
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
הדרכה זו בוחנת למידה Federated מקומית חלקית, שבו כמה פרמטרים הלקוח לעולם אינם מצטברים בשרת. זה שימושי עבור מודלים עם פרמטרים ספציפיים למשתמש (למשל מודלים של מטריצות לגורמים לגורמים) ולהדרכה בהגדרות מוגבלות לתקשורת. אנו בונים על מושגים הציג למידה Federated עבור תמונה סיווג הדרכה; כמו הדרכה כי, אנו מציגים APIs ברמה גבוהה ב- tff.learning להכשרה והערכה Federated.
נתחיל להניע למידה Federated מקומית חלקית עבור פרוק מטריקס . אנו מתארים Federated שחזור ( נייר , פוסט בבלוג ), אלגוריתם מעשי ללמידה Federated מקומית חלקית בהיקף נרחב. אנחנו מכינים את מערך הנתונים של MovieLens 1M, בונים מודל מקומי בחלקו, ומאמנים ומעריכים אותו.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
רקע: פקטוריזציה של מטריקס
פרוק מטריקס כבר טכניקה פופולרית היסטורית ללימוד המלצות והטבעה ייצוגים עבור פריטים סמך פעולות המשתמש. הדוגמה הקנונית היא המלצה לסרט, שבו יש \(n\) משתמשים \(m\) סרטים, ומשתמשים דירגו סרטים מסוימים. בהינתן משתמש, אנו משתמשים בהיסטוריית הדירוגים שלו ובדירוגים של משתמשים דומים כדי לחזות את הדירוגים של המשתמש עבור סרטים שהם לא ראו. אם יש לנו מודל שיכול לחזות דירוגים, קל להמליץ למשתמשים על סרטים חדשים שהם ייהנו.
עבור משימה זו, כדאי לייצג דירוגי משתמשים כקובץ \(n \times m\) מטריקס \(R\):

המטריצה הזו דלילה בדרך כלל, מכיוון שמשתמשים רואים בדרך כלל רק חלק קטן מהסרטים במערך הנתונים. הפלט של פרוק מטריקס היא שתי מטריצות: An \(n \times k\) מטריקס \(U\) המייצג \(k\)שיבוצים המשתמשים מימדי עבור כל משתמש, וכן \(m \times k\) מטריקס \(I\) המייצג \(k\)שיבוצים פריט מימדי עבור כל פריט. מטרת האימון פשוט היא להבטיח כי המוצר הנקוד של שיבוצים המשתמשים פריט הם חזוי של דירוגים הנצפה \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
זה שווה ערך למזעור השגיאה הממוצעת בריבוע בין דירוגים שנצפו ודירוגים החזויים על ידי נטילת תוצר הנקודות של ההטמעות של המשתמש והפריט המתאימים. דרך נוספת לפרש זה המבטיח הזה \(R \approx UI^T\) לרייטינג ידוע, ומכאן "פרוק מטריקס". אם זה מבלבל, אל תדאג - לא נצטרך לדעת את הפרטים של פירוק מטריצה לשאר המדריך.
חקר נתוני MovieLens
בואו נתחיל ידי טעינת 1M MovieLens הנתונים, אשר מורכב של 1,000,209 דירוגי סרט מ 6040 משתמש על 3706 סרטים.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
בואו נטען ונחקור כמה מסגרות נתונים של Pandas המכילות את נתוני הדירוג והסרטים.
ratings_df, movies_df = load_movielens_data()
אנו יכולים לראות שלכל דוגמה לדירוג יש דירוג מ-1-5, UserID תואם, MovieID תואם וחותמת זמן.
ratings_df.head()
לכל סרט יש שם ויכול להיות מספר ז'אנרים.
