
- 설명 :
이 데이터세트는 주로 AI2D 데이터세트를 기반으로 합니다( 여기 참조).
AI2D-Caption 데이터 세트 주석 프로세스에 대해서는 논문의 섹션 4.1을 참조하세요.
홈페이지 : https://huggingface.co/datasets/abhayzala/AI2D-Caption
버전 :
-
1.0.0(기본값): 최초 릴리스입니다.
-
다운로드 크기 :
Unknown size데이터세트 크기 :
2.01 GiB자동 캐시 ( 문서 ): 아니요
분할 :
| 나뉘다 | 예 |
|---|---|
'auditor_llm_training_examples' | 30 |
'gpt4v' | 4,903 |
'llava_15' | 4,902 |
'planner_llm_training_examples' | 30 |
'test' | 75 |
- 기능 구조 :
FeaturesDict({
'caption': Text(shape=(), dtype=string),
'entities': Sequence({
'bounds': BBoxFeature(shape=(4,), dtype=float32),
'cat': ClassLabel(shape=(), dtype=int64, num_classes=10),
'from': Text(shape=(), dtype=string),
'id': Text(shape=(), dtype=string),
'label': Text(shape=(), dtype=string),
'to': Text(shape=(), dtype=string),
'type': ClassLabel(shape=(), dtype=int64, num_classes=5),
}),
'image': Image(shape=(None, None, 3), dtype=uint8, description=The image of the diagram.),
'image_filename': Text(shape=(), dtype=string),
'layout': ClassLabel(shape=(), dtype=int64, num_classes=7),
'relationships': Sequence(Text(shape=(), dtype=string)),
'topic': ClassLabel(shape=(), dtype=int64, num_classes=4),
})
- 기능 문서 :
| 특징 | 수업 | 모양 | Dtype | 설명 |
|---|---|---|---|---|
| 특징Dict | ||||
| 표제 | 텍스트 | 끈 | ||
| 엔터티 | 순서 | |||
| 엔터티/경계 | B박스특징 | (4,) | float32 | |
| 엔터티/고양이 | 클래스 라벨 | 정수64 | ||
| 엔터티/에서 | 텍스트 | 끈 | ||
| 엔터티/ID | 텍스트 | 끈 | ||
| 엔터티/라벨 | 텍스트 | 끈 | ||
| 엔터티/대상 | 텍스트 | 끈 | ||
| 엔터티/유형 | 클래스 라벨 | 정수64 | ||
| 영상 | 영상 | (없음, 없음, 3) | uint8 | 다이어그램의 이미지입니다. |
| 이미지_파일 이름 | 텍스트 | 끈 | 이미지 파일 이름. 예: "1337.png" | |
| 공들여 나열한 것 | 클래스 라벨 | 정수64 | ||
| 관계 | 시퀀스(텍스트) | (없음,) | 끈 | |
| 주제 | 클래스 라벨 | 정수64 |
감독되는 키 (
as_superviseddoc 참조):None그림 ( tfds.show_examples ):
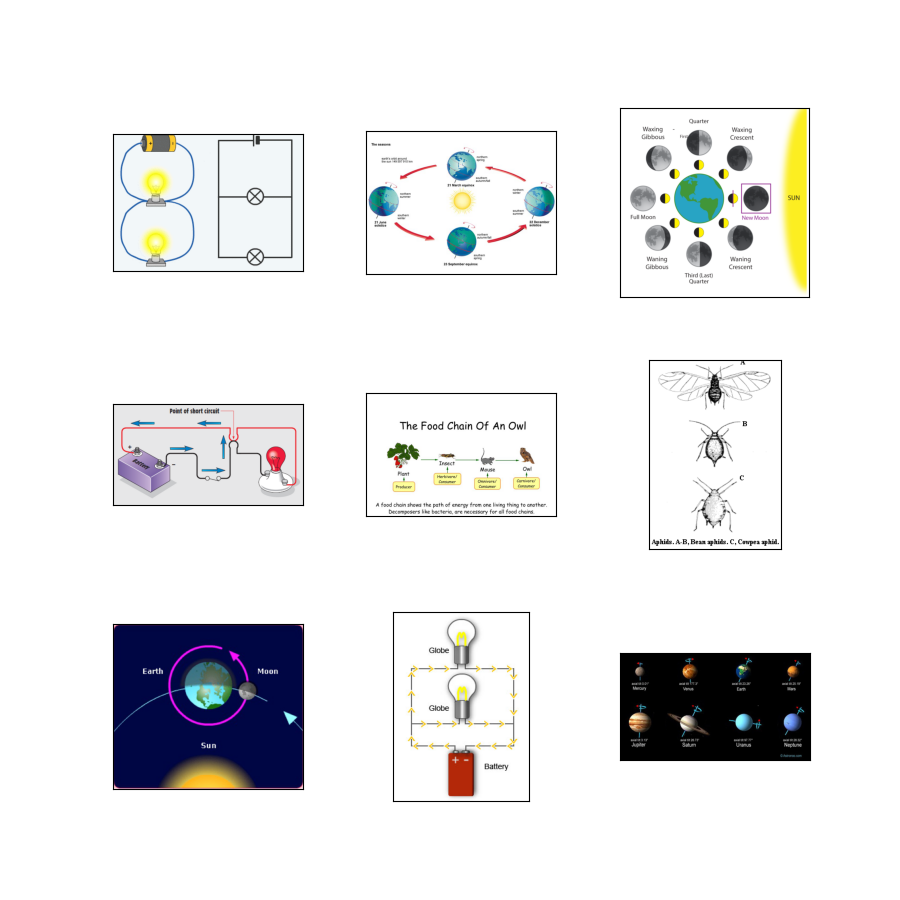
- 예 ( tfds.as_dataframe ):
- 인용 :
@inproceedings{Zala2024DiagrammerGPT,
author = {Abhay Zala and Han Lin and Jaemin Cho and Mohit Bansal},
title = {DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning},
year = {2024},
booktitle = {COLM},
}