
זכויות יוצרים 2021 מחברי TF-Agents.
להתחיל
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה הוא מדריך שלב אחר שלב כיצד להשתמש בספריית TF-Agents לבעיות שודדים הקשריות שבהן לפעולות (זרועות) יש תכונות משלהן, כגון רשימת סרטים המיוצגים על ידי תכונות (ז'אנר, שנת יציאה, ...).
תְנַאִי מוּקדָם
ההנחה היא כי הקורא מכיר במקצת עם ספריית Bandit של סוכני TF, בפרט, עבד דרך ההדרכה עבור Bandits ב-סוכני TF לפני קריאת מדריך זה.
שודדים רב-זרועיים עם תכונות זרוע
בהגדרה "קלאסית" Contextual Multi-Armed Bandits, סוכן מקבל וקטור הקשר (הידוע גם בתצפית) בכל שלב בזמן ועליו לבחור מתוך קבוצה סופית של פעולות ממוספרות (זרועות) כדי למקסם את התגמול המצטבר שלו.
עכשיו שקול את התרחיש שבו סוכן ממליץ למשתמש על הסרט הבא לצפייה. בכל פעם שיש לקבל החלטה, הסוכן מקבל כהקשר מידע מסוים על המשתמש (היסטוריית צפייה, העדפת ז'אנר וכו'...), כמו גם את רשימת הסרטים לבחירה.
אנחנו יכולים לנסות לנסח את הבעיה הזו על ידי כך את פרטי המשתמש כהקשר וזרוע תהיינה movie_1, movie_2, ..., movie_K , אך גישה זו יש חסרונות רבים:
- מספר הפעולות יצטרך להיות כל הסרטים במערכת וזה מסורבל להוסיף סרט חדש.
- הסוכן צריך ללמוד מודל לכל סרט.
- דמיון בין סרטים אינו נלקח בחשבון.
במקום למספר את הסרטים, אנחנו יכולים לעשות משהו יותר אינטואיטיבי: אנחנו יכולים לייצג סרטים עם סט של תכונות כולל ז'אנר, אורך, צוות שחקנים, דירוג, שנה וכו'. היתרונות של גישה זו הם רבים:
- הכללה בין סרטים.
- הסוכן לומד רק פונקציית תגמול אחת שמדגמנת תגמול עם תכונות משתמש וסרטים.
- קל להסיר מהמערכת, או להציג סרטים חדשים למערכת.
בהגדרה החדשה הזו, מספר הפעולות אפילו לא חייב להיות זהה בכל שלב בזמן.
שודדים לכל זרוע ב-TF-Agents
חבילת TF-Agents Bandit פותחה כך שניתן להשתמש בה גם עבור התיק לכל זרוע. ישנן סביבות לכל זרוע, וגם רוב המדיניות והסוכנים יכולים לפעול במצב לכל זרוע.
לפני שאנחנו צוללים לתוך קידוד דוגמה, אנחנו צריכים את היבוא הדרוש.
הַתקָנָה
pip install tf-agents
יבוא
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
פרמטרים - אל תהסס לשחק
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
סביבה פשוטה לכל זרוע
סביבת סטוכסטיים הנייחת, הסביר האחרת ההדרכה , יש אתר מקביל לכל הזרוע.
כדי לאתחל את הסביבה לכל זרוע, יש להגדיר פונקציות שיוצרות
- אין פונקציות אלו פרמטרי קלט וליצור וקטור תכונה אחת (העולמי או לכל הזרוע) כאשר נקראו: הגלובליים ותכונות לכול זרוע.
- מתגמלת: פונקציה זו לוקחת כפרמטר בשרשור של גלובליים וקטור תכונה לכל זרוע, ומייצר כפרס. בעצם זו הפונקציה שהסוכן יצטרך "לנחש". כאן המקום לציין שבמקרה פר זרוע פונקציית התגמול זהה לכל זרוע. זהו הבדל מהותי ממקרה השודדים הקלאסי, שבו הסוכן צריך להעריך את פונקציות התגמול עבור כל זרוע באופן עצמאי.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
כעת אנו מצוידים לאתחל את הסביבה שלנו.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
להלן נוכל לבדוק מה מייצרת סביבה זו.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
אנו רואים שמפרט התצפית הוא מילון עם שני אלמנטים:
- אחת עם מפתח
'global': זהו החלק בהקשר הגלובלי, עם הצורה התאמת פרמטרGLOBAL_DIM. - אחת עם מפתח
'per_arm': וזהו ההקשר לכל זרוע, ואת צורתו היא[NUM_ACTIONS, PER_ARM_DIM]. חלק זה הוא מציין המיקום של תכונות הזרוע עבור כל זרוע בשלב זמן.
