
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
स्वचालित भेदभाव और ग्रेडिएंट
मशीन लर्निंग एल्गोरिदम को लागू करने के लिए स्वचालित भेदभाव उपयोगी है जैसे तंत्रिका नेटवर्क के प्रशिक्षण के लिए बैकप्रोपेगेशन ।
इस गाइड में, आप TensorFlow के साथ ग्रेडिएंट की गणना करने के तरीकों का पता लगाएंगे, विशेष रूप से उत्सुक निष्पादन में।
सेट अप
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
कंप्यूटिंग ग्रेडियेंट
स्वचालित रूप से अंतर करने के लिए, TensorFlow को यह याद रखने की आवश्यकता है कि फॉरवर्ड पास के दौरान किस क्रम में संचालन होता है। फिर, बैकवर्ड पास के दौरान, TensorFlow ग्रेडिएंट की गणना करने के लिए संचालन की इस सूची को उल्टे क्रम में पार करता है।
ढाल टेप
TensorFlow स्वचालित विभेदन के लिए tf.GradientTape API प्रदान करता है; अर्थात्, कुछ इनपुट के संबंध में एक अभिकलन के ग्रेडिएंट की गणना करना, आमतौर पर tf.Variable s। TensorFlow "टेप" पर tf.GradientTape के संदर्भ में निष्पादित प्रासंगिक संचालन "रिकॉर्ड" करता है। TensorFlow फिर उस टेप का उपयोग रिवर्स मोड भेदभाव का उपयोग करके "रिकॉर्डेड" गणना के ग्रेडियेंट की गणना करने के लिए करता है।
ये रहा एक सरल उदाहरण:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
एक बार जब आप कुछ संचालन रिकॉर्ड कर लेते हैं, तो कुछ स्रोत (अक्सर मॉडल के चर) के सापेक्ष कुछ लक्ष्य (अक्सर नुकसान) की ढाल की गणना करने के लिए GradientTape.gradient(target, sources) का उपयोग करें:
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
उपरोक्त उदाहरण स्केलर का उपयोग करता है, लेकिन tf.GradientTape किसी भी टेंसर पर आसानी से काम करता है:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
दोनों चर के संबंध में loss की ढाल प्राप्त करने के लिए, आप दोनों को स्रोत के रूप में gradient विधि में पारित कर सकते हैं। टेप इस बारे में लचीला है कि स्रोत कैसे पारित होते हैं और सूचियों या शब्दकोशों के किसी भी नेस्टेड संयोजन को स्वीकार करेंगे और उसी तरह संरचित ढाल को वापस कर देंगे (देखें tf.nest )।
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
प्रत्येक स्रोत के संबंध में ढाल में स्रोत का आकार होता है:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
यहाँ फिर से ढाल गणना है, इस बार चरों का एक शब्दकोश पारित कर रहा है:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
एक मॉडल के संबंध में ग्रेडिएंट
चेकपॉइंटिंग और निर्यात के लिए tf.Variables को tf.Module या उसके उपवर्गों ( layers.Layer , keras.Model ) में एकत्रित करना आम बात है।
ज्यादातर मामलों में, आप एक मॉडल के प्रशिक्षण योग्य चर के संबंध में ग्रेडिएंट की गणना करना चाहेंगे। चूंकि tf.Module के सभी उपवर्ग अपने चर को मॉड्यूल. Module.trainable_variables गुण में एकत्रित करते हैं, आप कोड की कुछ पंक्तियों में इन ग्रेडिएंट्स की गणना कर सकते हैं:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
टेप जो देखता है उसे नियंत्रित करना
