
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten przewodnik zawiera krótki przegląd podstaw TensorFlow . Każda sekcja tego dokumentu jest przeglądem większego tematu — linki do pełnych przewodników można znaleźć na końcu każdej sekcji.
TensorFlow to kompleksowa platforma do uczenia maszynowego. Obsługuje:
- Obliczenia numeryczne oparte na wielowymiarowych tablicach (podobne do NumPy .)
- GPU i przetwarzanie rozproszone
- Automatyczne różnicowanie
- Budowa modeli, szkolenia i eksport
- I więcej
Tensory
TensorFlow działa na wielowymiarowych tablicach lub tensorach reprezentowanych jako obiekty tf.Tensor . Oto dwuwymiarowy tensor:
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
tf.Tensor( [[1. 2. 3.] [4. 5. 6.]], shape=(2, 3), dtype=float32) (2, 3) <dtype: 'float32'>
Najważniejszymi atrybutami tf.Tensor są jego shape i dtype :
-
Tensor.shape: informuje o rozmiarze tensora wzdłuż każdej z jego osi. -
Tensor.dtype: informuje o typie wszystkich elementów w tensorze.
TensorFlow implementuje standardowe operacje matematyczne na tensorach, a także wiele operacji wyspecjalizowanych w uczeniu maszynowym.
Na przykład:
x + x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 8., 10., 12.]], dtype=float32)>
5 * x
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[ 5., 10., 15.],
[20., 25., 30.]], dtype=float32)>
x @ tf.transpose(x)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[14., 32.],
[32., 77.]], dtype=float32)>
tf.concat([x, x, x], axis=0)
<tf.Tensor: shape=(6, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.],
[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
tf.nn.softmax(x, axis=-1)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.09003057, 0.24472848, 0.6652409 ],
[0.09003057, 0.24472848, 0.6652409 ]], dtype=float32)>
tf.reduce_sum(x)
<tf.Tensor: shape=(), dtype=float32, numpy=21.0>
Uruchamianie dużych obliczeń na procesorze może być powolne. Po prawidłowym skonfigurowaniu TensorFlow może używać sprzętu akceleracyjnego, takiego jak procesory graficzne, do bardzo szybkiego wykonywania operacji.
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
TensorFlow **IS** using the GPU
Szczegółowe informacje można znaleźć w przewodniku dotyczącym tensorów.
Zmienne
Normalne obiekty tf.Tensor są niezmienne. Aby przechowywać wagi modeli (lub inny zmienny stan) w TensorFlow, użyj tf.Variable .
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>
var.assign_add([1, 1, 1])
<tf.Variable 'UnreadVariable' shape=(3,) dtype=float32, numpy=array([2., 3., 4.], dtype=float32)>
Szczegółowe informacje można znaleźć w przewodniku dotyczącym zmiennych .
Automatyczne różnicowanie
Pochodzenie gradientowe i powiązane algorytmy są podstawą nowoczesnego uczenia maszynowego.
Aby to umożliwić, TensorFlow implementuje automatyczne różnicowanie (autodiff), które wykorzystuje rachunek różniczkowy do obliczania gradientów. Zazwyczaj użyjesz tego do obliczenia gradientu błędu lub straty modelu w odniesieniu do jego wag.
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
<tf.Tensor: shape=(), dtype=float32, numpy=-2.0>
Przy x = 1.0 , y = f(x) = (1**2 + 2*1 - 5) = -2 .
Pochodna y to y' = f'(x) = (2*x + 2) = 4 . TensorFlow może to obliczyć automatycznie:
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
Ten uproszczony przykład bierze pochodną tylko w odniesieniu do pojedynczego skalara ( x ), ale TensorFlow może obliczyć gradient w odniesieniu do dowolnej liczby nieskalarnych tensorów jednocześnie.
Szczegółowe informacje można znaleźć w przewodniku Autodiff .
Wykresy i funkcja tf.
Chociaż możesz używać TensorFlow interaktywnie jak każdej biblioteki Pythona, TensorFlow zapewnia również narzędzia do:
- Optymalizacja wydajności : aby przyspieszyć szkolenie i wnioskowanie.
- Eksportuj : dzięki czemu możesz zapisać swój model po zakończeniu treningu.
Wymagają one użycia tf.function do oddzielenia kodu czystego TensorFlow od Pythona.
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
Przy pierwszym uruchomieniu tf.function , mimo że jest ona wykonywana w Pythonie, przechwytuje ona kompletny, zoptymalizowany wykres przedstawiający obliczenia TensorFlow wykonane w ramach funkcji.
x = tf.constant([1, 2, 3])
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=int32, numpy=6>
Przy kolejnych wywołaniach TensorFlow wykonuje tylko zoptymalizowany wykres, pomijając wszelkie kroki inne niż TensorFlow. Poniżej zauważ, że my_func nie drukuje śledzenia , ponieważ print jest funkcją Pythona, a nie funkcją TensorFlow.
x = tf.constant([10, 9, 8])
my_func(x)
<tf.Tensor: shape=(), dtype=int32, numpy=27>
Wykres może nie nadawać się do ponownego wykorzystania dla danych wejściowych o innej sygnaturze ( shape i dtype ), dlatego zamiast tego generowany jest nowy wykres:
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
Tracing. <tf.Tensor: shape=(), dtype=float32, numpy=27.3>
Te przechwycone wykresy zapewniają dwie korzyści:
- W wielu przypadkach zapewniają one znaczne przyspieszenie wykonania (choć nie ten trywialny przykład).