movies_df.head()
זה תמיד רעיון טוב להבין נתונים סטטיסטיים בסיסיים של מערך הנתונים:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))

Average rating: 3.581564453029317 Median rating: 4.0
אנחנו יכולים גם לתכנן את ז'אנרי הסרטים הפופולריים ביותר.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
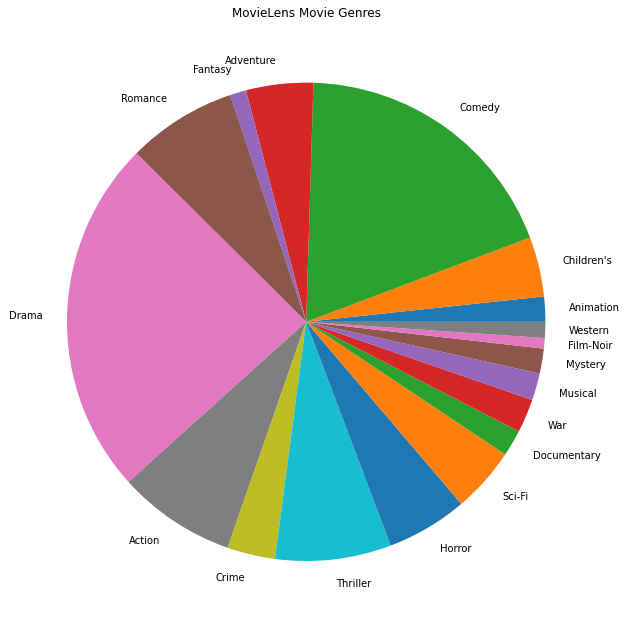
נתונים אלה מחולקים באופן טבעי לדירוגים של משתמשים שונים, כך שהיינו מצפים להטרוגניות מסוימת בנתונים בין לקוחות. להלן אנו מציגים את ז'אנר הסרטים הנפוץ ביותר עבור משתמשים שונים. אנו יכולים לראות הבדלים משמעותיים בין משתמשים.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
עיבוד מוקדם של נתוני MovieLens
נצטרך עכשיו להכין את הנתונים MovieLens כרשימת tf.data.Dataset ים המייצגים כל הנתונים של המשתמש לשימוש עם TFF.
אנו מיישמים שתי פונקציות:
-
create_tf_datasets: לוקח הרייטינג שלנו DataFrame ומייצרת רשימה של ידידותיות פיצולtf.data.Datasetים. -
split_tf_datasets: לוקח רשימה של מערכי נתונים ומח' אותם לתוך רכבת / Val / מבחן על ידי משתמשים, כך קובע Val / המבחן מכיל אך ורק בדירוג ממשתמשים סמויים במהלך אימונים. בדרך כלל ב פרוק מטריקס מרכזי תקן שאנחנו בעצם לפצל כך Val / מבחן הסטים שמכילים דירוגים מושטים ממשתמשים לראות, מאז משתמשים סמויים אין שיבוצי משתמשים. במקרה שלנו, נראה מאוחר יותר שהגישה בה אנו משתמשים כדי לאפשר פירוק מטריצה ב-FL גם מאפשרת שחזור מהיר של הטמעות משתמשים עבור משתמשים בלתי נראים.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
כבדיקה מהירה, אנו יכולים להדפיס אצווה של נתוני אימון. אנו יכולים לראות שכל דוגמה בודדת מכילה MovieID מתחת למקש "x" ודירוג מתחת למקש "y". שימו לב שלא נזדקק ל-UserID מכיוון שכל משתמש רואה רק את הנתונים שלו.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
אנו יכולים לשרטט היסטוגרמה המראה את מספר הדירוגים למשתמש.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()

כעת, לאחר שטענו וחקרנו את הנתונים, נדון כיצד להביא פירוק מטריצה ללמידה מאוחדת. לאורך הדרך, נניע למידה פדרציה מקומית חלקית.
