
पिछले कुछ वर्षों में उपन्यास विभेदक ग्राफिक्स परतों में वृद्धि देखी गई है जिन्हें तंत्रिका नेटवर्क आर्किटेक्चर में डाला जा सकता है। स्थानिक ट्रांसफॉर्मर से लेकर अलग-अलग ग्राफिक्स रेंडरर्स तक, ये नई परतें नए और अधिक कुशल नेटवर्क आर्किटेक्चर के निर्माण के लिए कंप्यूटर विज़न और ग्राफिक्स रिसर्च के वर्षों में प्राप्त ज्ञान का लाभ उठाती हैं। स्पष्ट रूप से ज्यामितीय पुजारियों और तंत्रिका नेटवर्क में बाधाओं को मॉडलिंग करने से आर्किटेक्चर के द्वार खुलते हैं जिन्हें आत्म-पर्यवेक्षित फैशन में मजबूती से, कुशलता से और अधिक महत्वपूर्ण रूप से प्रशिक्षित किया जा सकता है।
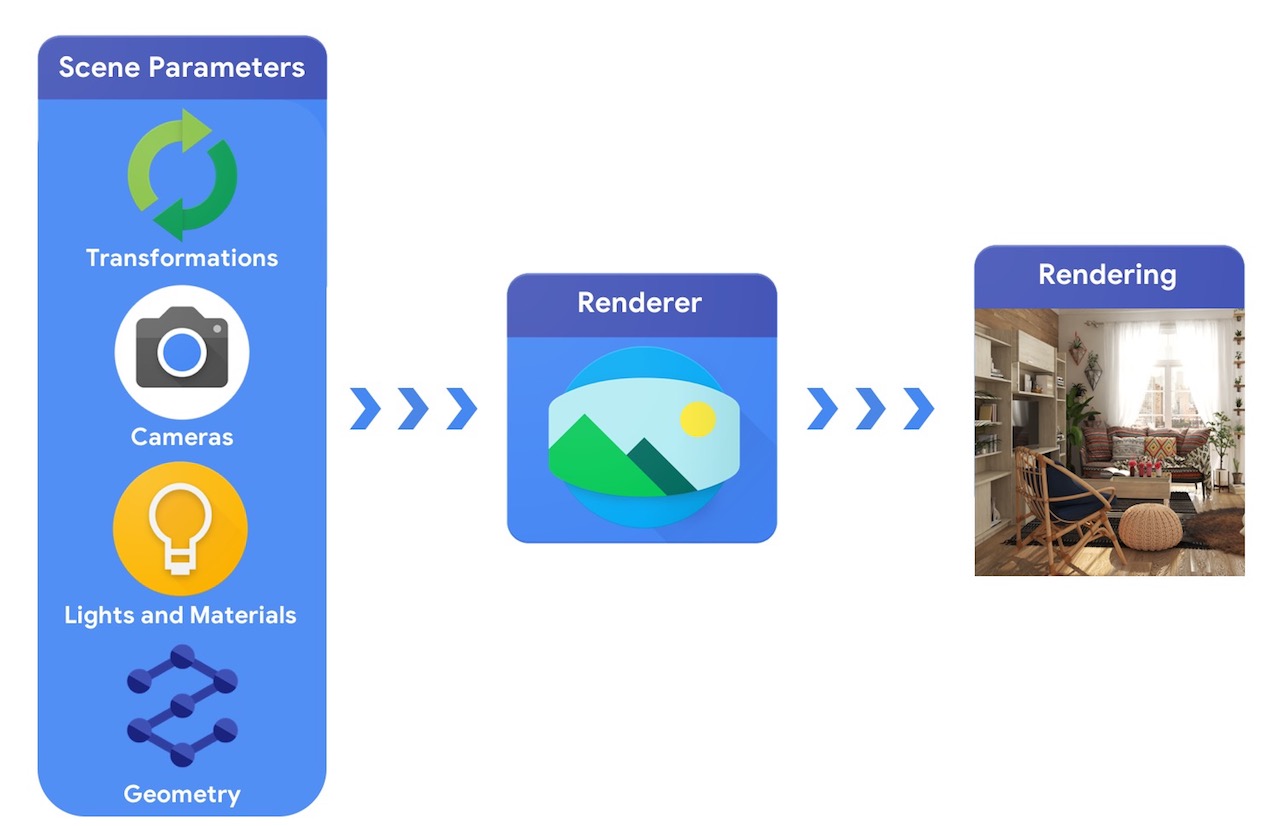
उच्च स्तर पर, एक कंप्यूटर ग्राफिक्स पाइपलाइन के लिए 3D वस्तुओं के प्रतिनिधित्व और दृश्य में उनकी पूर्ण स्थिति की आवश्यकता होती है, उस सामग्री का विवरण जिससे वे बने होते हैं, रोशनी और एक कैमरा। इस दृश्य विवरण की व्याख्या एक रेंडरर द्वारा सिंथेटिक रेंडरिंग उत्पन्न करने के लिए की जाती है।
