
Hak Cipta 2021 The TF-Agents Authors.
Memulai
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini adalah panduan langkah demi langkah tentang cara menggunakan perpustakaan TF-Agents untuk masalah bandit kontekstual di mana tindakan (lengan) memiliki fitur sendiri, seperti daftar film yang diwakili oleh fitur (genre, tahun rilis, ...).
Prasyarat
Hal ini diasumsikan bahwa pembaca agak akrab dengan perpustakaan Bandit dari TF-Agen, khususnya, telah bekerja melalui tutorial untuk Bandits di TF-Agen sebelum membaca tutorial ini.
Bandit Multi-Bersenjata dengan Fitur Lengan
Dalam pengaturan Bandit Multi-Bersenjata Kontekstual "klasik", seorang agen menerima vektor konteks (alias observasi) pada setiap langkah waktu dan harus memilih dari serangkaian tindakan bernomor (senjata) yang terbatas untuk memaksimalkan imbalan kumulatifnya.
Sekarang pertimbangkan skenario di mana agen merekomendasikan kepada pengguna film berikutnya untuk ditonton. Setiap kali keputusan harus dibuat, agen menerima sebagai konteks beberapa informasi tentang pengguna (riwayat tontonan, preferensi genre, dll...), serta daftar film untuk dipilih.
Kita bisa mencoba merumuskan masalah ini dengan memiliki informasi pengguna sebagai konteks dan lengan akan movie_1, movie_2, ..., movie_K , tetapi pendekatan ini memiliki beberapa kekurangan:
- Jumlah tindakan harus semua film dalam sistem dan tidak praktis untuk menambahkan film baru.
- Agen harus mempelajari model untuk setiap film.
- Kesamaan antara film tidak diperhitungkan.
Alih-alih menomori film, kita dapat melakukan sesuatu yang lebih intuitif: kita dapat merepresentasikan film dengan serangkaian fitur termasuk genre, durasi, pemeran, peringkat, tahun, dll. Keuntungan dari pendekatan ini bermacam-macam:
- Generalisasi di seluruh film.
- Agen hanya mempelajari satu fungsi hadiah yang memodelkan hadiah dengan fitur pengguna dan film.
- Mudah untuk menghapus, atau memperkenalkan film baru ke sistem.
Dalam pengaturan baru ini, jumlah tindakan bahkan tidak harus sama di setiap langkah waktu.
Bandit Per-Lengan di TF-Agents
TF-Agents Bandit suite dikembangkan sehingga seseorang dapat menggunakannya untuk kasus per-lengan juga. Ada lingkungan per-arm, dan juga sebagian besar kebijakan dan agen dapat beroperasi dalam mode per-arm.
Sebelum kita menyelami contoh pengkodean, kita membutuhkan impor yang diperlukan.
Instalasi
pip install tf-agents
Impor
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Parameter -- Jangan Ragu untuk Bermain-main
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
Lingkungan Per-Lengan Sederhana
Lingkungan stokastik stasioner, menjelaskan yang lain tutorial , memiliki rekan per-arm.
Untuk menginisialisasi lingkungan per-arm, kita harus mendefinisikan fungsi yang menghasilkan
- global dan fitur per-lengan: Fungsi-fungsi ini tidak memiliki parameter input dan menghasilkan vektor fitur tunggal (global atau per-arm) saat dipanggil.
- penghargaan: Fungsi ini mengambil sebagai parameter gabungan dari fitur vektor per-lengan global dan, dan menghasilkan hadiah. Pada dasarnya ini adalah fungsi yang harus "ditebak" oleh agen. Perlu dicatat di sini bahwa dalam kasus per-lengan, fungsi hadiah identik untuk setiap lengan. Ini adalah perbedaan mendasar dari kasus bandit klasik, di mana agen harus memperkirakan fungsi hadiah untuk setiap lengan secara independen.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Sekarang kita diperlengkapi untuk menginisialisasi lingkungan kita.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
Di bawah ini kita dapat memeriksa apa yang dihasilkan oleh lingkungan ini.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
Kami melihat bahwa spec observasi adalah kamus dengan dua elemen:
- Satu dengan kunci
'global': ini adalah bagian konteks global, dengan bentuk yang cocok dengan parameterGLOBAL_DIM. - Satu dengan kunci
'per_arm': ini adalah konteks per-lengan, dan bentuknya[NUM_ACTIONS, PER_ARM_DIM]. Bagian ini adalah tempat untuk fitur lengan untuk setiap lengan dalam langkah waktu.