הבאת מטריצת פקטוריזציה ל-FL
בעוד שפירוק מטריצה שימש באופן מסורתי בהגדרות מרכזיות, הוא רלוונטי במיוחד בלמידה מאוחדת: דירוגי משתמשים עשויים להתקיים במכשירי לקוח נפרדים, ואולי נרצה ללמוד הטמעות והמלצות עבור משתמשים ופריטים מבלי לרכז את הנתונים. מכיוון שלכל משתמש יש הטמעת משתמש תואמת, זה טבעי שכל לקוח יאחסן את הטמעת המשתמש שלו - זה קנה מידה הרבה יותר טוב מאשר שרת מרכזי המאחסן את כל ההטמעות של המשתמש.
הצעה אחת להבאת פירוק מטריצה ל-FL היא כדלקמן:
- חנויות השרת שולח את מטריצת פריט \(I\) ללקוחות שנדגמו כל סיבוב
- לקוחות לעדכן את מטריצת הפריט והמשתמש האישי שלהם הטבעת \(U_u\) באמצעות SGD על המטרה הנ"ל
- עדכונים \(I\) נצברים בשרת, מעדכנים את העותק בשרת של \(I\) לסיבוב הבא
גישה זו היא מקומית חלקית -כלומר, כמה פרמטרים הלקוח לעולם אינם מצטברים ידי השרת. למרות שגישה זו מושכת, היא דורשת מהלקוחות לשמור על מצב לאורך סבבים, כלומר הטמעות המשתמש שלהם. אלגוריתמים מאוחדים ממלכתיים פחות מתאימים להגדרות FL חוצות-מכשירים: בהגדרות אלו גודל האוכלוסייה לרוב גדול בהרבה ממספר הלקוחות המשתתפים בכל סבב, ולקוח בדרך כלל משתתף לכל היותר פעם אחת במהלך תהליך האימון. מלבד הסתמכות על המדינה כי לא ניתן אותחל, אלגוריתמי מצבים יכולים לגרום בביצועים במסגרות במכשירים אחרים בשל מעופש המדינה מקבל כשהלקוחות נדגמים רחוקה. חשוב לציין, בהגדרת חלוקת המטריצה לגורמים, אלגוריתם מצב מוביל לכך שכל הלקוחות הבלתי נראים מחמיצים הטמעות משתמש מאומן, ובהדרכה בקנה מידה גדול רוב המשתמשים עשויים להיות בלתי נראים. למידע נוסף על מוטיבציה אלגוריתמי נתינות ב FL במכשירים אחרים, לראות וואנג ואח '. 2021 שני 3.1.1 ו Reddi ואח. 2020 שניות 5.1 .
Federated שחזור ( סינגהאל et al. 2021 ) הוא אלטרנטיבה חסרת הגישה הנ"ל. הרעיון המרכזי הוא שבמקום לאחסן הטמעות משתמשים על פני סבבים, לקוחות משחזרים הטמעות משתמשים בעת הצורך. כאשר FedRecon מיושם על פירוק מטריצה, האימון מתקדם באופן הבא:
- חנויות השרת שולח את מטריצת פריט \(I\) ללקוחות שנדגמו כל סיבוב
- כל לקוח קופא \(I\) ומכשירה הטבעה המשתמש שלהם \(U_u\) באמצעות אחד או יותר צעדים של SGD (שחזור)
- כל לקוח קופא \(U_u\) ורכבות \(I\) באמצעות אחד או יותר צעדים של SGD
- עדכונים \(I\) נצברים בין משתמשים, עדכון העותק בשרת של \(I\) לסיבוב הבא
גישה זו אינה מחייבת את הלקוחות לשמור על מצב על פני סבבים. המחברים גם מראים במאמר ששיטה זו מובילה לשחזור מהיר של הטמעות משתמשים עבור לקוחות בלתי נראים (סעיף 4.2, איור 3 וטבלה 1), מה שמאפשר לרוב הלקוחות שאינם משתתפים בהדרכה לקבל מודל מאומן , המאפשר המלצות עבור לקוחות אלה. ראה שחזור Federated ובפוסט בבלוג AI גוגל עבור תוצאות מפתח יותר.