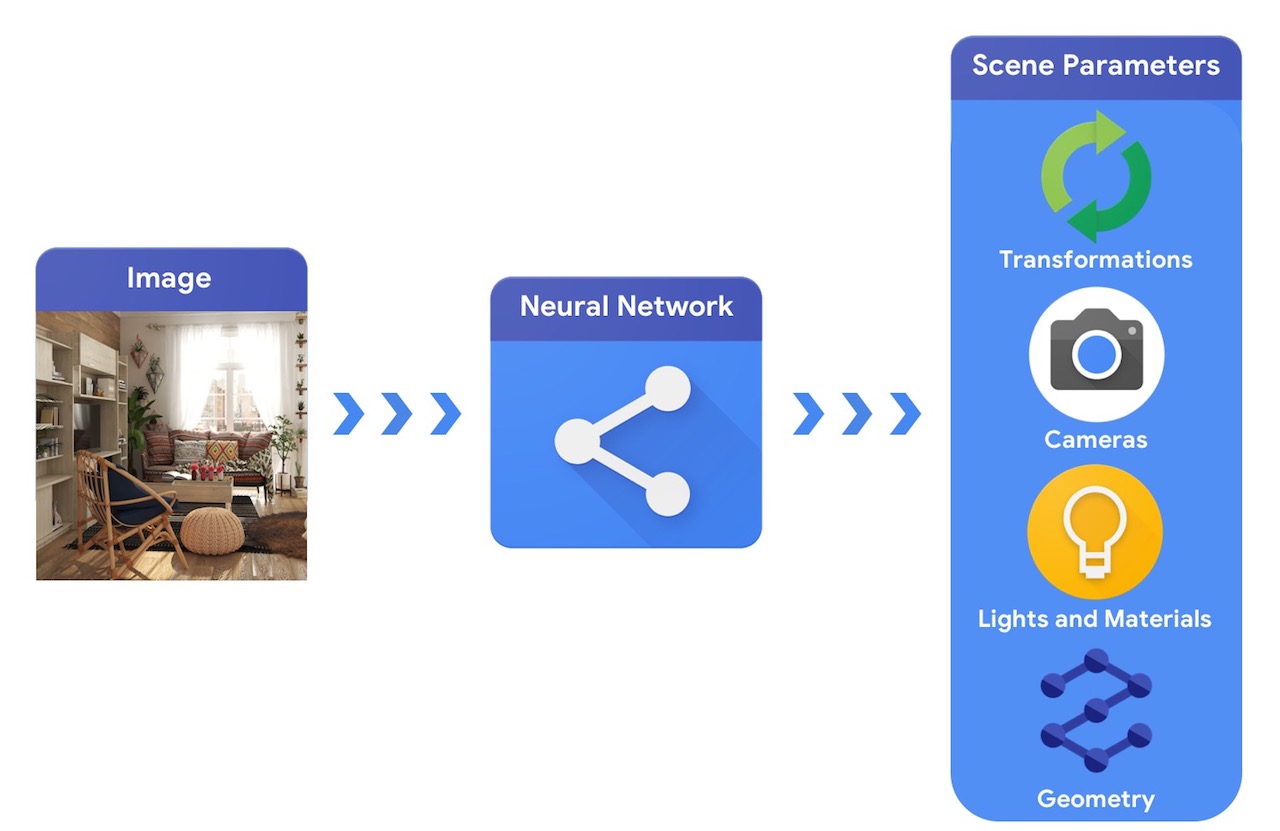
इसकी तुलना में, एक कंप्यूटर विज़न सिस्टम एक छवि से शुरू होगा और दृश्य के मापदंडों का अनुमान लगाने की कोशिश करेगा। यह भविष्यवाणी की अनुमति देता है कि कौन सी वस्तुएं दृश्य में हैं, वे किस सामग्री से बनी हैं, और त्रि-आयामी स्थिति और अभिविन्यास।
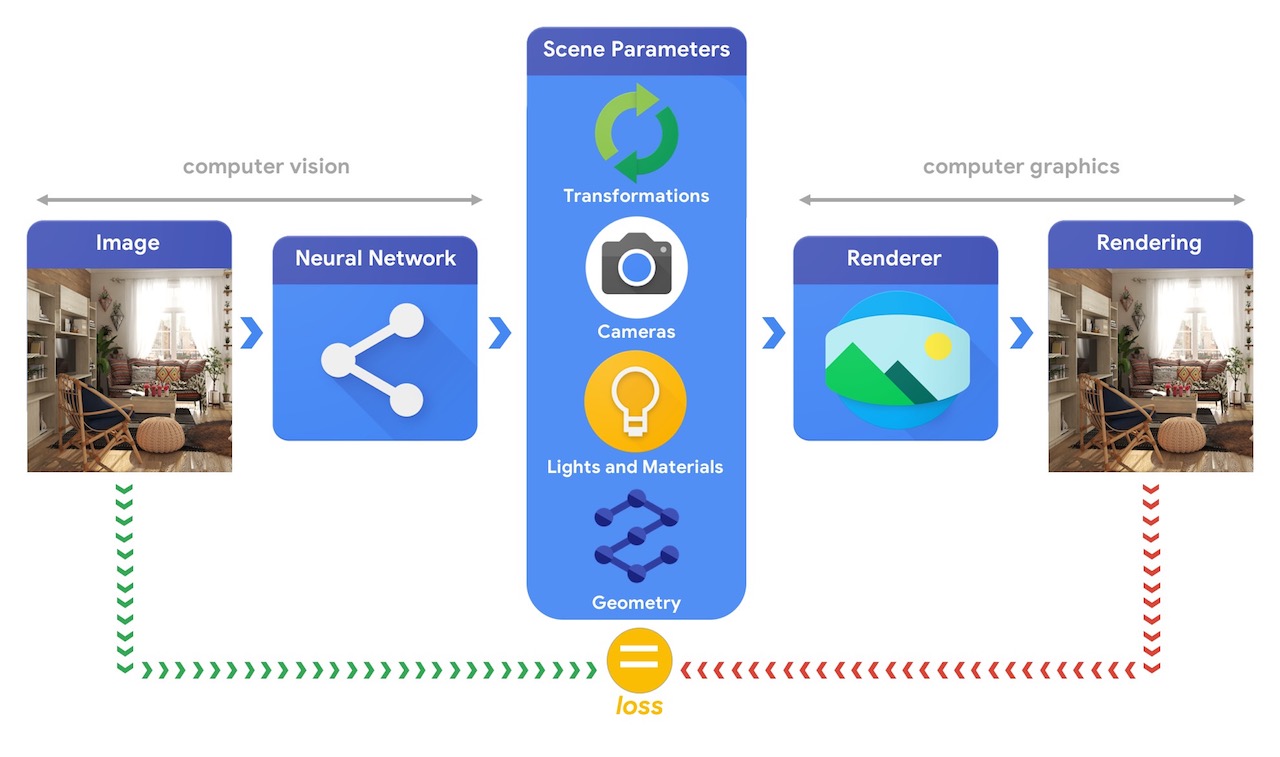
इन जटिल 3D विज़न कार्यों को हल करने में सक्षम प्रशिक्षण मशीन लर्निंग सिस्टम को अक्सर बड़ी मात्रा में डेटा की आवश्यकता होती है। चूंकि डेटा लेबल करना एक महंगी और जटिल प्रक्रिया है, इसलिए मशीन लर्निंग मॉडल को डिजाइन करने के लिए तंत्र का होना जरूरी है जो बिना किसी पर्यवेक्षण के प्रशिक्षित होने के दौरान त्रि-आयामी दुनिया को समझ सके। कंप्यूटर विज़न और कंप्यूटर ग्राफिक्स तकनीकों का संयोजन आसानी से उपलब्ध बिना लेबल वाले डेटा की विशाल मात्रा का लाभ उठाने का एक अनूठा अवसर प्रदान करता है। जैसा कि नीचे दी गई छवि में दिखाया