
tfds.features.FeatureConnector API:
- अंतिम
tf.data.Datasetकी संरचना, आकार, dtype को परिभाषित करता है - डिस्क से/से क्रमांकन को दूर करें।
- अतिरिक्त मेटाडेटा प्रदर्शित करें (जैसे लेबल नाम, ऑडियो नमूना दर,...)
सिंहावलोकन
tfds.features.FeatureConnector डेटासेट सुविधाओं की संरचना को परिभाषित करता है ( tfds.core.DatasetInfo में):
tfds.core.DatasetInfo(
features=tfds.features.FeaturesDict({
'image': tfds.features.Image(shape=(28, 28, 1), doc='Grayscale image'),
'label': tfds.features.ClassLabel(
names=['no', 'yes'],
doc=tfds.features.Documentation(
desc='Whether this is a picture of a cat',
value_range='yes or no'
),
),
'metadata': {
'id': tf.int64,
'timestamp': tfds.features.Scalar(
tf.int64,
doc='Timestamp when this picture was taken as seconds since epoch'),
'language': tf.string,
},
}),
)
सुविधाओं को या तो केवल एक पाठ्य विवरण ( doc='description' ) का उपयोग करके या अधिक विस्तृत सुविधा विवरण प्रदान करने के लिए सीधे tfds.features.Documentation का उपयोग करके प्रलेखित किया जा सकता है।
विशेषताएं हो सकती हैं:
- स्केलर मान:
tf.bool,tf.string,tf.float32,... जब आप सुविधा का दस्तावेजीकरण करना चाहते हैं, तो आपtfds.features.Scalar(tf.int64, doc='description')भी उपयोग कर सकते हैं। -
tfds.features.Audio,tfds.features.Video,... (उपलब्ध सुविधाओं की सूची देखें) - सुविधाओं का नेस्टेड
dict:{'metadata': {'image': Image(), 'description': tf.string} },... - नेस्टेड
tfds.features.Sequence:Sequence({'image': ..., 'id': ...}),Sequence(Sequence(tf.int64)),...
पीढ़ी के दौरान, उदाहरणों को FeatureConnector.encode_example द्वारा डिस्क के लिए उपयुक्त प्रारूप में स्वचालित रूप से क्रमबद्ध किया जाएगा (वर्तमान में tf.train.Example प्रोटोकॉल बफ़र्स):
yield {
'image': '/path/to/img0.png', # `np.array`, file bytes,... also accepted
'label': 'yes', # int (0-num_classes) also accepted
'metadata': {
'id': 43,
'language': 'en',
},
}
डेटासेट को पढ़ते समय (उदाहरण के लिए tfds.load के साथ), डेटा स्वचालित रूप से FeatureConnector.decode_example के साथ डिकोड हो जाता है। लौटाया गया tf.data.Dataset tfds.core.DatasetInfo में परिभाषित dict संरचना से मेल खाएगा:
ds = tfds.load(...)
ds.element_spec == {
'image': tf.TensorSpec(shape=(28, 28, 1), tf.uint8),
'label': tf.TensorSpec(shape=(), tf.int64),
'metadata': {
'id': tf.TensorSpec(shape=(), tf.int64),
'language': tf.TensorSpec(shape=(), tf.string),
},
}
प्रोटो को क्रमबद्ध/डीक्रमीकृत करें
TFDS, tf.train.Example proto में उदाहरणों को क्रमबद्ध/deserialize करने के लिए एक निम्न-स्तरीय API को उजागर करता है।
dict[np.ndarray | Path | str | ...] को क्रमबद्ध करने के लिए dict[np.ndarray | Path | str | ...] प्रोटो bytes के लिए, features.serialize_example उपयोग करें:
with tf.io.TFRecordWriter('path/to/file.tfrecord') as writer:
for ex in all_exs:
ex_bytes = features.serialize_example(data)
f.write(ex_bytes)
tf.Tensor पर प्रोटो bytes को डीसेरिएलाइज़ करने के लिए, features.deserialize_example उपयोग करें:
ds = tf.data.TFRecordDataset('path/to/file.tfrecord')
ds = ds.map(features.deserialize_example)
मेटाडेटा तक पहुंचें
फीचर मेटाडेटा (लेबल नाम, आकार, डीटाइप,...) तक पहुंचने के लिए परिचय दस्तावेज़ देखें। उदाहरण:
ds, info = tfds.load(..., with_info=True)
info.features['label'].names # ['cat', 'dog', ...]
