
Copyright 2021 Gli autori degli agenti TF.
Iniziare
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Questo tutorial è una guida passo passo su come utilizzare la libreria TF-Agents per problemi di banditi contestuali in cui le azioni (braccia) hanno le loro caratteristiche, come un elenco di film rappresentati da caratteristiche (genere, anno di uscita, ...).
Prerequisito
Si presume che il lettore abbia una certa familiarità con la libreria Bandit di TF-agenti, in particolare, ha lavorato attraverso il tutorial per Banditi a TF-Agenti prima di leggere questo tutorial.
Banditi multi-armati con caratteristiche del braccio
Nell'impostazione "classica" Contestuale Multi-Armed Bandits, un agente riceve un vettore di contesto (noto anche come osservazione) ad ogni passaggio temporale e deve scegliere da un insieme finito di azioni numerate (braccia) in modo da massimizzare la sua ricompensa cumulativa.
Consideriamo ora lo scenario in cui un agente consiglia a un utente il prossimo film da guardare. Ogni volta che deve essere presa una decisione, l'agente riceve come contesto alcune informazioni sull'utente (cronologia visualizzazioni, preferenza di genere, ecc...), nonché l'elenco dei film tra cui scegliere.
Potremmo provare a formulare questo problema facendo le informazioni utente come il contesto e le braccia sarebbe movie_1, movie_2, ..., movie_K , ma questo approccio ha molteplici carenze:
- Il numero di azioni dovrebbe essere tutti i film nel sistema ed è complicato aggiungere un nuovo film.
- L'agente deve imparare un modello per ogni singolo film.
- La somiglianza tra i film non viene presa in considerazione.
Invece di numerare i film, possiamo fare qualcosa di più intuitivo: possiamo rappresentare i film con una serie di caratteristiche tra cui genere, lunghezza, cast, valutazione, anno, ecc. I vantaggi di questo approccio sono molteplici:
- Generalizzazione tra i film.
- L'agente apprende solo una funzione di ricompensa che modella la ricompensa con le caratteristiche dell'utente e del film.
- Facile da rimuovere o introdurre nuovi filmati nel sistema.
In questa nuova impostazione, il numero di azioni non deve nemmeno essere lo stesso in ogni fase temporale.
Banditi Per-Arm in TF-Agenti
La suite TF-Agents Bandit è sviluppata in modo da poterla utilizzare anche per la custodia per braccio. Esistono ambienti per braccio e anche la maggior parte dei criteri e degli agenti può funzionare in modalità per braccio.
Prima di immergerci nella codifica di un esempio, abbiamo bisogno delle importazioni necessarie.
Installazione
pip install tf-agents
Importazioni
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Parametri -- Sentiti libero di giocare
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
Un semplice ambiente per braccio
L'ambiente stocastico stazionario, spiegato nell'altro esercitazione , ha una controparte per-braccio.
Per inizializzare l'ambiente per-arm, si devono definire funzioni che generano
- globale e caratteristiche per-braccio: Queste funzioni non hanno parametri di input e generano una singola (globale o per braccio) vettore di caratteristiche quando viene chiamato.
- premia: Questa funzione prende come parametro la concatenazione di un globale e una funzione di vettore per-braccio, e genera una ricompensa. Fondamentalmente questa è la funzione che l'agente dovrà "indovinare". Vale la pena notare qui che nel caso per braccio la funzione di ricompensa è identica per ogni braccio. Questa è una differenza fondamentale rispetto al classico caso del bandito, in cui l'agente deve stimare le funzioni di ricompensa per ciascun braccio in modo indipendente.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Ora siamo attrezzati per inizializzare il nostro ambiente.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
Di seguito possiamo verificare cosa produce questo ambiente.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
Vediamo che la specifica di osservazione è un dizionario con due elementi:
- Uno con il tasto
'global': questa è la parte globale contesto, con la forma corrispondente al parametroGLOBAL_DIM. - Uno con il tasto
'per_arm': questo è il contesto per-braccio, e la sua forma è[NUM_ACTIONS, PER_ARM_DIM]. Questa parte è il segnaposto per le caratteristiche del braccio per ogni braccio in una fase temporale.