गया है, उदाहरण के लिए, यह संश्लेषण द्वारा विश्लेषण का उपयोग करके प्राप्त किया जा सकता है जहां दृष्टि प्रणाली दृश्य मापदंडों को निकालती है और ग्राफिक्स सिस्टम उनके आधार पर एक छवि को वापस प्रस्तुत करता है। यदि प्रतिपादन मूल छवि से मेल खाता है, तो विज़न सिस्टम ने दृश्य मापदंडों को सटीक रूप से निकाला है। इस सेटअप में, कंप्यूटर विज़न और कंप्यूटर ग्राफिक्स एक साथ चलते हैं, एक ऑटोएन्कोडर के समान एकल मशीन लर्निंग सिस्टम बनाते हैं, जिसे स्व-पर्यवेक्षित तरीके से प्रशिक्षित किया जा सकता है।
Tensorflow ग्राफ़िक्स को इस प्रकार की चुनौतियों से निपटने में मदद करने के लिए विकसित किया जा रहा है और ऐसा करने के लिए, यह अलग-अलग ग्राफिक्स और ज्यामिति परतों (जैसे कैमरा, परावर्तन मॉडल, स्थानिक परिवर्तन, जाल कनवल्शन) और 3D व्यूअर फ़ंक्शंस (जैसे 3D TensorBoard) का एक सेट प्रदान करता है। अपनी पसंद के मशीन लर्निंग मॉडल को प्रशिक्षित और डिबग करने के लिए इस्तेमाल किया जा सकता है।