डिफ़ॉल्ट व्यवहार एक प्रशिक्षित tf.Variable तक पहुँचने के बाद सभी कार्यों को रिकॉर्ड करना है। इसके कारण हैं:
- टेप को यह जानने की जरूरत है कि पीछे के पास में ग्रेडियेंट की गणना करने के लिए आगे के पास में कौन से संचालन रिकॉर्ड करना है।
- टेप में मध्यवर्ती आउटपुट के संदर्भ हैं, इसलिए आप अनावश्यक संचालन रिकॉर्ड नहीं करना चाहते हैं।
- सबसे आम उपयोग के मामले में एक मॉडल के सभी प्रशिक्षित चर के संबंध में नुकसान की ढाल की गणना करना शामिल है।
उदाहरण के लिए, निम्न ग्रेडिएंट की गणना करने में विफल रहता है क्योंकि tf.Tensor डिफ़ॉल्ट रूप से "देखा" नहीं जाता है, और tf.Variable प्रशिक्षित नहीं होता है:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
आप GradientTape.watched_variables विधि का उपयोग करके टेप द्वारा देखे जा रहे चरों को सूचीबद्ध कर सकते हैं:
[var.name for var in tape.watched_variables()]
['x0:0']प्लेसहोल्डर17
tf.GradientTape हुक प्रदान करता है जो उपयोगकर्ता को यह नियंत्रित करता है कि क्या देखा जा रहा है या क्या नहीं देखा जा सकता है।
tf.Tensor के संबंध में ग्रेडिएंट रिकॉर्ड करने के लिए, आपको GradientTape.watch(x) पर कॉल करने की आवश्यकता है:
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
इसके विपरीत, सभी tf.Variables देखने के डिफ़ॉल्ट व्यवहार को अक्षम करने के लिए, ग्रेडिएंट टेप बनाते समय watch_accessed_variables=False सेट करें। यह गणना दो चर का उपयोग करती है, लेकिन केवल एक चर के लिए ढाल को जोड़ती है:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
चूंकि GradientTape.watch को x0 पर कॉल नहीं किया गया था, इसलिए इसके संबंध में किसी भी ग्रेडिएंट की गणना नहीं की जाती है:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546प्लेसहोल्डर22
इंटरमीडिएट परिणाम
आप tf.GradientTape संदर्भ में गणना किए गए मध्यवर्ती मानों के संबंध में आउटपुट के ग्रेडिएंट का भी अनुरोध कर सकते हैं।
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
डिफ़ॉल्ट रूप से, जैसे ही GradientTape.gradient पद्धति को कहा जाता है, GradientTape द्वारा रखे गए संसाधन जारी हो जाते हैं। एक ही गणना पर कई ग्रेडिएंट की गणना करने के लिए, एक ग्रेडिएंट टेप बनाएं जिसमें persistent=True हो। यह gradient विधि के लिए एकाधिक कॉल की अनुमति देता है क्योंकि टेप ऑब्जेक्ट कचरा एकत्र होने पर संसाधन जारी किए जाते हैं। उदाहरण के लिए:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]प्लेसहोल्डर26 l10n-प्लेसहोल्डर
del tape # Drop the reference to the tape
प्रदर्शन पर नोट्स
ग्रेडिएंट टेप के संदर्भ में संचालन करने से जुड़ा एक छोटा ओवरहेड है। सबसे उत्सुक निष्पादन के लिए यह ध्यान देने योग्य लागत नहीं होगी, लेकिन आपको अभी भी उन क्षेत्रों के आसपास टेप संदर्भ का उपयोग करना चाहिए जहां इसकी आवश्यकता है।
ग्रैडिएंट टेप, बैकवर्ड पास के दौरान उपयोग के लिए इनपुट और आउटपुट सहित मध्यवर्ती परिणामों को संग्रहीत करने के लिए मेमोरी का उपयोग करते हैं।
