example
العديد من خطوط أنابيب الإدخال تستخرج tf.train.Example بروتوكول رسائل المخزن المؤقت من تنسيق TFRecord. يحتوي كل سجل tf.train.Example على واحدة أو أكثر من "الميزات" ، وعادةً ما يحول مسار الإدخال هذه الميزات إلى موترات.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
يمكنك العمل مع tf.train.Example protos خارج tf.data.Dataset لفهم البيانات:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
نافذة السلسلة الزمنية
للحصول على مثال عن السلاسل الزمنية من نهاية إلى نهاية ، انظر: توقع السلاسل الزمنية .
غالبًا ما يتم تنظيم بيانات السلاسل الزمنية بحيث يكون المحور الزمني سليمًا.
استخدم نطاق مجموعة Dataset.range لتوضيح:
range_ds = tf.data.Dataset.range(100000)
عادةً ما تريد النماذج التي تستند إلى هذا النوع من البيانات شريحة زمنية متجاورة.
سيكون أبسط طريقة هي تجميع البيانات:
باستخدام batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
أو لعمل تنبؤات كثيفة خطوة واحدة إلى المستقبل ، يمكنك تغيير الميزات والتسميات بخطوة واحدة بالنسبة لبعضها البعض:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
للتنبؤ بنافذة كاملة بدلاً من الإزاحة الثابتة ، يمكنك تقسيم الدُفعات إلى جزأين:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
للسماح ببعض التداخل بين ميزات دفعة واحدة وتسميات أخرى ، استخدم Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
باستخدام window
أثناء استخدام أعمال Dataset.batch ، هناك مواقف قد تحتاج فيها إلى تحكم أكثر دقة. يمنحك أسلوب Dataset.window كاملاً ، ولكنه يتطلب بعض العناية: فهو يقوم بإرجاع مجموعة Dataset من Datasets . انظر هيكل مجموعة البيانات للحصول على التفاصيل.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
يمكن أن تأخذ طريقة Dataset.flat_map مجموعة بيانات من مجموعات البيانات وتسويتها في مجموعة بيانات واحدة:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
في جميع الحالات تقريبًا ، ستحتاج إلى .batch مجموعة البيانات أولاً:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
الآن ، يمكنك أن ترى أن وسيطة shift تتحكم في مقدار تحرك كل نافذة.
بتجميع هذا معًا ، يمكنك كتابة هذه الوظيفة:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
بعد ذلك يكون من السهل استخراج الملصقات ، كما كان من قبل:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
جارى الاختزال
عند العمل باستخدام مجموعة بيانات غير متوازنة للغاية في الفئة ، قد ترغب في إعادة تشكيل مجموعة البيانات. يوفر tf.data طريقتين للقيام بذلك. تعد مجموعة بيانات الاحتيال في بطاقة الائتمان مثالًا جيدًا على هذا النوع من المشاكل.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
الآن ، تحقق من توزيع الفئات ، فهو منحرف للغاية:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
النهج الشائع للتدريب باستخدام مجموعة بيانات غير متوازنة هو موازنة ذلك. يتضمن tf.data عدة طرق تمكّن سير العمل هذا:
أخذ عينات مجموعات البيانات
تتمثل إحدى طرق إعادة تشكيل مجموعة بيانات في استخدام sample_from_datasets . يكون هذا أكثر قابلية للتطبيق عندما يكون لديك مجموعة data.Dataset لكل فئة.
هنا ، ما عليك سوى استخدام عامل التصفية لإنشاءها من بيانات الاحتيال على بطاقة الائتمان:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
لاستخدام tf.data.Dataset.sample_from_datasets ، قم بتمرير مجموعات البيانات ووزن كل منها:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
تنتج مجموعة البيانات الآن أمثلة لكل فئة باحتمال 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
إعادة تشكيل الرفض
تتمثل إحدى مشكلات نهج Dataset.sample_from_datasets أعلاه في أنه يحتاج إلى tf.data.Dataset منفصل لكل فئة. يمكنك استخدام Dataset.filter لإنشاء مجموعتي البيانات هاتين ، ولكن ينتج عن ذلك تحميل جميع البيانات مرتين.
يمكن تطبيق طريقة data.Dataset.rejection_resample على مجموعة بيانات لإعادة توازنها ، مع تحميلها مرة واحدة فقط. سيتم إسقاط العناصر من مجموعة البيانات لتحقيق التوازن.
تأخذ data.Dataset.rejection_resample الوسيطة class_func . يتم تطبيق class_func هذا على كل عنصر من عناصر مجموعة البيانات ، ويتم استخدامه لتحديد الفئة التي ينتمي إليها المثال لأغراض الموازنة.
الهدف هنا هو موازنة توزيع lable ، وعناصر creditcard_ds هي بالفعل أزواج (features, label) . لذلك يحتاج class_func فقط إلى إرجاع تلك التسميات:
def class_func(features, label):
return label
تتعامل طريقة إعادة التشكيل مع أمثلة فردية ، لذلك في هذه الحالة يجب عليك unbatch مجموعة البيانات قبل تطبيق هذه الطريقة.
تحتاج الطريقة إلى توزيع مستهدف ، واختيارياً تقدير توزيع أولي كمدخلات.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
تقوم طريقة rejection_resample بإرجاع (class, example) أزواج حيث تكون class هي ناتج class_func . في هذه الحالة ، كان example بالفعل زوجًا (feature, label) ، لذا استخدم map لإسقاط النسخة الإضافية من الملصقات:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
تنتج مجموعة البيانات الآن أمثلة لكل فئة باحتمال 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
تكرارات التفتيش
يدعم Tensorflow أخذ نقاط التفتيش حتى يتمكن عند إعادة تشغيل عملية التدريب الخاصة بك من استعادة أحدث نقطة تفتيش لاستعادة معظم تقدمها. بالإضافة إلى تحديد متغيرات النموذج ، يمكنك أيضًا التحقق من تقدم مكرر مجموعة البيانات. قد يكون هذا مفيدًا إذا كان لديك مجموعة بيانات كبيرة ولا تريد بدء مجموعة البيانات من البداية في كل إعادة تشغيل. لاحظ مع ذلك أن نقاط فحص المكرر قد تكون كبيرة ، نظرًا لأن عمليات التحويل مثل shuffle prefetch تتطلب عناصر تخزين مؤقت داخل المكرر.
لتضمين المكرر في نقطة فحص ، قم بتمرير المكرر إلى tf.train.Checkpoint constructor.
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
استخدام tf.data مع tf.keras
تعمل واجهة برمجة تطبيقات tf.keras تبسيط العديد من جوانب إنشاء نماذج التعلم الآلي وتنفيذها. تدعم واجهات برمجة التطبيقات الخاصة بها .fit() () و .evaluate ( .evaluate() و .predict() مجموعات البيانات كمدخلات. فيما يلي مجموعة بيانات سريعة وإعداد نموذج:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
كل ما تحتاجه من أجل Model.fit و Model.evaluate هو تمرير مجموعة بيانات من أزواج (feature, label) :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
إذا قمت بتمرير مجموعة بيانات لا نهائية ، على سبيل المثال من خلال استدعاء Dataset.repeat() ، فأنت تحتاج فقط إلى تمرير وسيطة steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
للتقييم يمكنك اجتياز عدد خطوات التقييم:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
لمجموعات البيانات الطويلة ، عيّن عدد الخطوات المراد تقييمها:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
الملصقات غير مطلوبة عند استدعاء Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
ولكن يتم تجاهل التسميات إذا قمت بتمرير مجموعة بيانات تحتوي عليها:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)