סוכן LinUCB
סוכן LinUCB מיישם את אלגוריתם Bandit בעל השם הזהה, אשר מעריך את הפרמטר של פונקציית התגמול הליניארית תוך שמירה על אליפסואיד ביטחון סביב האומדן. הסוכן בוחר את הזרוע בעלת התגמול הצפוי המשוער הגבוה ביותר, בהנחה שהפרמטר נמצא בתוך אליפסואיד הביטחון.
יצירת סוכן דורשת ידע של התצפית ומפרט הפעולה. כאשר הגדרת הסוכן, אנו קובעים את הפרמטר הבוליאני accepts_per_arm_features מוגדר True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
זרימת נתוני ההדרכה
סעיף זה נותן הצצה מוקדמת למכניקה של איך תכונות לכל זרוע עוברות מהמדיניות לאימון. אתה מוזמן לקפוץ לסעיף הבא (הגדרת מדד החרטה) ולחזור לכאן מאוחר יותר אם אתה מעוניין.
ראשית, הבה נסתכל על מפרט הנתונים בסוכן. training_data_spec התכונה של מציין הסוכן מה אלמנטים ולבנות את נתון ההכשרה צריכים.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
אם יש לנו מבט מקרוב אל observation חלק המפרט, אנו רואים כי הוא אינו מכיל תכונות לכל זרוע!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
מה קרה לתכונות לכל זרוע? כדי לענות על שאלה זו, הראשונה נציין כי כאשר הרכבות סוכן LinUCB, זה לא צריך את התכונות לכל זרוע של כל הזרועות, זה רק צרכים אלה של הזרוע שנבחר. לפיכך, זה הגיוני לוותר על המותח של צורה [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , כפי שהוא מאוד בזבזן, במיוחד אם את מספר הפעולות הוא גדול.
אבל עדיין, התכונות לכל זרוע של הזרוע הנבחרת חייבות להיות איפשהו! לשם כך, אנו מוודאים כי חנויות מדיניות LinUCB התכונות של הזרוע נבחר בתוך policy_info בתחום הנתונים הכשרה:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
אנו רואים מן הצורה כי chosen_arm_features שדה יש את וקטור התכונה היחידה של יד אחת, וכי יהיה הזרוע שנבחר. הערה כי policy_info , ואיתו chosen_arm_features , הוא חלק את הנתונים הכשרה, כפי שראינו לבדוק את המפרט נתונים אימונים, ובכך היא זמינה בשלב ההכשרה.
הגדרת מדד החרטה
לפני תחילת לולאת האימון, אנו מגדירים כמה פונקציות שירות שעוזרות לחשב את החרטה של הסוכן שלנו. פונקציות אלו מסייעות בקביעת התגמול הצפוי האופטימלי בהינתן מכלול הפעולות (הנתונות על ידי תכונות הזרוע שלהן) והפרמטר הליניארי המוסתר מהסוכן.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
עכשיו כולנו מוכנים להתחיל את לולאת אימוני השודדים שלנו. הנהג למטה דואג לבחירת פעולות באמצעות המדיניות, אחסון תגמולים של פעולות נבחרות במאגר החוזר, חישוב מדד החרטה שהוגדר מראש וביצוע שלב ההדרכה של הסוכן.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
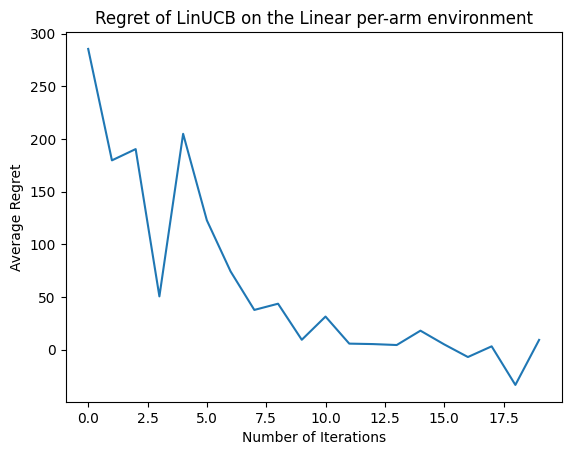
עכשיו בואו נראה את התוצאה. אם עשינו הכל נכון, הסוכן מסוגל להעריך היטב את תפקוד התגמול הליניארי, וכך הפוליסה יכולה לבחור פעולות שתגמולן הצפוי קרוב לזה של האופטימלי. זה מעיד על ידי מדד החרטה שהוגדר לעיל, שיורד ומתקרב לאפס.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
מה הלאה?
דוגמא הנ"ל מיושמת ב codebase שלנו שבו אתה יכול לבחור מתוך סוכנים אחרים גם כן, כולל סוכן אפסילון-חמדן העצבי .