
Copyright 2021 TF 에이전트 작성자.
시작하다
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
이 튜토리얼은 액션(팔)이 기능(장르, 출시 연도, ...).
전제 조건
그것은 독자가 TF-에이전트의 도적 라이브러리 어느 정도 알고 있다고 가정한다, 특히 통해 일했다 TF-에이전트에 도둑에 대한 튜토리얼 이 튜토리얼을 읽기 전에.
팔 기능이 있는 다중 팔 도적
"클래식" Contextual Multi-Armed Bandits 설정에서 에이전트는 모든 시간 단계에서 컨텍스트 벡터(관찰이라고도 함)를 수신하고 누적 보상을 최대화하기 위해 유한한 일련의 번호가 지정된 작업(암) 중에서 선택해야 합니다.
이제 에이전트가 사용자에게 다음에 볼 영화를 추천하는 시나리오를 고려하십시오. 결정을 내려야 할 때마다 에이전트는 사용자에 대한 일부 정보(시청 기록, 장르 선호도 등...)와 선택할 영화 목록을 컨텍스트로 받습니다.
우리는 환경과 사용자 정보를함으로써이 문제를 공식화을 시도 할 수 있습니다와 팔 것 movie_1, movie_2, ..., movie_K 하지만,이 방법은 여러 단점이있다 :
- 작업의 수는 시스템의 모든 영화여야 하며 새 영화를 추가하는 것은 번거롭습니다.
- 에이전트는 모든 단일 영화에 대한 모델을 학습해야 합니다.
- 영화 간의 유사성은 고려되지 않습니다.
영화에 번호를 매기는 대신 더 직관적인 작업을 수행할 수 있습니다. 장르, 길이, 출연진, 등급, 연도 등을 포함하는 일련의 기능으로 영화를 나타낼 수 있습니다. 이 접근 방식의 장점은 다양합니다.
- 영화 전반에 걸친 일반화.
- 에이전트는 사용자 및 영화 기능으로 보상을 모델링하는 하나의 보상 함수만 학습합니다.
- 시스템에서 쉽게 제거하거나 새 영화를 도입할 수 있습니다.
이 새로운 설정에서는 작업 수가 모든 시간 단계에서 동일할 필요도 없습니다.
TF 에이전트의 팔당 도적
TF-Agents Bandit Suite는 팔당 케이스에도 사용할 수 있도록 개발되었습니다. per-arm 환경이 있으며 대부분의 정책 및 에이전트는 per-arm 모드에서 작동할 수 있습니다.
예제 코딩에 뛰어들기 전에 필수 수입품이 필요합니다.
설치
pip install tf-agents
수입품
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
매개변수 -- 자유롭게 놀아보세요.
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
간단한 팔당 환경
고정 확률 환경이 다른 설명 가이드 , 당 아암 대응을 갖는다.
팔당 환경을 초기화하려면 다음을 생성하는 함수를 정의해야 합니다.
- 글로벌 및 당 팔 기능 :이 기능은 입력 매개 변수가 없으며라고 할 때 (전역 또는 당 암) 하나의 특징 벡터를 생성합니다.
- 보상 :이 기능은 글로벌 및 당 암 특징 벡터의 연결 매개 변수로 받아, 보상을 생성합니다. 기본적으로 이것은 에이전트가 "추측"해야 하는 기능입니다. 팔당 보상 기능이 모든 팔에 대해 동일하다는 점은 여기서 주목할 가치가 있습니다. 이것은 에이전트가 각 팔에 대한 보상 기능을 독립적으로 추정해야 하는 기존의 bandit 사례와 근본적인 차이점입니다.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
이제 환경을 초기화할 준비가 되었습니다.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
아래에서 이 환경이 생성하는 것을 확인할 수 있습니다.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
관찰 사양은 두 가지 요소가 있는 사전임을 알 수 있습니다.
- 키 하나는
'global':이 형상 파라미터 매칭에, 글로벌 문맥 부분GLOBAL_DIM. - 키 하나
'per_arm':이 당 아암 상황이고, 그 형상은[NUM_ACTIONS, PER_ARM_DIM]. 이 부분은 시간 단계의 모든 팔에 대한 팔 기능에 대한 자리 표시자입니다.
LinUCB 에이전트
LinUCB 에이전트는 선형 보상 함수의 매개변수를 추정하는 동시에 추정치에 대한 신뢰 타원체를 유지하는 동일한 이름의 Bandit 알고리즘을 구현합니다. 에이전트는 매개변수가 신뢰 타원체 내에 있다고 가정하고 예상 보상이 가장 높은 팔을 선택합니다.