- Możesz wyeksportować te wykresy, używając
tf.saved_model, aby działały w innych systemach, takich jak serwer lub urządzenie mobilne , bez konieczności instalacji Pythona.
Więcej informacji można znaleźć we wstępie do wykresów .
Moduły, warstwy i modele
tf.Module to klasa do zarządzania obiektami tf.Variable i obiektami tf.function , które na nich operują. Klasa tf.Module jest niezbędna do obsługi dwóch istotnych funkcji:
- Możesz zapisać i przywrócić wartości swoich zmiennych za pomocą
tf.train.Checkpoint. Jest to przydatne podczas uczenia, ponieważ umożliwia szybkie zapisanie i przywrócenie stanu modelu. - Możesz importować i eksportować wartości
tf.Variableoraz wykresytf.functionza pomocątf.saved_model. Pozwala to na uruchamianie modelu niezależnie od programu w Pythonie, który go utworzył.
Oto kompletny przykład eksportowania prostego obiektu tf.Module :
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
Zapisz Module :
save_path = './saved'
tf.saved_model.save(mod, save_path)
INFO:tensorflow:Assets written to: ./saved/assets 2022-01-19 02:29:48.135588: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
Wynikowy SavedModel jest niezależny od kodu, który go utworzył. Możesz załadować SavedModel z Pythona, innych powiązań językowych lub TensorFlow Serving . Możesz również przekonwertować go, aby działał z TensorFlow Lite lub TensorFlow JS .
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 6, 9], dtype=int32)>
tf.keras.layers.Layer i tf.keras.Model opierają się na tf.Module zapewniając dodatkowe funkcje i wygodne metody budowania, trenowania i zapisywania modeli. Niektóre z nich przedstawiono w następnej sekcji.
Aby uzyskać szczegółowe informacje, zapoznaj się z wprowadzeniem do modułów .
Pętle treningowe
Teraz złóż to wszystko razem, aby zbudować podstawowy model i wytrenuj go od podstaw.
Najpierw utwórz przykładowe dane. To generuje chmurę punktów, która luźno podąża za krzywą kwadratową:
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
Utwórz model:
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();

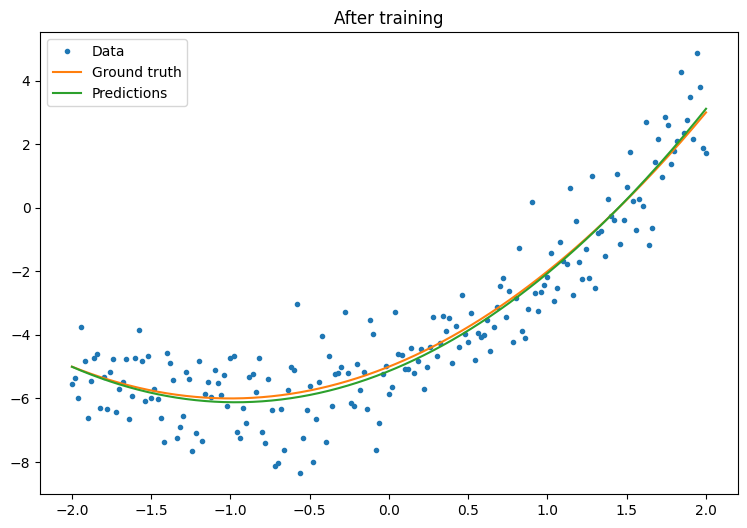
Napisz podstawową pętlę treningową:
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
Mean squared error: 16.123 Mean squared error: 0.997 Mean squared error: 0.964 Mean squared error: 0.946 Mean squared error: 0.932 Mean squared error: 0.921 Mean squared error: 0.913 Mean squared error: 0.907 Mean squared error: 0.901 Mean squared error: 0.897
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
To działa, ale pamiętaj, że implementacje popularnych narzędzi szkoleniowych są dostępne w module tf.keras . Zastanów się więc nad ich użyciem, zanim napiszesz własne. Na początek metody Model.compile i Model.fit implementują pętlę treningową:
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
INFO:tensorflow:Assets written to: ./my_model/assets
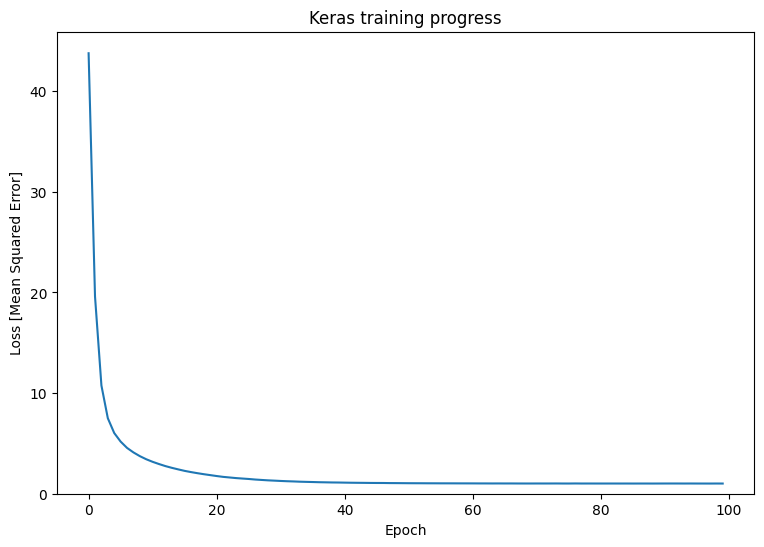
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
Zapoznaj się z podstawowymi pętlami treningowymi i przewodnikiem Keras, aby uzyskać więcej informacji.