הגדרת הדגם
בשלב הבא נגדיר את מודל הפקטוריזציה של המטריצה המקומית שיאומן במכשירי לקוח. דגם זה יכלול את מטריצת פריט המלא \(I\) וכן הטבעת משתמש יחיד \(U_u\) עבור הלקוח \(u\). הערה שלקוחות לא יצטרכו לאחסן מטריצת משתמשים המלאה \(U\).
נגדיר את הדברים הבאים:
-
UserEmbedding: שכבת Keras פשוט מייצג יחידnum_latent_factorsהטבעה המשתמש ממדים. -
get_matrix_factorization_model: פונקציה שמחזירהtff.learning.reconstruction.Modelהמכיל את היגיון המודל, כוללים אילו שכבות נצברות באופן גלובלי בשרת ואשר שכבות להישאר מקומי. אנו זקוקים למידע נוסף זה כדי לאתחל את תהליך ההכשרה הפדרציה לשחזור. כאן אנו מייצרים אתtff.learning.reconstruction.Modelממודל Keras באמצעותtff.learning.reconstruction.from_keras_model. בדומהtff.learning.Model, נוכל גם ליישם מנהגtff.learning.reconstruction.Modelידי יישום ממשק בכיתה.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
אנלוגי הממשק עבור ממוצעי Federated, הממשק עבור Federated לשיקום צופה model_fn ללא ויכוחים שמחזיר tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
נצטרך הבא להגדיר loss_fn ו metrics_fn , שבו loss_fn הוא פונקציה לא-טיעון החוזר פסד Keras להשתמש כדי לאמן את המודל, ואת metrics_fn הוא פונקציה לא-טיעון חוזרת באמצעות רשימת ערכי Keras להערכה. אלה נחוצים כדי לבנות את חישובי ההדרכה וההערכה.
אנו נשתמש בשגיאת Mean Squared Error כהפסד, כפי שהוזכר לעיל. לצורך הערכה נשתמש בדיוק הדירוג (כאשר תוצר הנקודות החזוי של הדגם מעוגל למספר השלם הקרוב ביותר, באיזו תדירות הוא תואם לדירוג התווית?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
הדרכה והערכה
עכשיו יש לנו את כל מה שצריך כדי להגדיר את תהליך האימון. הבדל חשוב אחד מן הממשק ממוצע Federated הוא שאנחנו עכשיו לעבור בתוך reconstruction_optimizer_fn , אשר ישמש כאשר שחזור פרמטרים מקומיים (במקרה שלנו, שיבוצי משתמש). זה בדרך כלל סביר להשתמש SGD כאן, עם דומה או מעט נמוכה למידת שיעור מאשר לקוח האופטימיזציה למידת שיעור. אנו מספקים תצורת עבודה למטה. זה לא כוונן בקפידה, אז אל תהסס לשחק עם ערכים שונים.
בדקו את התיעוד לפרטים נוספים ואפשרויות.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
אנו יכולים גם להגדיר חישוב להערכת המודל הגלובלי המאומן שלנו.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
נוכל לאתחל את מצב תהליך האימון ולבחון אותו. והכי חשוב, אנו יכולים לראות שמצב שרת זה מאחסן רק משתני פריט (כרגע אתחול אקראי) ולא כל הטמעות משתמש.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
אנחנו יכולים גם לנסות להעריך את המודל האתחלי באקראי שלנו על לקוחות אימות. הערכת שחזור מאוחדת כאן כוללת את הדברים הבאים:
- השרת שולח את מטריצת פריט \(I\) ללקוחות הערכה שנדגמו
- כל לקוח קופא \(I\) ומכשירה הטבעה המשתמש שלהם \(U_u\) באמצעות אחד או יותר צעדים של SGD (שחזור)
- כול והפסד מחשב לקוח ומדדה באמצעות השרת \(I\) המשוחזר \(U_u\) על חלק סמוי של הנתונים המקומיים שלהם
- הפסדים ומדדים מוערכים בממוצע בין משתמשים כדי לחשב את ההפסד והמדדים הכוללים
שימו לב ששלבים 1 ו-2 זהים לאימון. חיבור זה חשוב, שכן אימון באותו אופן אנו מעריכים מובילים לצורה של מטא-למידה, או ללמוד איך ללמוד. במקרה זה, המודל לומד כיצד ללמוד משתנים גלובליים (מטריצת פריט) המובילים לשחזור ביצועי של משתנים מקומיים (הטמעות משתמש). למידע נוסף בנושא זה, ראה סעיף. 4.2 הנייר.
