
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Esta guía proporciona una descripción general rápida de los conceptos básicos de TensorFlow . Cada sección de este documento es una descripción general de un tema más amplio; puede encontrar enlaces a guías completas al final de cada sección.
TensorFlow es una plataforma integral para el aprendizaje automático. Es compatible con lo siguiente:
- Cálculo numérico basado en matrices multidimensionales (similar a NumPy ).
- GPU y procesamiento distribuido
- Diferenciación automática
- Construcción, capacitación y exportación de modelos.
- Y más
tensores
TensorFlow opera en arreglos multidimensionales o tensores representados como objetos tf.Tensor . Aquí hay un tensor bidimensional:
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
tf.Tensor( [[1. 2. 3.] [4. 5. 6.]], shape=(2, 3), dtype=float32) (2, 3) <dtype: 'float32'>
Los atributos más importantes de un tf.Tensor son su shape y dtype :
-
Tensor.shape: te dice el tamaño del tensor a lo largo de cada uno de sus ejes. -
Tensor.dtype: te dice el tipo de todos los elementos en el tensor.
TensorFlow implementa operaciones matemáticas estándar en tensores, así como muchas operaciones especializadas para el aprendizaje automático.
Por ejemplo:
x + x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 8., 10., 12.]], dtype=float32)>
5 * x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 5., 10., 15.],
[20., 25., 30.]], dtype=float32)>
x @ tf.transpose(x)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
tf.concat([x, x, x], axis=0)
<tf.Tensor: shape=(6, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
tf.nn.softmax(x, axis=-1)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.09003057, 0.24472848, 0.6652409 ],
[0.09003057, 0.24472848, 0.6652409 ]], dtype=float32)>
tf.reduce_sum(x)
<tf.Tensor: shape=(), dtype=float32, numpy=21.0>
Ejecutar cálculos grandes en la CPU puede ser lento. Cuando está configurado correctamente, TensorFlow puede usar hardware acelerador como GPU para ejecutar operaciones muy rápidamente.
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
TensorFlow **IS** using the GPU
Consulte la guía Tensor para obtener más información.
Variables
Los objetos tf.Tensor normales son inmutables. Para almacenar pesos de modelos (u otro estado mutable) en TensorFlow, usa tf.Variable .
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>
var.assign_add([1, 1, 1])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([2., 3., 4.], dtype=float32)>
Consulte la guía de variables para obtener más detalles.
Diferenciación automática
El descenso de gradiente y los algoritmos relacionados son la piedra angular del aprendizaje automático moderno.
Para habilitar esto, TensorFlow implementa la diferenciación automática (autodiff), que usa cálculo para calcular gradientes. Por lo general, usará esto para calcular el gradiente de error o pérdida de un modelo con respecto a sus pesos.
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
<tf.Tensor: shape=(), dtype=float32, numpy=-2.0>
En x = 1.0 , y = f(x) = (1**2 + 2*1 - 5) = -2 .
La derivada de y es y' = f'(x) = (2*x + 2) = 4 . TensorFlow puede calcular esto automáticamente:
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
Este ejemplo simplificado solo toma la derivada con respecto a un solo escalar ( x ), pero TensorFlow puede calcular el gradiente con respecto a cualquier número de tensores no escalares simultáneamente.
Consulte la guía Autodiff para obtener más detalles.
Gráficos y función tf.
Si bien puede usar TensorFlow de forma interactiva como cualquier biblioteca de Python, TensorFlow también proporciona herramientas para:
- Optimización del rendimiento : para acelerar el entrenamiento y la inferencia.
- Exportar : para que pueda guardar su modelo cuando termine de entrenar.
Estos requieren que use tf.function para separar su código TensorFlow puro de Python.
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
La primera vez que ejecuta tf.function , aunque se ejecuta en Python, captura un gráfico completo y optimizado que representa los cálculos de TensorFlow realizados dentro de la función.
x = tf.constant([1, 2, 3])
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=int32, numpy=6>
En llamadas posteriores, TensorFlow solo ejecuta el gráfico optimizado y omite cualquier paso que no sea de TensorFlow. A continuación, tenga en cuenta que my_func no imprime el seguimiento ya que print es una función de Python, no una función de TensorFlow.
x = tf.constant([10, 9, 8])
my_func(x)
<tf.Tensor: shape=(), dtype=int32, numpy=27>
Es posible que un gráfico no se pueda reutilizar para entradas con una firma diferente ( shape y dtype ), por lo que se genera un nuevo gráfico en su lugar:
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=float32, numpy=27.3>
Estos gráficos capturados brindan dos beneficios:
- En muchos casos, proporcionan una aceleración significativa en la ejecución (aunque no en este ejemplo trivial).
- Puede exportar estos gráficos, utilizando
tf.saved_model, para ejecutarlos en otros sistemas, como un servidor o un dispositivo móvil , sin necesidad de instalar Python.
Consulte Introducción a los gráficos para obtener más detalles.
Módulos, capas y modelos.
tf.Module es una clase para administrar sus objetos tf.Variable y los objetos tf.function que operan en ellos. La clase tf.Module es necesaria para admitir dos funciones importantes:
- Puede guardar y restaurar los valores de sus variables usando
tf.train.Checkpoint. Esto es útil durante el entrenamiento, ya que es rápido guardar y restaurar el estado de un modelo. - Puede importar y exportar los valores de
tf.Variabley los gráficos detf.functionusandotf.saved_model. Esto le permite ejecutar su modelo independientemente del programa de Python que lo creó.