Agen LinUCB
Agen LinUCB mengimplementasikan algoritma Bandit dengan nama yang sama, yang memperkirakan parameter fungsi hadiah linier sambil juga mempertahankan elipsoid kepercayaan di sekitar perkiraan. Agen memilih lengan yang memiliki perkiraan hadiah tertinggi yang diharapkan, dengan asumsi bahwa parameternya terletak di dalam ellipsoid kepercayaan.
Membuat agen membutuhkan pengetahuan tentang observasi dan spesifikasi tindakan. Ketika mendefinisikan agen, kami mengatur parameter boolean accepts_per_arm_features diatur ke True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
Alur Data Pelatihan
Bagian ini memberikan pandangan sekilas tentang mekanisme bagaimana fitur per-lengan beralih dari kebijakan ke pelatihan. Jangan ragu untuk melompat ke bagian berikutnya (Mendefinisikan Metrik Penyesalan) dan kembali lagi ke sini nanti jika tertarik.
Pertama, mari kita lihat spesifikasi data di agen. The training_data_spec atribut dari menspesifikasikan agen apa unsur-unsur dan struktur data pelatihan harus memiliki.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
Jika kita melihat lebih dekat ke observation bagian dari spec, kita melihat bahwa itu tidak mengandung fitur per-lengan!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
Apa yang terjadi dengan fitur per-lengan? Untuk menjawab pertanyaan ini, pertama kita perhatikan bahwa ketika kereta agen LinUCB, tidak memerlukan fitur per-lengan semua senjata, hanya membutuhkan orang-orang dari lengan yang dipilih. Oleh karena itu, masuk akal untuk menjatuhkan tensor bentuk [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , karena sangat boros, terutama jika jumlah tindakan besar.
Tapi tetap saja, fitur per-lengan dari lengan yang dipilih pasti ada di suatu tempat! Untuk tujuan ini, kami memastikan bahwa toko kebijakan LinUCB fitur dari lengan yang dipilih dalam policy_info bidang data pelatihan:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
Kita melihat dari bentuk yang chosen_arm_features lapangan hanya memiliki vektor fitur satu lengan, dan itu akan menjadi lengan yang dipilih. Perhatikan bahwa policy_info , dan dengan itu chosen_arm_features , adalah bagian dari data pelatihan, seperti yang kita lihat dari memeriksa pelatihan Data spec, dan dengan demikian tersedia pada saat pelatihan.
Mendefinisikan Metrik Penyesalan
Sebelum memulai loop pelatihan, kami mendefinisikan beberapa fungsi utilitas yang membantu menghitung penyesalan agen kami. Fungsi-fungsi ini membantu menentukan imbalan optimal yang diharapkan dengan serangkaian tindakan (diberikan oleh fitur lengannya) dan parameter linier yang disembunyikan dari agen.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Sekarang kita siap untuk memulai lingkaran pelatihan bandit kita. Pengemudi di bawah ini menangani pemilihan tindakan menggunakan kebijakan, menyimpan hadiah tindakan yang dipilih dalam buffer pemutaran ulang, menghitung metrik penyesalan yang telah ditentukan, dan menjalankan langkah pelatihan agen.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
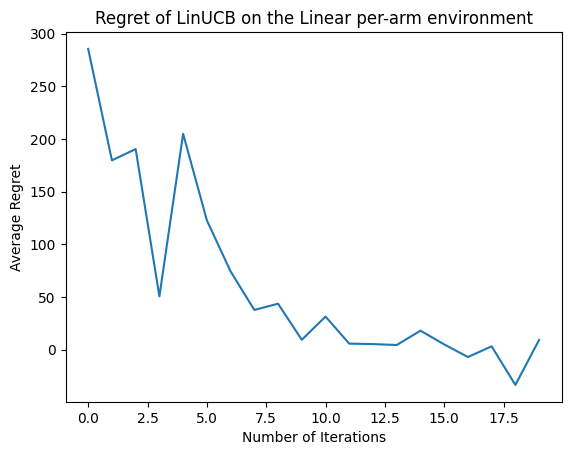
Sekarang mari kita lihat hasilnya. Jika kami melakukan semuanya dengan benar, agen dapat memperkirakan fungsi imbalan linier dengan baik, dan dengan demikian kebijakan dapat memilih tindakan yang imbalan yang diharapkan mendekati yang optimal. Ini ditunjukkan oleh metrik penyesalan yang kami definisikan di atas, yang turun dan mendekati nol.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
Apa berikutnya?
Contoh di atas diterapkan dalam basis kode kami di mana Anda dapat memilih dari agen lain juga, termasuk agen Neural epsilon-Greedy .