
ここ数年ほど、ニューラルネットワークアーキテクチャに挿入できる新しい差別化可能なグラフィックスレイヤーが増加しています。空間トランスフォーマーから差別化可能なグラフィックスレンダラーまで、新しいレイヤーはコンピュータビジョンとグラフィックスの研究で長年培われてきた知識を活用し、新しく、より効率的なネットワークアーキテクチャを構築しています。幾何学的な事前条件と制限をニューラルネットワークに明示的にモデル化することで、自己監視方式で堅牢で効率的かつより重要な方法でトレーニングできるアーキテクチャへの扉が開かれています。
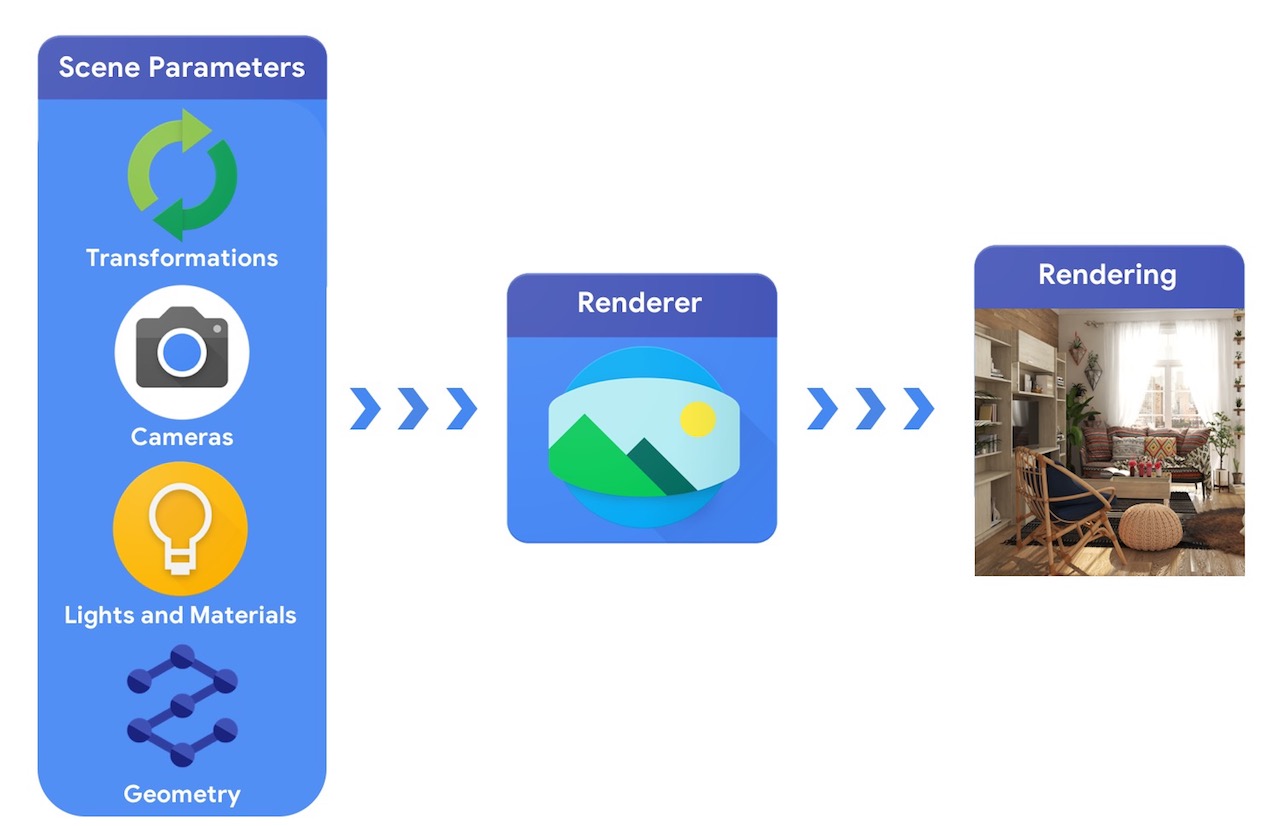
大まかに言えば、コンピュータグラフィックスのパイプラインには、3D オブジェクトの表現、シーン内の絶対的位置、作成に使用される材料の説明、照明、およびカメラが必要です。このようなシーンの説明はレンダラーに解釈された上で、合成レンダリングが生成されます。
