
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Diferenciação Automática e Gradientes
A diferenciação automática é útil para implementar algoritmos de aprendizado de máquina, como retropropagação , para treinar redes neurais.
Neste guia, você explorará maneiras de calcular gradientes com o TensorFlow, especialmente na execução antecipada.
Configurar
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Gradientes de computação
Para diferenciar automaticamente, o TensorFlow precisa lembrar quais operações acontecem em qual ordem durante a passagem direta . Em seguida, durante a passagem para trás , o TensorFlow percorre essa lista de operações na ordem inversa para calcular gradientes.
Fitas de gradiente
O TensorFlow fornece a API tf.GradientTape para diferenciação automática; isto é, calcular o gradiente de uma computação em relação a algumas entradas, geralmente tf.Variable s. O TensorFlow "grava" as operações relevantes executadas dentro do contexto de um tf.GradientTape em uma "fita". O TensorFlow usa essa fita para calcular os gradientes de uma computação "gravada" usando a diferenciação de modo reverso .
Aqui está um exemplo simples:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Depois de registrar algumas operações, use GradientTape.gradient(target, sources) para calcular o gradiente de algum destino (geralmente uma perda) em relação a alguma fonte (geralmente as variáveis do modelo):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
O exemplo acima usa escalares, mas tf.GradientTape funciona facilmente em qualquer tensor:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Para obter o gradiente de loss em relação a ambas as variáveis, você pode passar ambas como fontes para o método gradient . A fita é flexível sobre como as fontes são passadas e aceitará qualquer combinação aninhada de listas ou dicionários e retornará o gradiente estruturado da mesma maneira (consulte tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
O gradiente em relação a cada fonte tem a forma da fonte:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
Aqui está o cálculo do gradiente novamente, desta vez passando um dicionário de variáveis:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Gradientes em relação a um modelo
É comum coletar tf.Variables em um tf.Module ou em uma de suas subclasses ( layers.Layer , keras.Model ) para verificação e exportação .
Na maioria dos casos, você desejará calcular gradientes em relação às variáveis treináveis de um modelo. Como todas as subclasses de tf.Module agregam suas variáveis na propriedade Module.trainable_variables , você pode calcular esses gradientes em poucas linhas de código:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Controlando o que a fita assiste
O comportamento padrão é gravar todas as operações após acessar uma tf.Variable treinável. As razões para isso são:
- A fita precisa saber quais operações gravar na passagem para frente para calcular os gradientes na passagem para trás.
- A fita contém referências a saídas intermediárias, portanto, você não deseja gravar operações desnecessárias.
- O caso de uso mais comum envolve o cálculo do gradiente de uma perda em relação a todas as variáveis treináveis de um modelo.
Por exemplo, o seguinte falha ao calcular um gradiente porque o tf.Tensor não é "observado" por padrão e o tf.Variable não é treinável:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
Você pode listar as variáveis que estão sendo observadas pela fita usando o método GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape fornece ganchos que dão ao usuário controle sobre o que é ou não observado.
Para gravar gradientes em relação a um tf.Tensor , você precisa chamar GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Por outro lado, para desabilitar o comportamento padrão de observar todos os tf.Variables , defina watch_accessed_variables=False ao criar a fita gradiente. Este cálculo usa duas variáveis, mas apenas conecta o gradiente para uma das variáveis:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
Como GradientTape.watch não foi chamado em x0 , nenhum gradiente é calculado em relação a ele:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
Resultados intermediários
Você também pode solicitar gradientes da saída em relação a valores intermediários calculados dentro do contexto tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
Por padrão, os recursos mantidos por um GradientTape são liberados assim que o método GradientTape.gradient é chamado. Para calcular vários gradientes no mesmo cálculo, crie uma fita de gradiente com persistent=True . Isso permite várias chamadas para o método gradient à medida que os recursos são liberados quando o objeto de fita é coletado como lixo. Por exemplo:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
Notas sobre o desempenho
Há uma pequena sobrecarga associada à execução de operações dentro de um contexto de fita de gradiente. Para a execução mais rápida, isso não será um custo perceptível, mas você ainda deve usar o contexto de fita nas áreas apenas onde for necessário.
As fitas de gradiente usam memória para armazenar resultados intermediários, incluindo entradas e saídas, para uso durante a passagem para trás.
Para eficiência, algumas operações (como
ReLU) não precisam manter seus resultados intermediários e são podadas durante o passe para frente. No entanto, se você usarpersistent=Trueem sua fita, nada será descartado e seu pico de uso de memória será maior.
Gradientes de alvos não escalares
Um gradiente é fundamentalmente uma operação em um escalar.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Assim, se você solicitar o gradiente de vários alvos, o resultado para cada fonte será:
- O gradiente da soma dos alvos, ou equivalentemente
- A soma dos gradientes de cada alvo.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
Da mesma forma, se os alvos não forem escalares, o gradiente da soma é calculado:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Isso simplifica a obtenção do gradiente da soma de uma coleção de perdas ou o gradiente da soma de um cálculo de perda por elemento.