L'agente LinUCB
L'agente LinUCB implementa l'algoritmo Bandit dal nome identico, che stima il parametro della funzione di ricompensa lineare mantenendo anche un ellissoide di confidenza attorno alla stima. L'agente sceglie il braccio che ha la più alta ricompensa attesa stimata, assumendo che il parametro rientri nell'ellissoide di confidenza.
La creazione di un agente richiede la conoscenza dell'osservazione e della specifica dell'azione. Quando si definisce l'agente, abbiamo impostato il parametro booleano accepts_per_arm_features impostato su True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
Il flusso dei dati di allenamento
Questa sezione offre un'anteprima dei meccanismi di come le funzionalità per braccio passano dalla politica alla formazione. Sentiti libero di passare alla sezione successiva (Definizione della metrica del rimpianto) e torna qui più tardi se interessati.
Innanzitutto, diamo un'occhiata alla specifica dei dati nell'agente. La training_data_spec attributo degli specifica dell'agente quali elementi e strutturare i dati formazione dovrebbe avere.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
Se abbiamo uno sguardo più attento alla observation parte della specifica, vediamo che esso non contiene funzioni per-braccio!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
Cosa è successo alle caratteristiche per braccio? Per rispondere a questa domanda, in primo luogo notiamo che quando i treni agente LinUCB, non ha bisogno di caratteristiche per-braccio di tutte le armi, ha bisogno solo quelli del braccio prescelto. Quindi, ha senso far cadere il tensore di forma [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , in quanto è molto dispendioso, soprattutto se il numero di azioni è grande.
Tuttavia, le caratteristiche per braccio del braccio scelto devono essere da qualche parte! A tal fine, ci assicuriamo che i negozi di politica LinUCB le caratteristiche del braccio scelto entro il policy_info campo dei dati di allenamento:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
Vediamo dalla forma che il chosen_arm_features campo ha solo la funzione di vettore di un braccio, e che sarà il braccio prescelto. Si noti che il policy_info , e con essa i chosen_arm_features , fa parte dei dati di allenamento, come abbiamo visto da ispezionare le specifiche dei dati di formazione, e quindi è disponibile in fase di formazione.
Definire la metrica del rimpianto
Prima di avviare il ciclo di addestramento, definiamo alcune funzioni di utilità che aiutano a calcolare il rimpianto del nostro agente. Queste funzioni aiutano a determinare la ricompensa attesa ottimale dato l'insieme di azioni (dato dalle caratteristiche del loro braccio) e il parametro lineare che è nascosto all'agente.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Ora siamo pronti per iniziare il nostro ciclo di addestramento dei banditi. Il driver di seguito si occupa della scelta delle azioni utilizzando la policy, dell'archiviazione dei premi delle azioni scelte nel buffer di riproduzione, del calcolo della metrica di rammarico predefinita e dell'esecuzione della fase di addestramento dell'agente.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
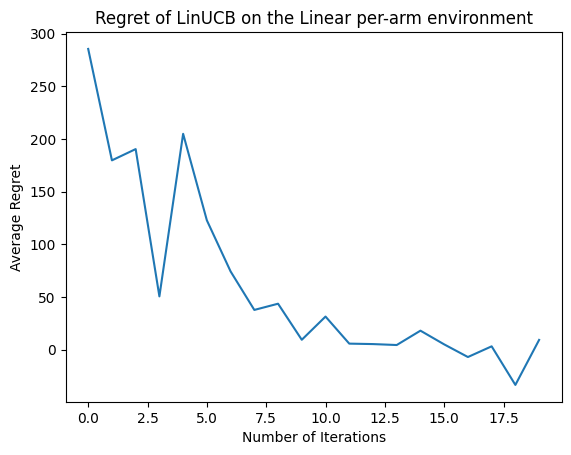
Ora vediamo il risultato. Se abbiamo fatto tutto bene, l'agente è in grado di stimare bene la funzione di ricompensa lineare, e quindi la politica può scegliere azioni la cui ricompensa attesa è vicina a quella dell'ottimale. Questo è indicato dalla nostra metrica di rammarico sopra definita, che scende e si avvicina allo zero.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
Qual è il prossimo?
L'esempio di cui sopra è implementato nel nostro codice di base in cui è possibile scegliere tra altri agenti come pure, tra l' agente di epsilon-Greedy neurale .