
Copyright 2021 Autorzy TF-Agents.
Zaczynaj
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek jest przewodnikiem krok po kroku, jak korzystać z biblioteki TF-Agents w kontekście problemów z bandytami, w których akcje (ramiona) mają swoje własne cechy, takie jak lista filmów reprezentowanych przez funkcje (gatunek, rok wydania, ...).
Warunek wstępny
Zakłada się, że czytelnik jest nieco zaznajomieni z biblioteki Bandit z TF-pełnomocników, w szczególności pracował przez samouczek dla bandytów w TF-pełnomocników przed przeczytaniem tego samouczka.
Wieloręcy bandyci z funkcjami ramion
W „klasycznym” ustawieniu kontekstowych wielorękich bandytów agent otrzymuje wektor kontekstu (inaczej obserwację) na każdym kroku czasowym i musi wybierać spośród skończonego zestawu ponumerowanych akcji (ramion), aby zmaksymalizować swoją skumulowaną nagrodę.
Rozważmy teraz scenariusz, w którym agent poleca użytkownikowi następny film do obejrzenia. Za każdym razem, gdy trzeba podjąć decyzję, agent otrzymuje jako kontekst informacje o użytkowniku (historię oglądania, preferencje gatunkowe itp.), a także listę filmów do wyboru.
Mogliśmy spróbować sformułować ten problem poprzez dane użytkownika, zależnie od kontekstu, a ramiona byłoby movie_1, movie_2, ..., movie_K , ale takie podejście ma kilka niedociągnięć:
- Liczba akcji musiałaby obejmować wszystkie filmy w systemie, a dodanie nowego filmu jest kłopotliwe.
- Agent musi nauczyć się modelu do każdego filmu.
- Podobieństwo między filmami nie jest brane pod uwagę.
Zamiast numerować filmy, możemy zrobić coś bardziej intuicyjnego: możemy reprezentować filmy z zestawem funkcji, w tym gatunkiem, długością, obsadą, oceną, rokiem itp. Zalety tego podejścia są wielorakie:
- Uogólnienie w filmach.
- Agent uczy się tylko jednej funkcji nagradzania, która modeluje nagrodę za pomocą funkcji użytkownika i filmu.
- Łatwe do usunięcia lub wprowadzenia nowych filmów do systemu.
W tym nowym ustawieniu liczba czynności nie musi być nawet taka sama w każdym kroku czasowym.
Bandyci na rękę w agentach TF
Pakiet TF-Agents Bandit został opracowany tak, aby można go było używać również do etui na ramię. Istnieją środowiska na ramię, a także większość zasad i agentów może działać w trybie na ramię.
Zanim zagłębimy się w kodowanie przykładu, potrzebujemy niezbędnych importów.
Instalacja
pip install tf-agents
Import
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Parametry-zapraszam do zabawy
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
Proste środowisko na ramię
Nieruchoma stochastyczny środowisko wyjaśniono w pozostałych poradniku ma odpowiednika za ramieniem.
Aby zainicjować środowisko na ramię, należy zdefiniować funkcje, które generują
- globalne i funkcje za ramię: Funkcje te nie mają parametry wejściowe i generuje pojedynczy (globalne lub per-ramię) wektora cech kiedy dzwonił.
- nagrody: Funkcja ta przyjmuje jako parametr konkatenacji globalnego i wektor cech za ramię i generuje nagrodę. Zasadniczo jest to funkcja, którą agent będzie musiał „odgadnąć”. Warto tutaj zauważyć, że w przypadku na ramię funkcja nagrody jest identyczna dla każdego ramienia. Jest to zasadnicza różnica w porównaniu z klasycznym przypadkiem bandytów, w którym agent musi oszacować funkcje nagrody niezależnie dla każdego ramienia.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Teraz jesteśmy przygotowani do inicjalizacji naszego środowiska.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
Poniżej możemy sprawdzić, co produkuje to środowisko.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
Widzimy, że specyfikacja obserwacji jest słownikiem składającym się z dwóch elementów:
- Jeden z kluczem
'global': jest to część globalnego kontekstu, z kształtu dopasowanie parametrówGLOBAL_DIM. - Jeden z kluczem
'per_arm': jest to kontekst za ramię, a jego kształt jest[NUM_ACTIONS, PER_ARM_DIM]. Ta część jest miejscem zastępczym dla funkcji ramienia dla każdego ramienia w kroku czasowym.