Se você precisar de um gradiente separado para cada item, consulte Jacobians .
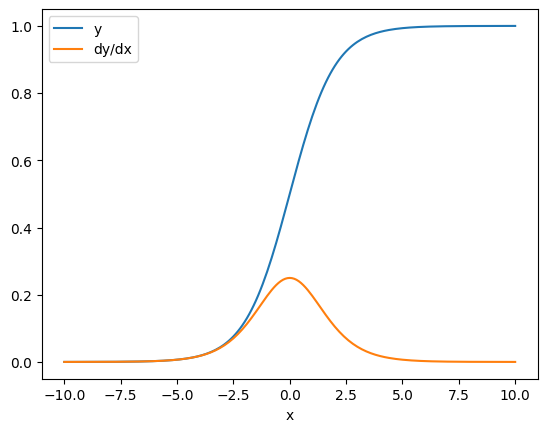
Em alguns casos, você pode pular o jacobiano. Para um cálculo elementar, o gradiente da soma fornece a derivada de cada elemento em relação ao seu elemento de entrada, uma vez que cada elemento é independente:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Controle de fluxo
Como uma fita de gradiente grava as operações à medida que são executadas, o fluxo de controle do Python é tratado naturalmente (por exemplo, instruções if e while ).
Aqui, uma variável diferente é usada em cada ramificação de um if . O gradiente só se conecta à variável que foi usada:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Apenas lembre-se de que as próprias instruções de controle não são diferenciáveis, portanto, são invisíveis para otimizadores baseados em gradiente.
Dependendo do valor de x no exemplo acima, a fita grava result = v0 ou result = v1**2 . O gradiente em relação a x é sempre None .
dx = tape.gradient(result, x)
print(dx)
None
Obtendo um gradiente de None
Quando um destino não está conectado a uma fonte, você obterá um gradiente de None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Aqui z obviamente não está conectado a x , mas existem várias maneiras menos óbvias de desconectar um gradiente.
1. Substituiu uma variável por um tensor
Na seção sobre "controlar o que a fita assiste" , você viu que a fita assistirá automaticamente a um tf.Variable mas não a um tf.Tensor .
Um erro comum é substituir inadvertidamente um tf.Variable por um tf.Tensor , em vez de usar Variable.assign para atualizar o tf.Variable . Aqui está um exemplo:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Fez cálculos fora do TensorFlow
A fita não pode gravar o caminho do gradiente se o cálculo sair do TensorFlow. Por exemplo:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Tomou gradientes por meio de um inteiro ou string
Inteiros e strings não são diferenciáveis. Se um caminho de cálculo usar esses tipos de dados, não haverá gradiente.
Ninguém espera que as strings sejam diferenciáveis, mas é fácil criar acidentalmente uma constante ou variável int se você não especificar o dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
O TensorFlow não converte automaticamente entre os tipos, portanto, na prática, muitas vezes você receberá um erro de tipo em vez de um gradiente ausente.
4. Levou gradientes por meio de um objeto com estado
O estado pára gradientes. Quando você lê de um objeto com estado, a fita só pode observar o estado atual, não o histórico que leva a ele.
Um tf.Tensor é imutável. Você não pode alterar um tensor depois de criado. Tem um valor , mas nenhum estado . Todas as operações discutidas até agora também são stateless: a saída de um tf.matmul depende apenas de suas entradas.
Uma tf.Variable tem um estado interno—seu valor. Quando você usa a variável, o estado é lido. É normal calcular um gradiente em relação a uma variável, mas o estado da variável impede que os cálculos de gradiente voltem mais para trás. Por exemplo:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
Da mesma forma, os iteradores tf.data.Dataset e tf.queue s são stateful e param todos os gradientes nos tensores que passam por eles.
Nenhum gradiente registrado
Alguns tf.Operation s são registrados como não diferenciáveis e retornarão None . Outros não possuem gradiente registrado .
A página tf.raw_ops mostra quais operações de baixo nível têm gradientes registrados.
Se você tentar obter um gradiente por meio de uma operação flutuante que não tenha gradiente registrado, a fita gerará um erro em vez de retornar silenciosamente None . Dessa forma, você sabe que algo deu errado.
Por exemplo, a função tf.image.adjust_contrast envolve raw_ops.AdjustContrastv2 , que pode ter um gradiente, mas o gradiente não é implementado:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Se você precisar diferenciar por meio dessa operação, precisará implementar o gradiente e registrá-lo (usando tf.RegisterGradient ) ou reimplementar a função usando outras operações.
Zeros em vez de Nenhum
Em alguns casos, seria conveniente obter 0 em vez de None para gradientes desconectados. Você pode decidir o que retornar quando tiver gradientes desconectados usando o argumento unconnected_gradients :
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)