חשוב גם ששלבים 2 ו-3 יתבצעו תוך שימוש בחלקים לא משותפים של הנתונים המקומיים של הלקוחות, כדי להבטיח הערכה הוגנת. כברירת מחדל, גם תהליך האימון וגם חישוב ההערכה משתמשים בכל דוגמה אחרת לשחזור ומשתמשים בחצי השני שלאחר השחזור. התנהגות זו יכולה להיות מותאמת אישית באמצעות dataset_split_fn הטיעון (נחקור על כך בהמשך).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
בשלב הבא נוכל לנסות לרוץ סבב אימונים. כדי להפוך את הדברים למציאותיים יותר, נדגום 50 לקוחות בכל סבב באופן אקראי ללא החלפה. אנחנו עדיין צריכים לצפות שמדדי הרכבות יהיו גרועים, מכיוון שאנו עושים רק סבב אימון אחד.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
עכשיו בואו נגדיר לולאת אימון להתאמן על פני מספר סבבים.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
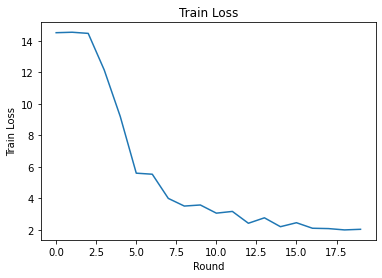
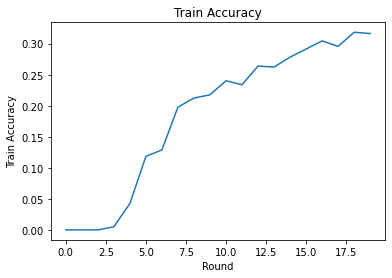
אנחנו יכולים לשרטט אובדן אימון ודיוק על פני סיבובים. הפרמטרים ההיפר במחברת זו לא כוונו בקפידה, אז אל תהסס לנסות לקוחות שונים לכל סבב, שיעורי למידה, מספר סבבים ומספר כולל של לקוחות כדי לשפר תוצאות אלו.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
לבסוף, נוכל לחשב מדדים על ערכת מבחן בלתי נראית כשנסיים לכוונן.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
מחקרים נוספים
עבודה יפה על השלמת המחברת הזו. אנו מציעים את התרגילים הבאים כדי לחקור את הלמידה הפדרציה המקומית באופן חלקי, לפי סדר גס לפי קושי הולך וגובר:
יישומים אופייניים של ממוצע פדרלי לוקחים מספר מעברים מקומיים (תקופות) על הנתונים (בנוסף למעבר אחד על הנתונים על פני מספר אצוות). עבור שחזור מאוחד, ייתכן שנרצה לשלוט על מספר השלבים בנפרד עבור אימון שחזור ופוסט-שחזור. העברת
dataset_split_fnטיעון בוני חישוב הכשרה והערכה מאפשר שליטה על מספר צעדים והתקופות מעל שני מערכי נתונים שיקום שלאחר השחזור. כתרגיל, נסה לבצע 3 תקופות מקומיות של אימון שחזור, מוגבל ל-50 צעדים ועידן מקומי אחד של אימון לאחר שחזור, מוגבל ל-50 צעדים. רמז: אתה תמצאtff.learning.reconstruction.build_dataset_split_fnמועיל. לאחר שעשית זאת, נסה לכוון את ההיפרפרמטרים הללו ופרמטרים קשורים אחרים כמו קצבי למידה וגודל אצווה כדי לקבל תוצאות טובות יותר.התנהגות ברירת המחדל של אימון והערכה של Federated Reconstruction היא לפצל את הנתונים המקומיים של הלקוחות לשניים עבור כל אחד של שחזור ואחרי שחזור. במקרים שבהם ללקוחות יש מעט מאוד נתונים מקומיים, זה יכול להיות סביר לעשות שימוש חוזר בנתונים לשחזור ולאחר שחזור עבור תהליך ההדרכה בלבד (לא להערכה, זה יוביל להערכה לא הוגנת). נסה לבצע את השינוי הזה לתהליך ההכשרה, הבטחת