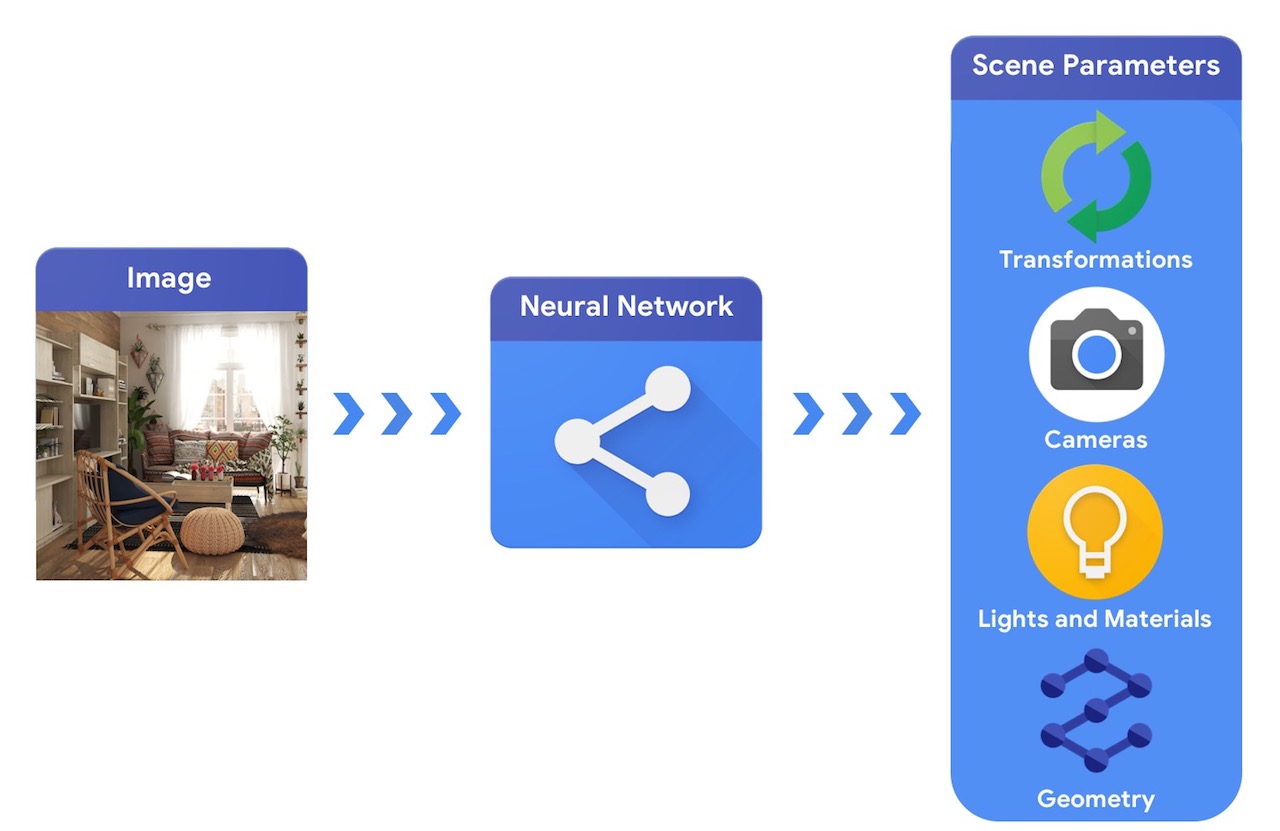
それと比べ、コンピュータビジョンシステムは画像をもとに
、シーンのパラメータを推論します。このため、シーンにどのようなオブジェクトがあるのか、どのような材料で作られているのか、および 3 次元の位置と向きの予測を行うことができます。
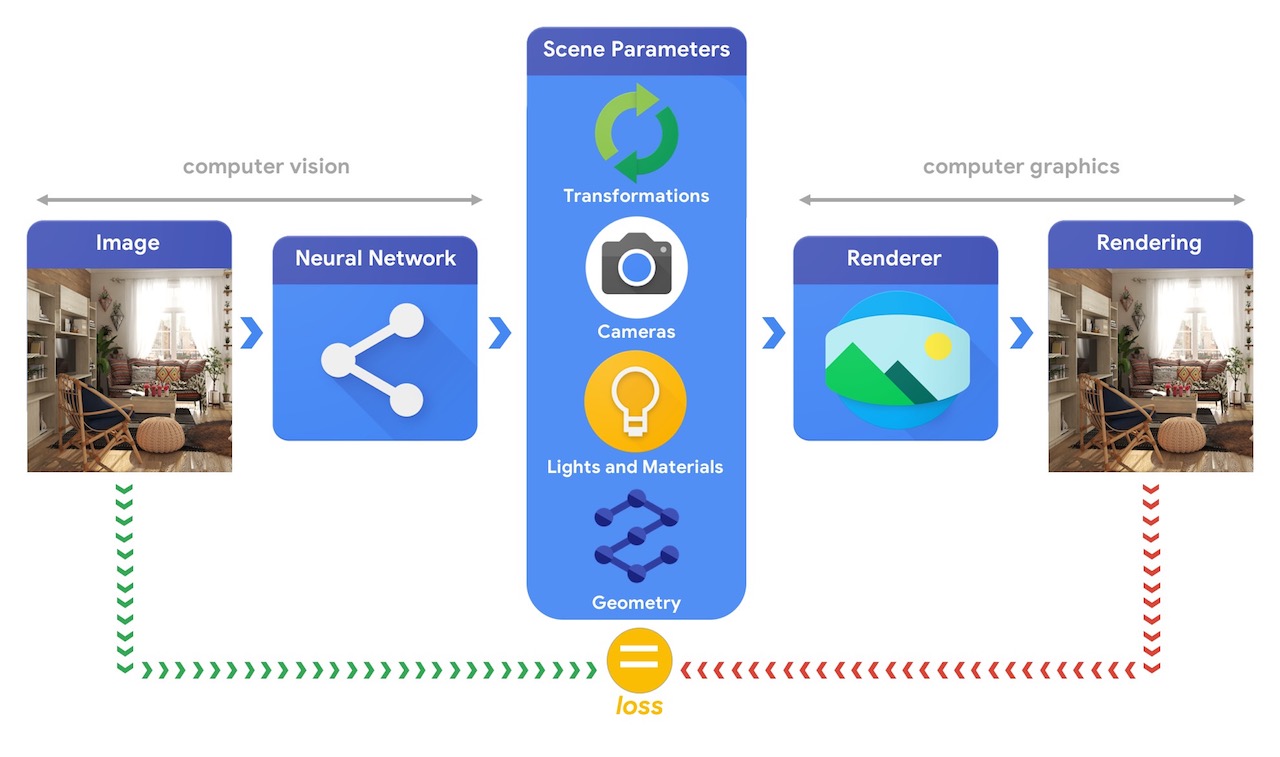
このような複雑な 3D ビジョンタスクを解決できる機械学習システムのトレーニングには、ほとんどの場合、大量のデータが必要となります。データのラベル付けはコストが高く、複雑なプロセスであるため、3 次元の世界を理解する一方で、あまり監督を必要とせずにトレーニングできる機械学習モデルの設計メカニズムが用意されていることが重要となります。コンピュータビジョンとコンピュータグラフィックスのテクニックを組み合わせれば、膨大な量の、ラベル付けされていない、すぐに利用できるデータを活用できるユニークな機会が得られます。下の画像に示されるとおり、たとえばビジョンシステムがシーンパラメータを抽出して、そのパラメータに基づいて、グラフィックスシステムが画像をレンダリングし直すという合成による分析を使用すれば、実現が可能と言えます。レンダリングが元の画像に一致すれば、ビジョンシステムはシーンのパラメータを正確に抽出したことになります。このセットアップでは、コンピュータビジョンとコンピュータグラフィックスはセットとして連携し、自己エンコーダに似た、自己監視式でトレーニングできる単一の機械学習システムを形成しています。
Tensorflow Graphics は、この種のチャレンジの一助となるように開発中であり、任意の機械学習モデルのトレーニングとデバッグに使用できる、差別化可能なグラフィックスと幾何学レイヤー(カメラ、反射モデル、空間トランスフォーマー、メッシュ畳み込みなど)と 3D ビューア機能(3D TensorBoard など)を提供しています。