
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce guide fournit un aperçu rapide des bases de TensorFlow . Chaque section de ce document est un aperçu d'un sujet plus vaste. Vous trouverez des liens vers des guides complets à la fin de chaque section.
TensorFlow est une plate-forme de bout en bout pour l'apprentissage automatique. Il prend en charge les éléments suivants :
- Calcul numérique basé sur un tableau multidimensionnel (similaire à NumPy .)
- GPU et traitement distribué
- Différenciation automatique
- Construction, formation et exportation de modèles
- Et plus
Tenseurs
TensorFlow fonctionne sur des tableaux multidimensionnels ou des tenseurs représentés sous forme d'objets tf.Tensor . Voici un tenseur bidimensionnel :
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
tf.Tensor( [[1. 2. 3.] [4. 5. 6.]], shape=(2, 3), dtype=float32) (2, 3) <dtype: 'float32'>
Les attributs les plus importants d'un tf.Tensor sont sa shape et son dtype :
-
Tensor.shape: vous indique la taille du tenseur le long de chacun de ses axes. -
Tensor.dtype: vous indique le type de tous les éléments du tenseur.
TensorFlow implémente des opérations mathématiques standard sur les tenseurs, ainsi que de nombreuses opérations spécialisées pour l'apprentissage automatique.
Par example:
x + x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 8., 10., 12.]], dtype=float32)>
5 * x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 5., 10., 15.],
[20., 25., 30.]], dtype=float32)>
x @ tf.transpose(x)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
tf.concat([x, x, x], axis=0)
<tf.Tensor: shape=(6, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
tf.nn.softmax(x, axis=-1)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.09003057, 0.24472848, 0.6652409 ],
[0.09003057, 0.24472848, 0.6652409 ]], dtype=float32)>
tf.reduce_sum(x)
<tf.Tensor: shape=(), dtype=float32, numpy=21.0>
L'exécution de calculs volumineux sur le processeur peut être lente. Lorsqu'il est correctement configuré, TensorFlow peut utiliser du matériel d'accélération comme les GPU pour exécuter des opérations très rapidement.
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
TensorFlow **IS** using the GPU
Reportez-vous au guide Tensor pour plus de détails.
variables
Les objets tf.Tensor normaux sont immuables. Pour stocker des poids de modèle (ou un autre état modifiable) dans TensorFlow, utilisez un tf.Variable .
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>
var.assign_add([1, 1, 1])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([2., 3., 4.], dtype=float32)>
Reportez-vous au guide des variables pour plus de détails.
Différenciation automatique
La descente de gradient et les algorithmes associés sont la pierre angulaire de l'apprentissage automatique moderne.
Pour ce faire, TensorFlow implémente la différenciation automatique (autodiff), qui utilise le calcul pour calculer les gradients. En règle générale, vous l'utiliserez pour calculer le gradient de l' erreur ou de la perte d'un modèle par rapport à ses poids.
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
<tf.Tensor: shape=(), dtype=float32, numpy=-2.0>
À x = 1.0 , y = f(x) = (1**2 + 2*1 - 5) = -2 .
La dérivée de y est y' = f'(x) = (2*x + 2) = 4 . TensorFlow peut calculer cela automatiquement :
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
Cet exemple simplifié ne prend que la dérivée par rapport à un seul scalaire ( x ), mais TensorFlow peut calculer le gradient par rapport à n'importe quel nombre de tenseurs non scalaires simultanément.
Reportez-vous au guide Autodiff pour plus de détails.
Graphiques et fonction tf
Bien que vous puissiez utiliser TensorFlow de manière interactive comme n'importe quelle bibliothèque Python, TensorFlow fournit également des outils pour :
- Optimisation des performances : pour accélérer l'apprentissage et l'inférence.
- Exporter : pour que vous puissiez enregistrer votre modèle une fois l'entraînement terminé.
Celles-ci nécessitent que vous tf.function pour séparer votre code TensorFlow pur de Python.