에이전트를 생성하려면 관찰 및 작업 사양에 대한 지식이 필요합니다. 에이전트를 정의 할 때, 우리는 부울 매개 변수가 설정 accepts_per_arm_features 로 설정 True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
훈련 데이터의 흐름
이 섹션에서는 팔당 기능이 정책에서 교육으로 이동하는 방법에 대한 역학을 살짝 엿볼 수 있습니다. 다음 섹션(후회 지표 정의)으로 자유롭게 이동하고 관심이 있는 경우 나중에 여기로 돌아오십시오.
먼저 에이전트의 데이터 사양을 살펴보겠습니다. training_data_spec 학습 데이터가 있어야 어떤 구조 요소 및 에이전트의 속성을 지정.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
우리가에 대한 면밀한 관찰이있는 경우 observation 사양의 일부를, 우리는 당 팔 기능을 포함하지 않는 것을 볼!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
팔당 기능은 어떻게 되었습니까? 이 질문에 대답하려면 먼저 우리는 LinUCB 에이전트 열차, 모든 무기의 당 팔 기능이 필요하지 않을 때, 그것은 단지 선택된 암의 사람들을 필요가 있습니다. 따라서, 모양의 텐서 드롭 말이 [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] 그 작업의 수가 많은 경우에는 특히 매우 낭비로.
그러나 여전히 선택한 팔의 팔당 기능은 어딘가에 있어야 합니다! 이를 위해, 우리는 확실히 만드는 LinUCB 정책을 저장 그 내에서 선택된 팔의 기능 policy_info 학습 데이터의 필드 :
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
우리는 그 모양에서 볼 chosen_arm_features 필드가 한 팔의 특징 벡터를 가지고 있으며, 그 선택된 팔 수 있습니다. 있습니다 policy_info 하고, 그것으로 chosen_arm_features 우리가 훈련 데이터 사양 검사에서 본 바와 같이, 학습 데이터의 일부이며, 따라서 교육시에 사용할 수 있습니다.
후회 지표 정의
훈련 루프를 시작하기 전에 에이전트의 후회를 계산하는 데 도움이 되는 몇 가지 유틸리티 함수를 정의합니다. 이러한 기능은 일련의 동작(팔 기능에 의해 제공됨)과 에이전트에서 숨겨진 선형 매개변수가 주어지면 최적의 예상 보상을 결정하는 데 도움이 됩니다.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
이제 우리는 적기 훈련 루프를 시작할 준비가 되었습니다. 아래의 드라이버는 정책을 사용하여 작업을 선택하고, 선택한 작업의 보상을 재생 버퍼에 저장하고, 미리 정의된 후회 메트릭을 계산하고, 에이전트의 훈련 단계를 실행하는 작업을 처리합니다.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
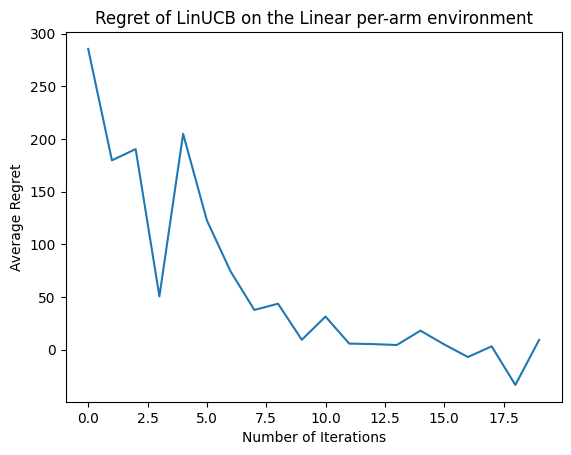
이제 결과를 봅시다. 우리가 모든 것을 올바르게했다면 에이전트는 선형 보상 함수를 잘 추정할 수 있으므로 정책은 예상 보상이 최적의 보상에 가까운 조치를 선택할 수 있습니다. 이는 위에서 정의한 후회 메트릭으로 표시되며, 이는 내려가서 0에 접근합니다.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
무엇 향후 계획?
위의 예입니다 구현 당신이 포함뿐만 아니라 다른 에이전트에서 선택할 수있는 우리의 코드베이스에 신경 엡실론 - 욕심 에이전트 .