Agent LinUCB
Agent LinUCB implementuje identycznie nazwany algorytm Bandit, który szacuje parametr liniowej funkcji nagrody, jednocześnie utrzymując elipsoidę ufności wokół oszacowania. Agent wybiera ramię, które ma najwyższą oszacowaną oczekiwaną nagrodę, zakładając, że parametr mieści się w elipsoidzie ufności.
Stworzenie agenta wymaga znajomości obserwacji i specyfikacji działania. Przy określaniu środka, możemy ustawić parametr logiczna accepts_per_arm_features ustawiona na True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
Przepływ danych treningowych
Ta sekcja daje wgląd w mechanikę, w jaki sposób funkcje poszczególnych ramion przechodzą od zasad do treningu. Możesz przejść do następnej sekcji (Definiowanie wskaźnika żalu) i wrócić tutaj później, jeśli jesteś zainteresowany.
Najpierw spójrzmy na specyfikację danych w agencie. training_data_spec atrybutem Określa agenta, jakie elementy i struktury danych szkolenia powinien mieć.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
Jeśli mamy bliżej do observation części specyfikacji, widzimy, że nie zawiera on funkcje za ramię!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
Co się stało z funkcjami na ramię? Aby odpowiedzieć na to pytanie, należy najpierw zauważyć, że gdy pociągi agenta LinUCB, że nie potrzebuje funkcji per-ramienia wszystkich ramion, tylko potrzebuje tych wybranego ramienia. W związku z tym, warto spadek tensor kształtu [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , ponieważ jest bardzo marnotrawstwem, szczególnie jeśli ilość działań jest duży.
Ale wciąż muszą gdzieś być cechy poszczególnych ramion wybranego ramienia! W związku z tym, mamy pewność, że w sklepach polityki LinUCB cechy wybranego ramienia w policy_info polu danych treningowych:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
Widzimy od kształtu że chosen_arm_features pole ma tylko wektor cech jednym ramieniu, i że będzie wybrany ramię. Zauważ, że policy_info , a wraz z nim chosen_arm_features jest częścią danych treningowych, jak widzieliśmy z inspekcji danych specyfikację szkolenia, a więc jest ona dostępna w czasie treningu.
Definiowanie miernika żalu
Przed rozpoczęciem pętli szkoleniowej definiujemy kilka funkcji użytkowych, które pomagają obliczyć żal naszego agenta. Funkcje te pomagają określić optymalną oczekiwaną nagrodę, biorąc pod uwagę zestaw działań (podawany przez cechy ramienia) oraz parametr liniowy, który jest ukryty przed agentem.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Teraz wszyscy jesteśmy gotowi do rozpoczęcia naszej pętli treningowej bandytów. Poniższy sterownik zajmuje się wyborem działań za pomocą polityki, przechowywaniem nagród za wybrane działania w buforze powtórek, obliczaniem predefiniowanej metryki żalu i wykonywaniem etapu szkolenia agenta.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
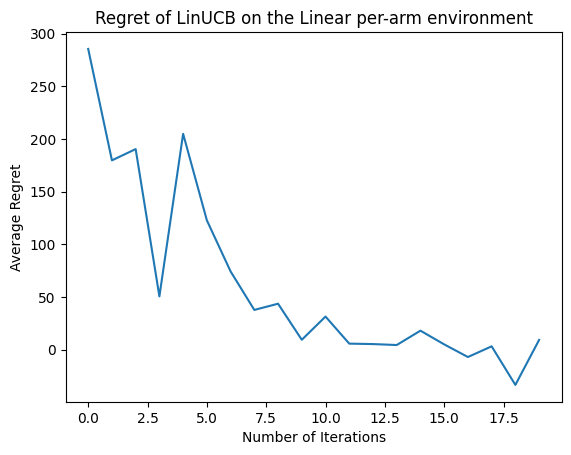
Zobaczmy teraz wynik. Jeśli zrobiliśmy wszystko dobrze, agent jest w stanie dobrze oszacować liniową funkcję nagrody, a tym samym polityka może wybrać działania, których oczekiwana nagroda jest zbliżona do optymalnej. Wskazuje na to nasza zdefiniowana powyżej metryka żalu, która spada i zbliża się do zera.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
Co dalej?
Powyższy przykład jest realizowany w naszym kodzie, gdzie można wybierać spośród innych środków, jak również, w tym epsilon-Greedy agenta Neural .