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
La première fois que vous exécutez la tf.function , bien qu'elle s'exécute en Python, elle capture un graphique complet et optimisé représentant les calculs TensorFlow effectués dans la fonction.
x = tf.constant([1, 2, 3])
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=int32, numpy=6>
Lors des appels suivants, TensorFlow n'exécute que le graphique optimisé, en sautant toutes les étapes non TensorFlow. Ci-dessous, notez que my_func pas le traçage puisque print est une fonction Python, pas une fonction TensorFlow.
x = tf.constant([10, 9, 8])
my_func(x)
<tf.Tensor: shape=(), dtype=int32, numpy=27>
Un graphe peut ne pas être réutilisable pour des entrées avec une signature différente ( shape et dtype ), donc un nouveau graphe est généré à la place :
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=float32, numpy=27.3>
Ces graphiques capturés offrent deux avantages :
- Dans de nombreux cas, ils fournissent une accélération significative de l'exécution (mais pas cet exemple trivial).
- Vous pouvez exporter ces graphiques, en utilisant
tf.saved_model, pour les exécuter sur d'autres systèmes comme un serveur ou un appareil mobile , aucune installation Python requise.
Reportez-vous à Introduction aux graphiques pour plus de détails.
Modules, couches et modèles
tf.Module est une classe pour gérer vos objets tf.Variable et les objets tf.function qui fonctionnent sur eux. La classe tf.Module est nécessaire pour prendre en charge deux fonctionnalités importantes :
- Vous pouvez enregistrer et restaurer les valeurs de vos variables en utilisant
tf.train.Checkpoint. Ceci est utile pendant la formation car il est rapide d'enregistrer et de restaurer l'état d'un modèle. - Vous pouvez importer et exporter les valeurs
tf.Variableet les graphiquestf.functionà l'aidetf.saved_model. Cela vous permet d'exécuter votre modèle indépendamment du programme Python qui l'a créé.
Voici un exemple complet exportant un simple objet tf.Module :
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Enregistrez le Module :
save_path = './saved'
tf.saved_model.save(mod, save_path)
INFO:tensorflow:Assets written to: ./saved/assets 2022-01-19 02:29:48.135588: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
Le SavedModel résultant est indépendant du code qui l'a créé. Vous pouvez charger un SavedModel à partir de Python, d'autres liaisons de langage ou de TensorFlow Serving . Vous pouvez également le convertir pour qu'il s'exécute avec TensorFlow Lite ou TensorFlow JS .
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Les classes tf.keras.layers.Layer et tf.keras.Model s'appuient sur tf.Module , fournissant des fonctionnalités supplémentaires et des méthodes pratiques pour créer, former et enregistrer des modèles. Certains d'entre eux sont démontrés dans la section suivante.
Reportez-vous à l' Introduction aux modules pour plus de détails.
Boucles d'entraînement
Maintenant, rassemblez tout cela pour créer un modèle de base et entraînez-le à partir de zéro.