Aquí hay un ejemplo completo exportando un objeto tf.Module simple:
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Guarde el Module :
save_path = './saved'
tf.saved_model.save(mod, save_path)
INFO:tensorflow:Assets written to: ./saved/assets 2022-01-19 02:29:48.135588: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
El modelo guardado resultante es independiente del código que lo creó. Puede cargar un modelo guardado desde Python, otros enlaces de idioma o TensorFlow Serving . También puede convertirlo para que se ejecute con TensorFlow Lite o TensorFlow JS .
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Las clases tf.keras.layers.Layer y tf.keras.Model se basan en tf.Module y brindan funcionalidad adicional y métodos convenientes para crear, entrenar y guardar modelos. Algunos de estos se muestran en la siguiente sección.
Consulte Introducción a los módulos para obtener más detalles.
Bucles de entrenamiento
Ahora junte todo esto para construir un modelo básico y entrénelo desde cero.
Primero, cree algunos datos de ejemplo. Esto genera una nube de puntos que sigue vagamente una curva cuadrática:
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
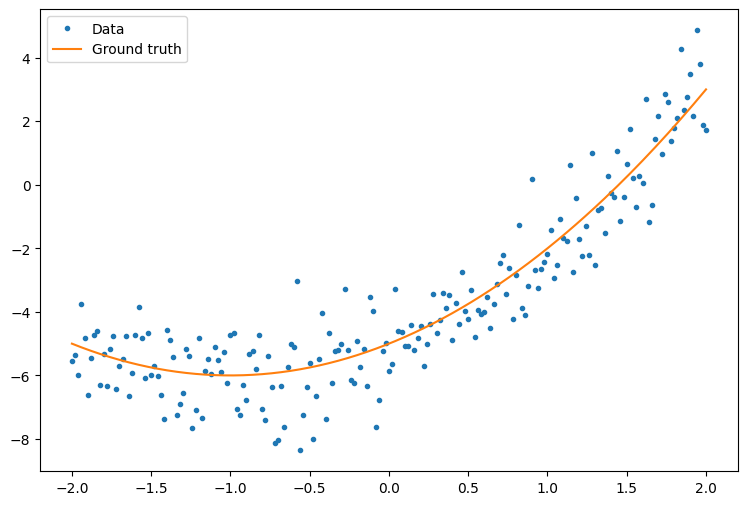
Crea un modelo:
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();

Escribe un bucle de entrenamiento básico:
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
Mean squared error: 16.123 Mean squared error: 0.997 Mean squared error: 0.964 Mean squared error: 0.946 Mean squared error: 0.932 Mean squared error: 0.921 Mean squared error: 0.913 Mean squared error: 0.907 Mean squared error: 0.901 Mean squared error: 0.897
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
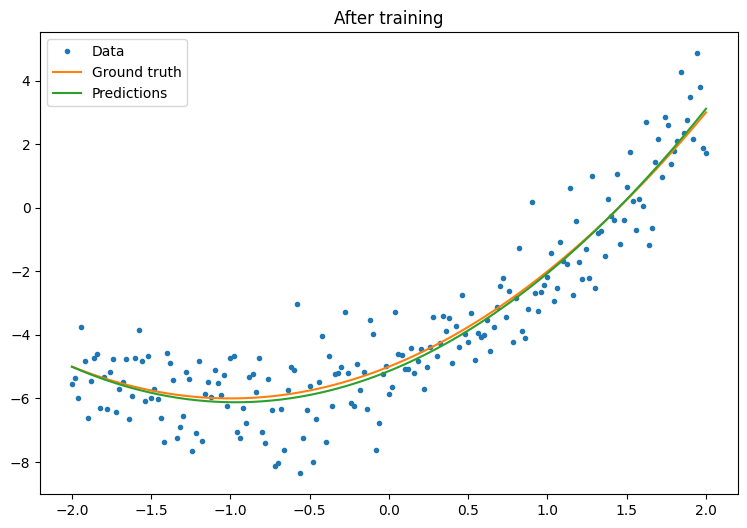
Eso está funcionando, pero recuerde que las implementaciones de utilidades de entrenamiento comunes están disponibles en el módulo tf.keras . Así que considere usarlos antes de escribir los suyos propios. Para empezar, los métodos Model.compile y Model.fit implementan un ciclo de entrenamiento para usted:
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
INFO:tensorflow:Assets written to: ./my_model/assets
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
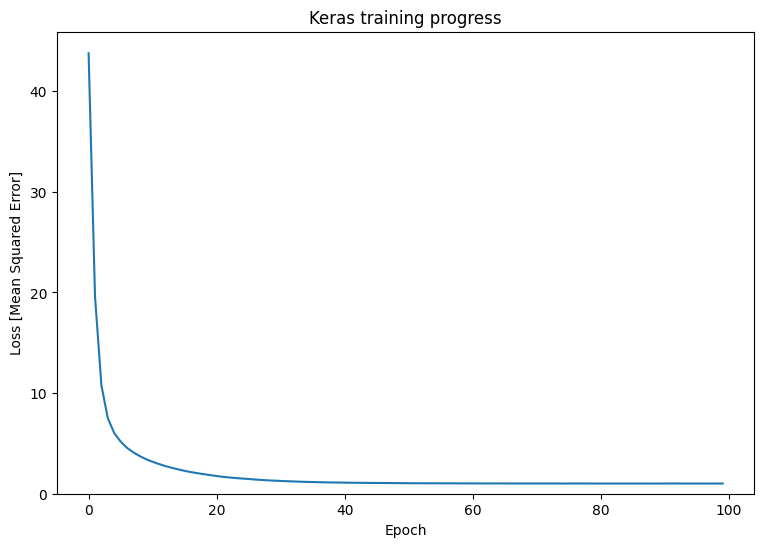
Consulte Bucles de entrenamiento básicos y la guía de Keras para obtener más detalles.