दक्षता के लिए, कुछ ऑप्स (जैसे
ReLU) को अपने मध्यवर्ती परिणाम रखने की आवश्यकता नहीं होती है और फॉरवर्ड पास के दौरान उन्हें काट दिया जाता है। हालाँकि, यदि आप अपने टेप परpersistent=Trueका उपयोग करते हैं, तो कुछ भी नहीं छोड़ा जाता है और आपकी अधिकतम मेमोरी का उपयोग अधिक होगा।
गैर-अदिश लक्ष्य के ग्रेडिएंट
एक ग्रेडिएंट मूल रूप से एक स्केलर पर एक ऑपरेशन है।
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
इस प्रकार, यदि आप कई लक्ष्यों के ग्रेडिएंट के लिए पूछते हैं, तो प्रत्येक स्रोत के लिए परिणाम है:
- लक्ष्यों के योग का ग्रेडिएंट, या समकक्ष
- प्रत्येक लक्ष्य के ग्रेडिएंट का योग।
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
इसी तरह, यदि लक्ष्य अदिश नहीं हैं तो योग के ढाल की गणना की जाती है:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0प्लेसहोल्डर33
इससे हानियों के संग्रह के योग का ग्रेडिएंट या तत्व-वार हानि गणना के योग का ग्रेडिएंट लेना आसान हो जाता है।
यदि आपको प्रत्येक आइटम के लिए एक अलग ग्रेडिएंट की आवश्यकता है, तो जैकोबियन देखें।
कुछ मामलों में आप जैकोबियन को छोड़ सकते हैं। तत्व-वार गणना के लिए, योग का ढाल प्रत्येक तत्व के व्युत्पन्न को उसके इनपुट-तत्व के संबंध में देता है, क्योंकि प्रत्येक तत्व स्वतंत्र है:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
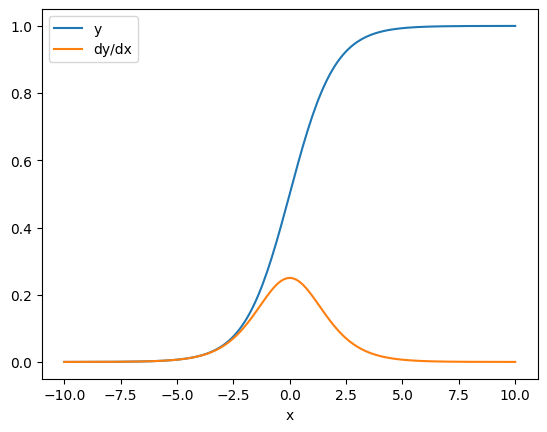
बहाव को काबू करें
चूंकि एक ग्रेडिएंट टेप संचालन को रिकॉर्ड करता है क्योंकि उन्हें निष्पादित किया जाता है, पायथन नियंत्रण प्रवाह स्वाभाविक रूप से नियंत्रित किया जाता है (उदाहरण के लिए, if और बयान के while )।
यहां if की प्रत्येक शाखा पर एक अलग चर का उपयोग किया जाता है। ग्रेडिएंट केवल उस वेरिएबल से जुड़ता है जिसका उपयोग किया गया था:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
बस याद रखें कि नियंत्रण कथन स्वयं भिन्न नहीं हैं, इसलिए वे ढाल-आधारित अनुकूलक के लिए अदृश्य हैं।
उपरोक्त उदाहरण में x के मान के आधार पर, टेप या तो result = v0 या result = v1**2 रिकॉर्ड करता है। x के संबंध में ग्रेडिएंट हमेशा None होता है।
dx = tape.gradient(result, x)
print(dx)
None
None का ग्रेडिएंट प्राप्त करना
जब कोई लक्ष्य किसी स्रोत से कनेक्ट नहीं होता है तो आपको None का ग्रेडिएंट मिलेगा।
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
यहाँ z स्पष्ट रूप से x से जुड़ा नहीं है, लेकिन कई कम-स्पष्ट तरीके हैं जिनसे एक ढाल को डिस्कनेक्ट किया जा सकता है।
1. एक चर को एक टेंसर से बदला गया
"टेप जो देखता है उसे नियंत्रित करना" अनुभाग में आपने देखा कि टेप स्वचालित रूप से एक tf.Variable लेकिन tf.Tensor नहीं tf.Tensor ।
tf.Tensor को अपडेट करने के लिए Variable.assign का उपयोग करने के बजाय अनजाने में एक tf.Variable को tf.Variable से बदल देना एक सामान्य त्रुटि है। यहाँ एक उदाहरण है:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. क्या TensorFlow के बाहर गणना की गई है