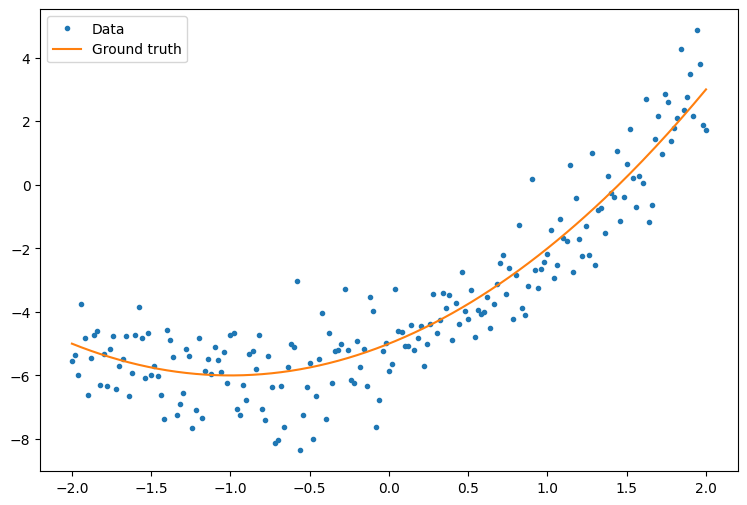
Tout d'abord, créez des exemples de données. Cela génère un nuage de points qui suit vaguement une courbe quadratique :
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
Créez un modèle :
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();

Rédigez une boucle d'entraînement de base :
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
Mean squared error: 16.123 Mean squared error: 0.997 Mean squared error: 0.964 Mean squared error: 0.946 Mean squared error: 0.932 Mean squared error: 0.921 Mean squared error: 0.913 Mean squared error: 0.907 Mean squared error: 0.901 Mean squared error: 0.897
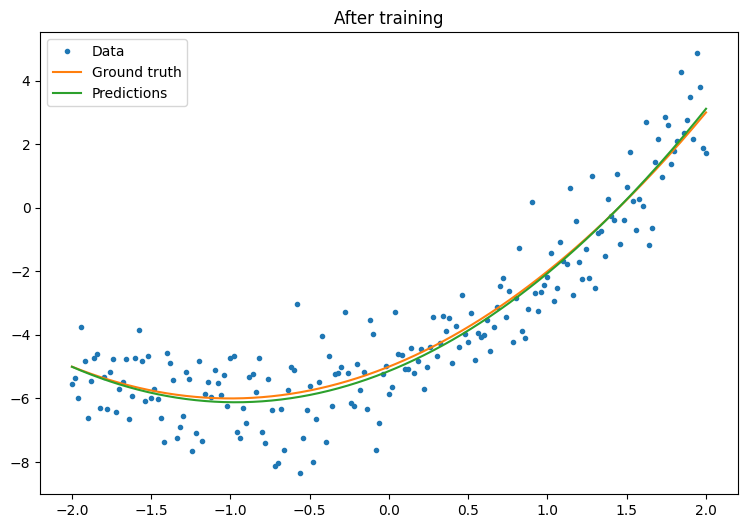
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
Cela fonctionne, mais rappelez-vous que les implémentations d'utilitaires de formation courants sont disponibles dans le module tf.keras . Pensez donc à les utiliser avant d'écrire les vôtres. Pour commencer, les méthodes Model.compile et Model.fit implémentent pour vous une boucle d'apprentissage :
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
INFO:tensorflow:Assets written to: ./my_model/assets
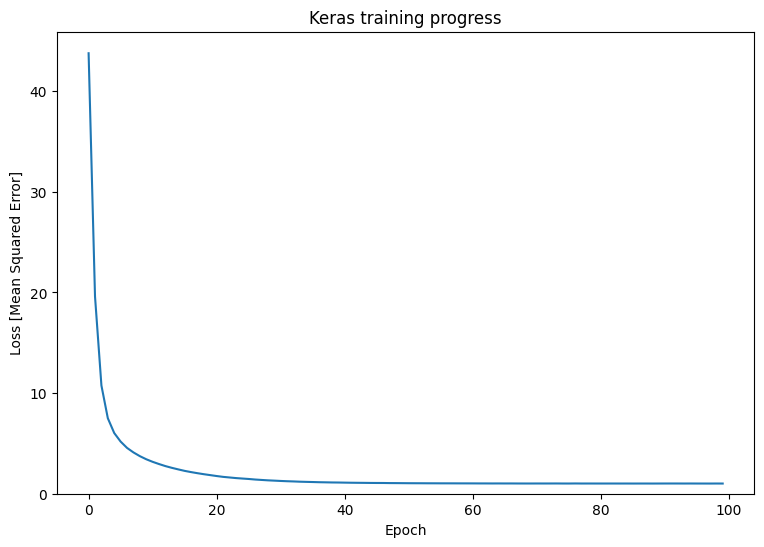
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
Reportez-vous aux boucles d'entraînement de base et au guide Keras pour plus de détails.