info.features['label'].str2int('cat') # 0
अपना स्वयं का tfds.features.FeatureConnector बनाएं
यदि आपको लगता है कि उपलब्ध सुविधाओं में से कोई सुविधा गायब है, तो कृपया एक नया अंक खोलें।
अपना स्वयं का फीचर कनेक्टर बनाने के लिए, आपको tfds.features.FeatureConnector से इनहेरिट करना होगा और अमूर्त तरीकों को लागू करना होगा।
- यदि आपकी सुविधा एकल टेंसर मान है, तो
tfds.features.Tensorसे प्राप्त करना और आवश्यकता पड़ने परsuper()का उपयोग करना सबसे अच्छा है। उदाहरण के लिएtfds.features.BBoxFeatureस्रोत कोड देखें। - यदि आपकी सुविधा कई टेंसरों का एक कंटेनर है, तो
tfds.features.FeaturesDictसे इनहेरिट करना और उप-कनेक्टरों को स्वचालित रूप से एन्कोड करने के लिएsuper()उपयोग करना सबसे अच्छा है।
tfds.features.FeatureConnector ऑब्जेक्ट यह बताता है कि डिस्क पर फीचर को कैसे एन्कोड किया गया है और इसे उपयोगकर्ता के सामने कैसे प्रस्तुत किया जाता है। नीचे एक आरेख है जो डेटासेट की अमूर्त परतों और कच्चे डेटासेट फ़ाइलों से tf.data.Dataset ऑब्जेक्ट में परिवर्तन को दर्शाता है।
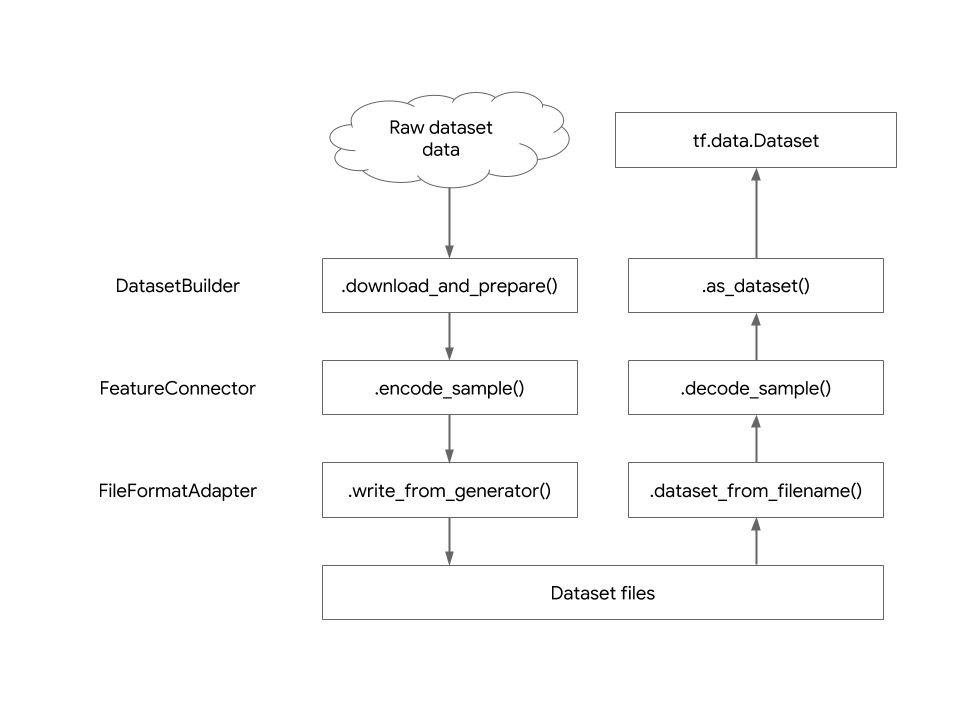
अपना स्वयं का फीचर कनेक्टर बनाने के लिए, tfds.features.FeatureConnector उपवर्गित करें और अमूर्त तरीकों को लागू करें:
-
encode_example(data): यह परिभाषित करता है कि जनरेटर_generate_examples()में दिए गए डेटा कोtf.train.Exampleसंगत डेटा में कैसे एन्कोड किया जाए। एकल मान, या मानों का एकdictलौटा सकता है। -
decode_example(data): परिभाषित करता है किtf.train.Exampleसे पढ़े गए टेंसर से डेटा कोtf.data.Datasetद्वारा लौटाए गए उपयोगकर्ता टेंसर में कैसे डिकोड किया जाए। -
get_tensor_info():tf.data.Datasetद्वारा लौटाए गए टेंसर के आकार/dtype को इंगित करता है। यदि किसी अन्यtfds.featuresसे विरासत में मिला है तो यह वैकल्पिक हो सकता है। - (वैकल्पिक रूप से)
get_serialized_info(): यदिget_tensor_info()द्वारा लौटाई गई जानकारी वास्तव में डिस्क पर डेटा लिखे जाने के तरीके से भिन्न है, तो आपकोtf.train.Exampleके विनिर्देशों से मिलान करने के लिएget_serialized_info()अधिलेखित करना होगा। -
to_json_content/from_json_content: आपके डेटासेट को मूल स्रोत कोड के बिना लोड करने की अनुमति देने के लिए यह आवश्यक है। उदाहरण के लिए ऑडियो सुविधा देखें.
अधिक जानकारी के लिए, tfds.features.FeatureConnector दस्तावेज़ पर एक नज़र डालें। वास्तविक उदाहरणों को देखना भी सर्वोत्तम है।