यदि गणना TensorFlow से बाहर निकलती है, तो टेप ग्रेडिएंट पथ को रिकॉर्ड नहीं कर सकता है। उदाहरण के लिए:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. एक पूर्णांक या स्ट्रिंग के माध्यम से ग्रेडिएंट लिया
पूर्णांक और तार भिन्न नहीं हैं। यदि कोई गणना पथ इन डेटा प्रकारों का उपयोग करता है तो कोई ग्रेडिएंट नहीं होगा।
कोई भी स्ट्रिंग्स को अलग-अलग होने की उम्मीद नहीं करता है, लेकिन अगर आप dtype निर्दिष्ट नहीं करते हैं तो गलती से एक int स्थिर या चर बनाना आसान है।
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow स्वचालित रूप से प्रकारों के बीच नहीं डाला जाता है, इसलिए, व्यवहार में, आपको अक्सर एक लापता ग्रेडिएंट के बजाय एक प्रकार की त्रुटि मिलेगी।
4. एक स्टेटफुल ऑब्जेक्ट के माध्यम से ग्रेडिएंट लिया
राज्य ग्रेडिएंट रोकता है। जब आप किसी स्टेटफुल ऑब्जेक्ट से पढ़ते हैं, तो टेप केवल वर्तमान स्थिति का अवलोकन कर सकता है, न कि उस इतिहास को जो इसे आगे ले जाता है।
एक tf.Tensor अपरिवर्तनीय है। एक बार टेंसर बनने के बाद आप उसे बदल नहीं सकते। इसका एक मूल्य है, लेकिन कोई राज्य नहीं है। अब तक चर्चा किए गए सभी ऑपरेशन भी स्टेटलेस हैं: tf.matmul का आउटपुट केवल इसके इनपुट पर निर्भर करता है।
एक tf.Variable की आंतरिक स्थिति होती है—इसका मान। जब आप चर का उपयोग करते हैं, तो राज्य पढ़ा जाता है। एक चर के संबंध में एक ढाल की गणना करना सामान्य है, लेकिन चर की स्थिति ढाल की गणना को आगे पीछे जाने से रोकती है। उदाहरण के लिए:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
इसी तरह, tf.data.Dataset iterators और tf.queue s स्टेटफुल हैं, और उन टेंसरों पर सभी ग्रेडिएंट्स को रोक देंगे जो उनके पास से गुजरते हैं।
कोई ग्रेडिएंट पंजीकृत नहीं
कुछ tf.Operation गैर-भिन्न होने के रूप में पंजीकृत हैं और None लौटाएगा। अन्य के पास कोई ग्रेडिएंट पंजीकृत नहीं है ।
tf.raw_ops पृष्ठ दिखाता है कि निम्न-स्तरीय ऑप्स में ग्रेडिएंट पंजीकृत हैं।
यदि आप एक फ्लोट ऑप के माध्यम से एक ग्रेडिएंट लेने का प्रयास करते हैं जिसमें कोई ग्रेडिएंट पंजीकृत नहीं है तो टेप चुपचाप None लौटने के बजाय एक त्रुटि फेंक देगा। इस तरह आप जानते हैं कि कुछ गलत हो गया है।
उदाहरण के लिए, tf.image.adjust_contrast फ़ंक्शन raw_ops.AdjustContrastv2 को लपेटता है, जिसमें एक ग्रेडिएंट हो सकता है लेकिन ग्रेडिएंट लागू नहीं होता है:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
यदि आपको इस ऑप के माध्यम से अंतर करने की आवश्यकता है, तो आपको या तो ग्रेडिएंट को लागू करना होगा और इसे पंजीकृत करना होगा ( tf.RegisterGradient का उपयोग करके) या अन्य ऑप्स का उपयोग करके फ़ंक्शन को फिर से लागू करना होगा।
शून्य के बजाय शून्य
कुछ मामलों में असंबद्ध ग्रेडिएंट के लिए None के बजाय 0 प्राप्त करना सुविधाजनक होगा। आप तय कर सकते हैं कि unconnected_gradients तर्क का उपयोग करके असंबद्ध ग्रेडिएंट होने पर क्या लौटाया जाए:
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)