dataset_split_fnלהערכה עדיין שומר פרוק נתונים שיקום שלאחר השחזור. רמז:tff.learning.reconstruction.simple_dataset_split_fnעשוי להיות שימושי.מעל, הפקנו
tff.learning.Modelממודל Keras באמצעותtff.learning.reconstruction.from_keras_model. אנחנו יכולים גם ליישם מודל מותאם אישית באמצעות TensorFlow הטהור 2.0 ידי יישום ממשק המודל . נסה לשנותget_matrix_factorization_modelלבנות ולחזור לכיתה המשתרעתtff.learning.reconstruction.Model, ויישום השיטות שלה. רמז: את קוד המקור שלtff.learning.reconstruction.from_keras_modelמספק דוגמה הארכתtff.learning.reconstruction.Modelבכיתה. עיין גם יישום המודל המותאם אישית הדרכת סיווג תמונת EMNIST עבור תרגיל דומה הושטתtff.learning.Model.במדריך זה, הנענו למידה מאוחדת מקומית חלקית בהקשר של פירוק מטריצה, כאשר שליחת הטמעות משתמש לשרת תדלוף באופן טריוויאלי העדפות משתמש. אנחנו יכולים גם ליישם Federated Reconstruction בהגדרות אחרות כדרך להכשיר מודלים אישיים יותר (מאחר שחלק מהמודל הוא מקומי לחלוטין לכל משתמש) תוך צמצום התקשורת (מאחר שפרמטרים מקומיים אינם נשלחים לשרת). באופן כללי, באמצעות הממשק המוצג כאן אנו יכולים לקחת כל מודל מאוחד שבדרך כלל יקבל הכשרה מלאה באופן גלובלי ובמקום זאת לחלק את המשתנים שלו למשתנים גלובליים ולמשתנים מקומיים. הדוגמה בחנו את נייר לשיקום Federated הוא חיזוי המילה הבאה אישי: כאן, לכל משתמש יש להגדיר מקומית משלהם של המילה שיבוצים עבור out-of-אוצר מילים, מה שמאפשר את המודל סלנג של המשתמשים ללכוד ולהשיג אישית בלי תקשורת נוספים. כתרגיל, נסה ליישם (כדגם Keras או כדגם TensorFlow 2.0 מותאם אישית) מודל אחר לשימוש עם Federated Reconstruction. הצעה: יישם מודל סיווג EMNIST עם הטבעת משתמש אישית, כאשר הטבעת המשתמש האישית משורשרת לתכונות התמונה של CNN לפני השכבה הצפופה האחרונה של המודל. ניתן לעשות שימוש חוזר הרבה של קוד הדרכה זו (למשל
UserEmbeddingבכיתה) ואת תמונת סיווג הדרכה .
אם אתה עדיין מחפש יותר על למידת Federated מקומית חלקית, לבדוק את נייר לשיקום Federated ואת קוד ניסוי קוד פתוח .